目标:爬京东任意商品评论
一、首先打开京东任意商品的评论
1、我用的是QQ浏览器,右击检查,在Network下选择JS,在搜索框里输入productPageComments(如果出不来记得F5刷新一下)
如图:
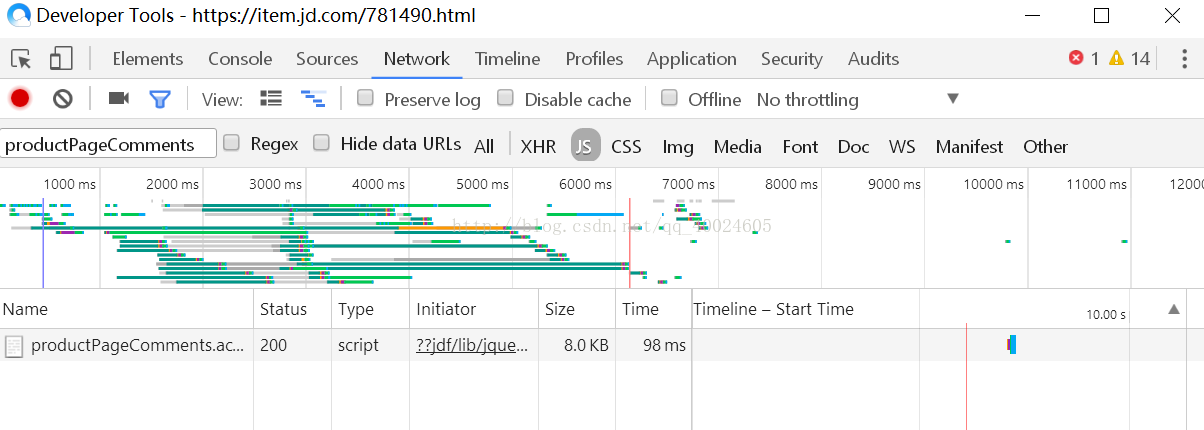
2、双击productPageComments会得到以下页面

评论就在其中啦
二、找到想要的东西就要写代码啦
上代码
# -*- coding:utf-8 -*- import urllib import json import sys reload(sys) sys.setdefaultencoding( "gbk" ) #注意编码 f=open("PL.txt","w+") def get_evaluate(url): #打开网页 page = urllib.urlopen(url).read().decode('gbk') page=page.replace('fetchJSON_comment98vv19563(','') #替换,也可以使用sub page=page.replace(');','') data = json.loads(page) #decode的过程,将json对象转换成python对象 for p in data["comments"]: #data是个字典,content是data的key值 content = p["content"].encode('utf-8') time = p["referenceTime"].encode('utf-8') name = p["referenceName"].encode('utf-8') f.write("评价内容"+'\n'+content+'\n'+"类型:"+name+'\n'+"评论时间:"+time+'\n') for i in range(0,10):#爬取一到十页的评论(可以自己任意设置) print("正在获取第{}页评论数据!".format(i+1)) url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv19' \ '563&productId=781490&score=0&sortType=5&page=' + str(i) +'0&pageSize=10&isShadowSku=0&fold=1' #注意URL的值
get_evaluate(url)
f.close
三、成果

然后写入文件的格式啊什么的,可以按自己的喜好改改