asp.net
神经网络
汽车
旅游
达梦数据库
最短路
分享功能
turtle
flink 最后一个窗口
端口号
数据统计
flyfish
mvc
update
程序员人生
computed
Lifecycle
GcPDF
图像像素点测量温度
TS工时表
xpath
2024/4/12 1:27:03
爬虫系列(九) xpath的基本使用
一、xpath 简介
究竟什么是 xpath 呢?简单来说,xpath 就是一种在 XML 文档中查找信息的语言
而 XML 文档就是由一系列节点构成的树,例如,下面是一份简单的 XML 文档:
<html><body><div><p>…

爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1、网页分析
(1)翻页
我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析,这里示例为《一出好戏》…

爬虫实战(一) 用Python爬取百度百科
最近博主遇到这样一个需求:当用户输入一个词语时,返回这个词语的解释
我的第一个想法是做一个数据库,把常用的词语和解释放到数据库里面,当用户查询时直接读取数据库结果
但是自己又没有心思做这样一个数据库,于是就…

爬虫实战(二) 用Python爬取网易云歌单
最近,博主喜欢上了听歌,但是又苦于找不到好音乐,于是就打算到网易云的歌单中逛逛
本着 “用技术改变生活” 的想法,于是便想着写一个爬虫爬取网易云的歌单,并按播放量自动进行排序
这篇文章,我们就来讲讲…
![xpath介绍 xpath使用 xpath常用函数 Chrome自动生成Xpath 表达式 [10分钟学会xpath]](https://img-blog.csdnimg.cn/20210119105250901.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NTU5ODUwNg==,size_16,color_FFFFFF,t_70)
xpath介绍 xpath使用 xpath常用函数 Chrome自动生成Xpath 表达式 [10分钟学会xpath]
Xpath 使用1.什么是Xpath2.Xptah解析原理3.如何安装Xpath4.如果使用Xpath5.Xpath 表达式5.Xpath 常用函数6.Chrome自动生成Xpath 表达式1.什么是Xpath
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。…

基于python获取网易云热门歌单及封面
先看一下图片背后的代码 非常好,里面歌单名字,id,以及封面图片都有了.在复制url的时候注意把/#删掉,要不然爬不了.
import requests
from lxml import etree
urlhttps://music.163.com/discover/playlist
head{user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleW…

XPath语法、轴、运算符-满满干货拿走不谢
🍁博主简介: 🏅云计算领域优质创作者 🏅2022年CSDN新星计划python赛道第一名 🏅2022年CSDN原力计划优质作者 🏅阿里云ACE认证高级工程师 🏅阿里云开发者社区专…
Python爬虫数据提取方式——使用xpath提取页面数据
xpath:跟re,bs4,pyquery一样,都是页面数据提取方法。xpath是根据元素的路径来查找页面元素。
安装lxml包:pip install lxml
HTML实例:
html """<div idcontent><ul classlist><li classone>One</li>…

程序员都是单身狗?我有一句……,不知当讲不当讲
程序员都是单身狗?我有一句……,不知当讲不当讲
程序员都是单身狗?我有一句:怎么可能!!!不存在的,程序员的套路你想象不到。。。 尽管大多网友认为程序员单身狗 但实际上,程序员们的处境 往往是站在“撒狗粮”的那一…

Selenium之Xpath VS CSS Selector
UI自动化测试常用的定位方式
driver.find_element_by_xpath()driver.find_element_by_css_selector()
两种定位方式比较:
xpath:代码量多,不易维护css_selector:代码量少,简单易维护 区别:
xpath可以直…
最新 Python3 爬取前程无忧招聘网 mysql和excel 保存数据
Python 爬虫目录 1、最新 Python3 爬取前程无忧招聘网 lxmlxpath 2、Python3 Mysql保存爬取的数据 正则 3、Python3 用requests 库 和 bs4 库 最新爬豆瓣电影Top250 4、Python Scrapy 爬取 前程无忧招聘网 5、Python3 爬取房…

Python 网络数据采集(四):Selenium 自动化
Python 网络数据采集(四):Selenium 自动化 前言一、背景知识Selenium 4Selenium WebDriver 二、Selenium WebDriver 的安装与配置2.1 下载 Chrome 浏览器的驱动程序2.2 配置环境变量三、Python 安装 Selenium四、页面元素定位4.1 选择浏览器开…
selenium之Xpath定位
一、什么是Xpath?
XPath(XML Path Language)是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。 由于HTML文档本身就是一个标准的XML页面,因此我们可以使用XPath的语法来定位页面元素。
二、…
selenium+requests获取52PK英雄联盟各英雄皮肤
简介 目标站点:https://lol.52pk.com/pifu/hero 实现方式:selenium进行图片信息获取并翻页,requests请求图片的url并保存图片到本地 Python实现
运行程序前,请先确认已经安装了requests、selenium第三方模块,并下载了…
【爬取音乐,并将音乐信息储存到数据库中】
爬取音乐,并将音乐信息储存到数据库中 确定音乐网站的url并分析网站分析二级页面创建数据库使用Xpath解析,进行多层爬取保存信息完整代码结果 确定音乐网站的url并分析网站 分析二级页面 创建数据库
# 创建一个链接对象
conn pymysql.connect(hostmaster, userroo…
一键抓取拉勾网跟boss直聘的招聘信息(常规操作,未借用Selenium这些)
笔者有话说:针对大多数电商类的望着那而言,其信息偷明度与时效性不言而喻,同样,他的反爬机制也相当到位,这里遇到的常见的反爬手段无非就是cookie跟refer字段,cookie动态加载的信息尤其的恶心,在不用selenium进行破解的时候,那过程简直了。。。(某直聘网站还定点封ip大…

实战自动化测试1:创建订单写的Python自动化
1、前言 公司的系统逐渐稳定,持续版本稳定,避免反复测试,浪费时间经历去回归测试。每次迭代测试节点过多且复杂,测试人员难于测试全面覆盖,引起一小部分bug问题。
2、示例
使用正式环境系统的下单页面 ①系统的操作需…

用Python分析上海的楼盘信息并进行数据可视化
文章目录前言运行结果分析网页拿到数据源码编程之外前言 好久不写爬虫了,深夜想买房 不~我不想。 我就是去看了一下上海的新楼盘信息,明白一个道理…“现在我买不起(╬ ̄皿 ̄)”! 算了算了。。。 运行结果
先看一下运行…
IntelliJ中的非JVM技术
Markdown:https://www.jetbrains.com/help/idea/markdown.html 支持CommonMark(定制Markdown标准),IntelliJ默认捆绑了Markdown插件,所以可以学学这个文章, 以便可以更好的在IntelliJ中使用Markdown。JSON&…
python 爬取豆瓣电影
import requests
from lxml import etree
import re
from bs4 import BeautifulSoup
import os
import time
import json
#解析数据
def parse(res):res_html etree.HTML(res)items res_html.xpath(//div[class"item"])datalist []#遍历封装数据,并返回…
![Xpath中关于//后[1]的索引问题详解](https://img-blog.csdnimg.cn/20201110151531731.png#pic_center)
Xpath中关于//后[1]的索引问题详解
Xpath中关于//的索引问题
在使用Xpath进行网络爬虫时,一直看到资料上写response.xpath(//a[class"xxx"][1]/href)这样的形式,经过测试发现 不加[1]与加了[1]的结果是一模一样的。
WTF??
经过网上查阅其他资料后发现&…
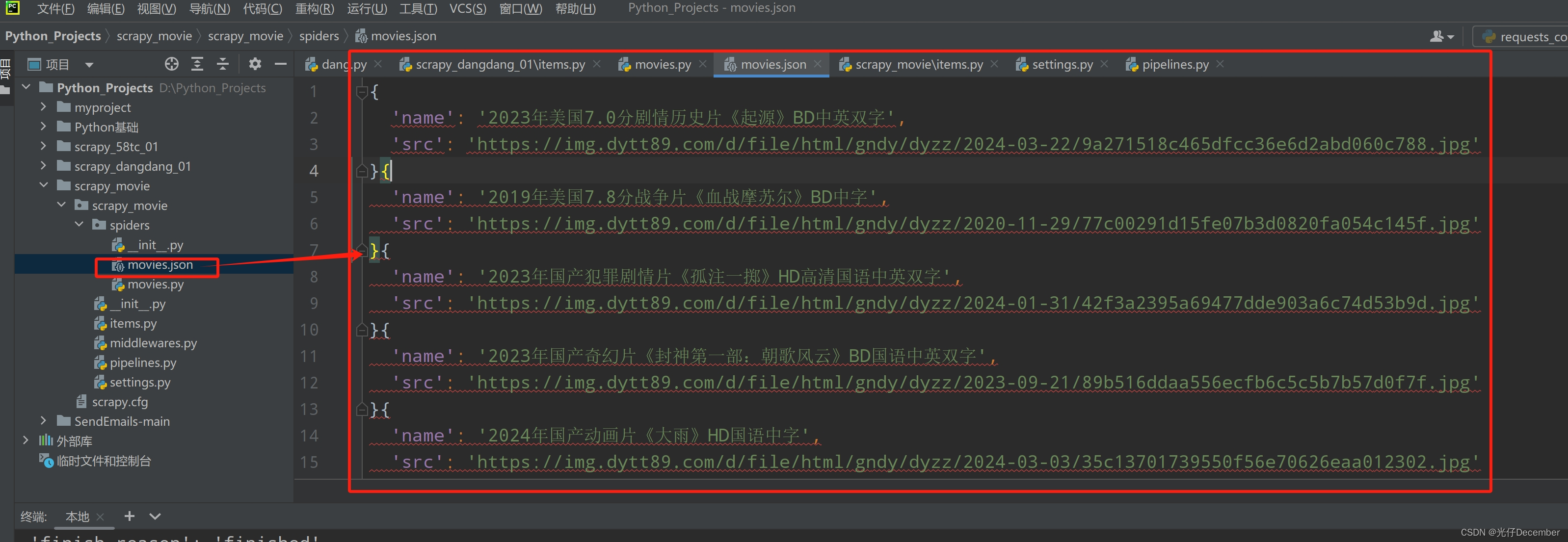
【Python从入门到进阶】51、电影天堂网站多页面下载实战
接上篇《50、当当网Scrapy项目实战(三)》 上一篇我们讲解了使用Scrapy框架在当当网抓取多页书籍数据的效果,本篇我们来抓取电影天堂网站的数据,同样采用Scrapy框架多页面下载的模式来实现。
一、抓取需求
打开电影天堂网站&…
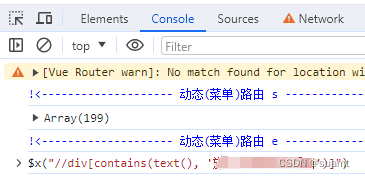
Selenium在vue框架下求生存
vue框架下面,没有id、没有name,vue帮开发做了很多脏活累活,却委屈了写页面自动化测试的人(当然,也给爬信息的也带来了一定的难处)。这里只能靠总结,用一些歪门邪道:
一、跟开发商量…

关于Javascript的Dojo包导入eclipse有错误Xpath is invalid in dojo library的处理方案
关于Javascript的Dojo包导入eclipse有错误Xpath is invalid in dojo library的处理方案: 描述: 利用jsp开发网站时导入Dojo包后,svg2gx.xml文件的<xsl:apply-templates select"&SupportedElements;">处报错误Xpath is in…
springboot中使用xpath
XPathExpression
参考:
https://docs.spring.io/spring-ws/site/apidocs/org/springframework/xml/xpath/XPathExpression.html
XPath
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的
<?xml ve…

Python爬虫——解析常用三大方式之Xpath
目录 Xpath
安装xpath
安装lxml库
导入lxml库
解析本地文件 etree.parse()
解析服务器响应文件 etree.HTML()
xpath基本语法
小案例:获取百度首页的百度一下
大案例:爬取站长素材图片
总结 Xpath
安装xpath 首先要学会安…
爬虫程序中Xpath的使用
在爬虫过程中有时要定位到某个标签、某个输入框等位置,需要在程序中捕捉到Xpath的信息
一般我们在写程序的时候也会打开网页一步一步查看细节
所以Xpath路径也是很重要的,以下是快速获取Xpath路径的方法:
F12进入查看网页源码的界面–>…

Xpath如何选择标签同级的文本
使用标签中的文本来选取元素,是xpath中屡试不爽的技巧,通过我们处理的这种标签的内层都会包含文字,举个例子: <div>CSDN</div>可以用//div[contains(string(), "CSDN")]或者//div[contains(text(), "C…
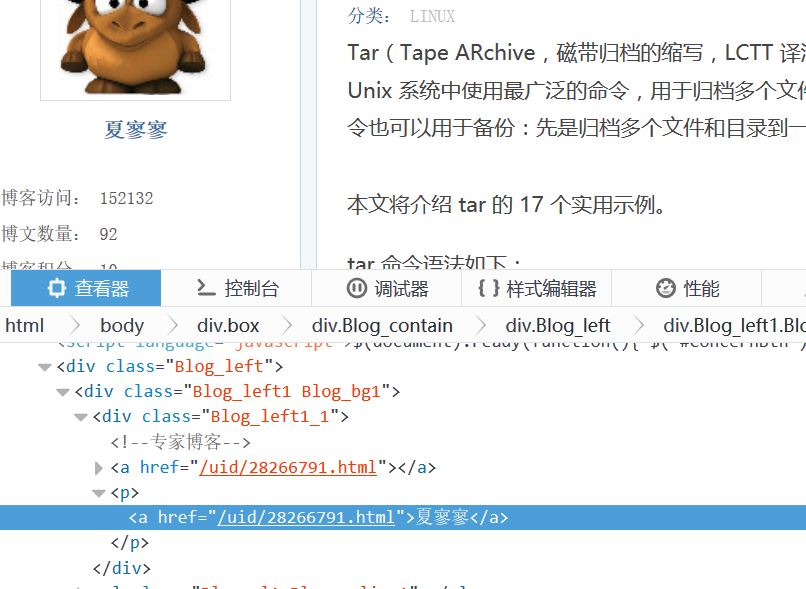
解决:xpath取出指定多标签内所有文字text
Python 2.7 Pycharm 5.0.3 问题 再写一个markdown自动引用的小脚本的时候新出现的问题,也就是利用xpath取出字符串的问题,记录一下 取出如下字符串 我要取出mrlevo520的内容,怎么取呢,很多方法,bs4也可以,…

利用正则表达式, xpath, Beautifulsoup来解析网页
1 使用正则表达式的时候需要导入re模块,这个是python自带的模块,不用下载
1.1正则表达式有许多常用的规则 这里要注意贪婪匹配和非贪婪匹配以及反斜杠转义的问题 1.2 匹配网页的时候有时候要考虑到换行和大小写的问题 遇到匹配换行时要使用修饰符r…
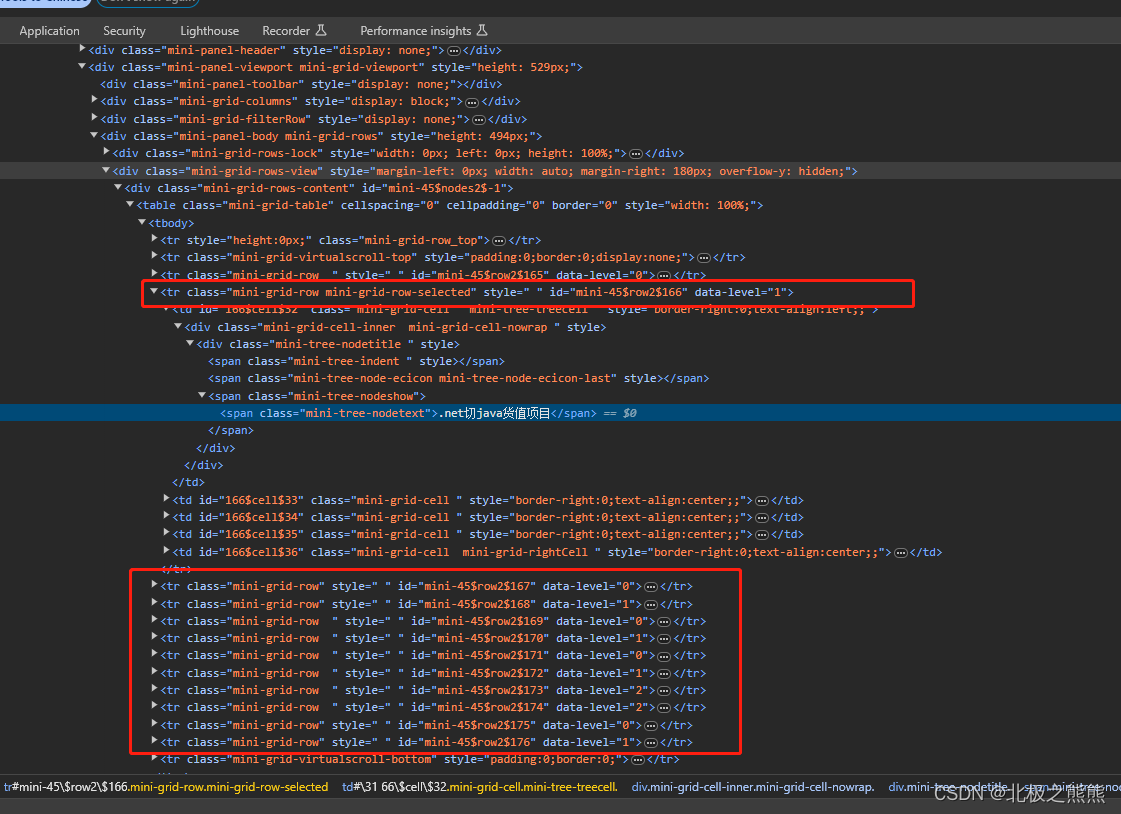
UI自动化Selenium 元素定位之Xpath
一、元素定位方式
selenium中定位元素,通常有几种方式:
1、通过id定位:By.ID
2、通过Name定位:By.Name
3、通过元素其他属性定位,如class、type、text文本。。。。。。等等,如果要用属性定位那就需要使…

XPath学习笔记---2(特殊用法)
文章转自:http://blog.csdn.net/skyeyesxy/article/details/50838003 概要: XPath的介绍与配置XPath的使用XPath的特殊用法Python并行化 1.XPath的介绍与配置 官方名称:XML路径语言(XMLpathlanguage)用来确定xml文档中某部分位置的语言&#…

6-爬虫-scrapy解析数据(使用css选择器解析数据、xpath 解析数据)、 配置文件
1 scrapy解析数据 1.1 使用css选择器解析数据 1.2 xpath 解析数据
2 配置文件 3 整站爬取博客–》爬取详情–》数据传递
scrapy 爬虫框架补充
# 1 打码平台---》破解验证码-数字字母:ddddocr-计算题,滑块,成语。。。-云打码,超…
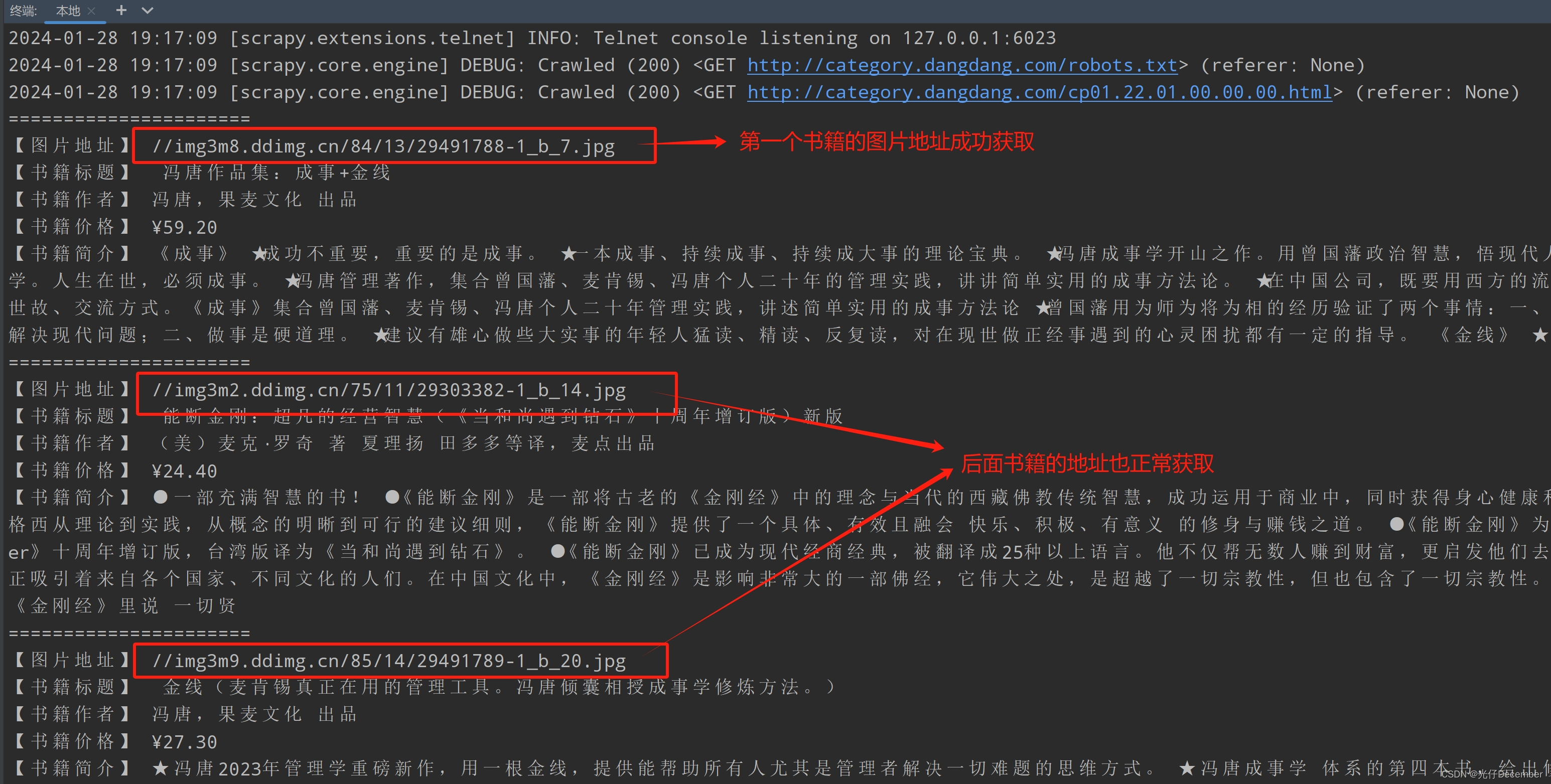
【Python从入门到进阶】48、当当网Scrapy项目实战(一)
接上篇《47、Scrapy Shell的了解与应用》 上一篇我们学习了Scrapy终端命令行工具Scrapy Shell,并了解了它是如何帮助我们更好的调试爬虫程序的。本篇我们将正式开启一个Scrapy爬虫项目的实战,对当当网进行剖析和抓取。
一、当当网介绍
当当网成立于199…
使用lxml解析本地html文件报错?
场景说明
使用 lxml 中的 parse 方法读取本地 html 文件报错,遇到这种问题该怎么解决呢?
from lxml import etreeresponse etree.parse(test.html)
tr_list response.xpath(//table[class"list-table"]/tbody/tr[not(id)][position()>1…

Python 爬虫必杀技:XPath
小伙伴、大伙伴们,大家好~今天要给大家介绍的是Python 爬虫必杀技:XPath。
1. 简介 一提到网络爬虫,就不得不提到Xpath Helper,我们常常用它来对所要提取的文本内容进行定位。除了这一利器外,了解Xpath定位的原理及其…
JAVA XML Dom4j XPATH的运用
使用前请先导入Dom4j和XPATH的jar包 Dom4j:https://pan.baidu.com/s/1c16QTzU XPATH:http://pan.baidu.com/s/1jIdiLaY
XPATH的作用:可以更加简洁高效的访问xml中的标签内容。 例如要获取如下代码的标签的内容,可以使用XPATH语句“Store/a/b/c/d”配合XPATH的特定函数实现…


Xpath : 使用部分属性值模糊匹配来定位页面元素
//定位以 “ http://v ” 开头的linkList<WebElement> startLink driver.findElements(By.xpath("//a[starts-with(href,http://v)]"));//定位id含有 “ i ” linkList<WebElement> containLink driver.findElements(By.xpath("//a[contains(id,i…

爬虫入门指南(1):学习爬虫的基础知识和技巧
文章目录 爬虫基础知识什么是爬虫?爬虫的工作原理爬虫的应用领域 爬虫准备工作安装Python安装必要的库和工具 网页解析与XPath网页结构与标签CSS选择器与XPathXpath 语法XPath的基本表达式:XPath的谓语(Predicate):XPa…
selenium用法
一、请求库selenium
selenium是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题。操作浏览器模拟人的行为。
下载浏览器驱动:以谷歌浏览器为例---->谷歌浏览器驱动(版本号对应)
…
selenium定位详解
# 跳转到最新窗口
driver.switch_to.window(driver.window_handles[-1])# 跳转到iframe,属性id,name,class均可
driver.switch_to.frame("passport_iframe")# 根据class属性定位
driver.find_element(By.CLASS_NAME, "toolbar-btn-loginfun").c…
xpath 骚操作清单
一、xpath不匹配含有指定子节点或属性的节点
1. 不匹配含有指定子节点的节点
如,不匹配子节点含有 ‘i’ 节点的 ‘p’ 节点
xpath(//p[not(i)])2. 不匹配含有指定属性的节点
如,不匹配子节点含有 ‘class’ 属性的 ‘p’ 节点
xpath(//p[not(class…
Xpath当前节点寻找父节点下的子节点
HTML的结构如下:
<section class"AutoTest"><a title"xpath" href"#"></a><div style"#">webdriver ui auto Test !</div>
</section>
我们首先需要获取title”xpath…
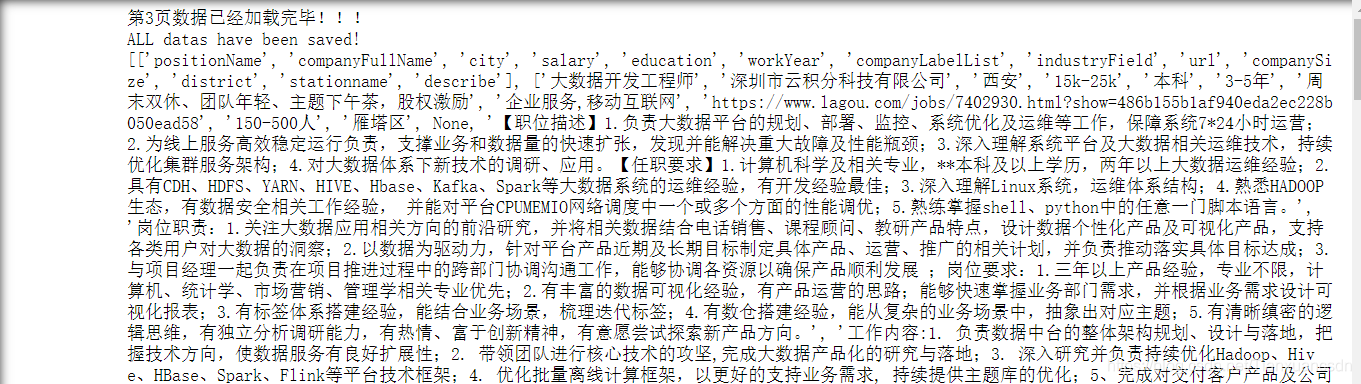
获取拉勾网30页所有信息的常规方法 VS selenium
笔者有话说:大家也都知道拉勾网此类的电商网站反爬一向恶心,笔者通过半天时间的研究试用了两种方法之后,得出了两个结论(包括一个貌似可行的cokie秘密) 首先是常规方法 import requests
from lxml import etree
import random
from multiprocessing.dummy

爬取简书ajxs动态化数据并存储到ecxel中!
爬取简书ajxs动态化数据并存储到ecxel中! # -*- coding: utf-8 -*-
"""
Created on Tue Nov 17 10:30:23 2020author: Yuka
"""网址为https://www.jianshu.com/u/9104ebf5e177,爬取内容为简书用户的最新评论中的评论题目、…

改良获取股票吧评论一次一万条
1.自己弄了几个稳定的ip代理,一个ip代理池
import re
import xlwt
from urllib import parse
import requests
from lxml import etree
import random
def main():import timestart_time time.time()b 0columns [网址, 作者, 发布时间, 标题, 内容, 阅读量, 评论…
Python 滚动点击爬虫
# -*-coding:UTF-8 -*-
import json
from selenium import webdriver
from lxml import etree
import time
import re# 滚动加载
def height_All():#每隔0.5秒刷新一次SCROLL_PAUSE_TIME 0.5last_height driver.execute_script("return document.body.scrollHeight"…

爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1、网页分析
(1)分析 URL 规律
我们首先使用 Chrome 浏览器打开 豆瓣电影 Top250,很容易可以判断出网站是一个静态网页
然后我…

Python处理异步加载的虎扑网站浏览数 (时间戳的构建)
笔者有话说:爬取虎扑网站浏览数时,本以为只是一个平平无奇的动态加载,没想到用selenium抓取依然如此,后面才发现,这是一个异步加载…ajakx
发现这个小秘密后,唯一的问题就是tid后面的字段是啥,…

web自动化使用xpath轴定位
目录
XPath 轴(Axes)
一、定义:轴可定义相对于当前节点的节点集。
二、语法:
一、ancestor 选取当前节点的所有先辈(父,祖父等)
二、ancestor-or-self: 选取当前节点的所有先辈(父、祖父等…
![Selenium2 入门[1] —— 获取XPath来定位元素 : Frebug , FirePath 插件的安装及使用](https://img-blog.csdn.net/20160713142422635?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
Selenium2 入门[1] —— 获取XPath来定位元素 : Frebug , FirePath 插件的安装及使用
1. Firefox插件安装 Firebug: https://addons.mozilla.org/en-US/firefox/addon/firebug/Firepath: https://addons.mozilla.org/en-US/firefox/addon/firepath/ [1] 先安装Firebug,重启Firefox,再安装FirePath[2] 安装完成之后…
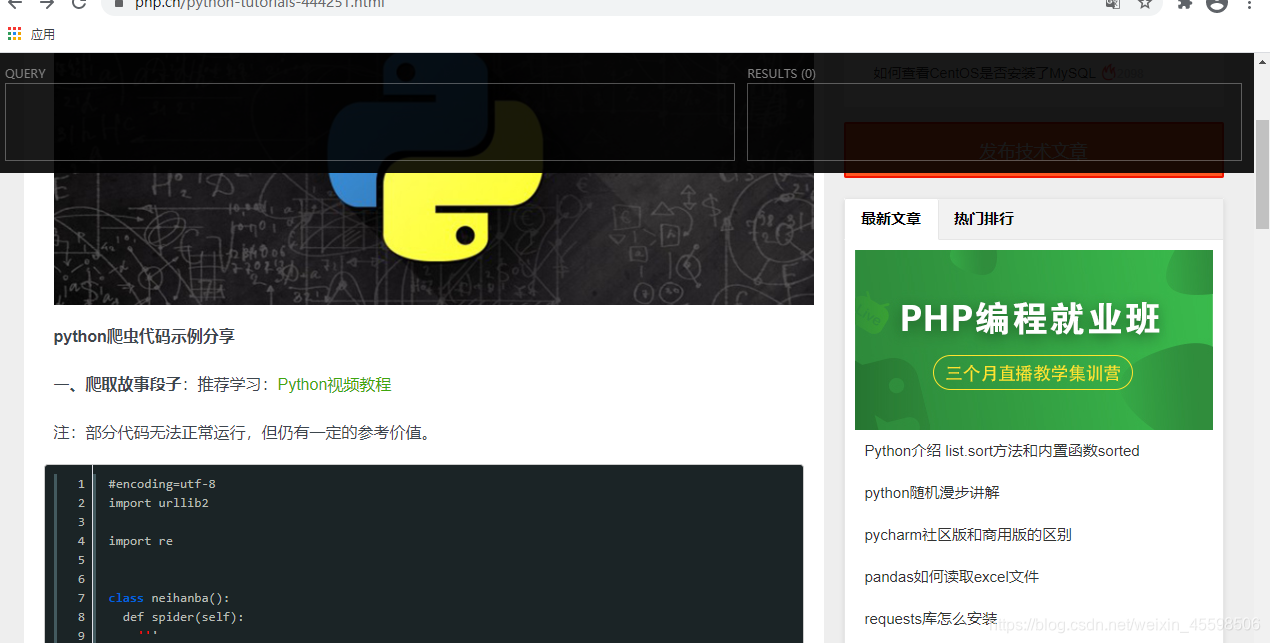
2021 XPath Helper安装 使用
1.打开google 商店 2.搜索xpath helper 3.点击第一个 详情页 添加至Chrome 4.关闭 Chrome 5.重新打开 6.ctrlshiftx 快捷键调出

简历自动化抓取,一键get百份求职简历
这次我们就来聊一聊实用性比较高的爬虫案例:简历自动化抓取,一键get百份求职简历。 本次爬取非常顺利,本以为会遇到几个反爬措施,除了定位遇到几个小坑之外,其余地方皆是一帆风顺,值得提一下的地方主要就是下载链接的随机抓取,会更好的具有拟态磨合从而使效率略高(本来…
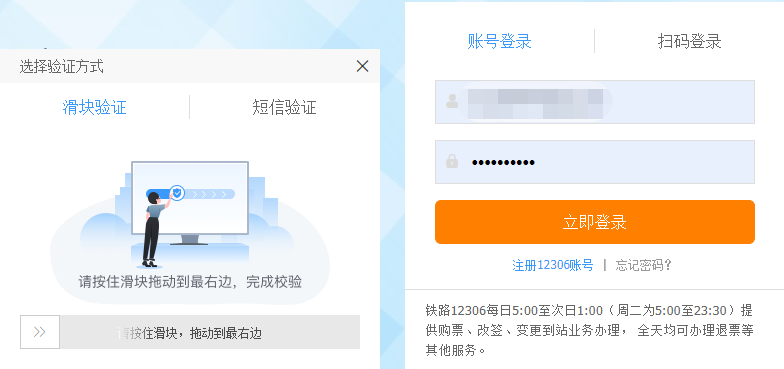
4-爬虫-selenium(等待元素加载、元素操作、操作浏览器执行js、切换选项卡、前进后退异常处理)、xpath、动作链
1 selenium等待元素加载 2 selenium元素操作 3 selenium操作浏览器执行js 4 selenium切换选项卡 5 selenium前进后退异常处理 6 登录cnblogs 7 抽屉半自动点赞 8 xpath 9 动作链 10 自动登录12306
上节回顾
# 1 bs4 解析库---》xml(html)-遍历文档树-属性 文本 标签名-搜索文…
python万字博文教你玩嗨selenium库,建议收藏!
python万字博文教你玩嗨selenium库,建议收藏! 文章目录python万字博文教你玩嗨selenium库,建议收藏!首先安装插件基本用法无界面模式运行,后台运行标签定位方法根据标签的id属性进行定位根据标签的name属性进行定位根据…
8.爬取动态数据——模拟浏览器(Selenium入门到实战)
目录
一、模拟浏览器的环境准备
1.Selenium简介
2.Selenium安装
3.安装WebDriver
(1)安装chromedriver

Python3 爬取房价 采用lxml + xpath
Python 爬虫目录 1、最新 Python3 爬取前程无忧招聘网 lxmlxpath 2、Python3 Mysql保存爬取的数据 正则 3、Python3 用requests 库 和 bs4 库 最新爬豆瓣电影Top250 4、Python Scrapy 爬取 前程无忧招聘网 5、Python3 爬取房…

python爬取网易云歌曲高清封面
以哪里都是你这首歌举例子吧 https://music.163.com/#/song?id488249475 首先定位一下歌曲专辑的位置 用xpath定位可写成 //meta[16]/content 如果不想自己数用xpath的筛选器帮忙也可以 用xpath定位可写成 //img/data-src 但运行程序后发现并没有得到数据,后来上网查了下发现…
爬取百度图片中关于‘beauty‘的图片,要求至少爬取50张图片
#笔者有话说###:本次爬取纯粹为了完成作业,毫无坑点,兴致缺缺,而且如果尼康过笔者之前的博客就应该发现了,图片抓取一直都是笔者老深长谈的话题,而本次也的确抓取了一个很有意思的网站“pexels”画质也相当之高,但是并非使用常规手段,可以说是笔者使用selenium做的第一…

分分钟避坑抓取 安居客 住房信息,并存储到CSV跟XlSX中去.........
温馨提示:报错了就百分之九十九是网址需要手动验证,就请移步去点击验证啦!(这里用了csv跟xsxl两种保存方式,任选其一即可!)
# -*- coding: utf-8 -*-
"""
Created on Tue Oct 27 18:27:21 2020@author: Yuka利用Lxml库,爬取前10页的信息,具体信息如下…
利用XPATH快速抓取起点小说全本小说并存储到excel中
快速抓取起点小说全本小说并存储到excel中
测试写入EXCEL方法
import xlwt
book = xlwt.Workbook(encoding=utf-8)
sheet = book.add_sheet(sheet1)
sheet.write(0,0,python
爬取安居客房租信息并存储到mysql数据库中
本次抓取主要是数据库存储之一块需要进行命令操作,python操作mysql还是比较香的。
conn = pymysql.connect(host=localhost, user=root, passwd=123456, db=hyj, port=3306, charset=
Xpath dom4j解析带有命名空间的XML的方法
目录 网络上其他人的招数:
我的大招的优势:
直接放大招: 网络上其他人的招数:
dom4j xpath解析带有命名空间XML的四种方(zhao)法(shi)

Python XPath解析html出现â解决方法 html出现#123;解决方法
前言
爬网页又遇到一个坑,老是出现乱码,查看html出现的是&#数字;这样的。
网上相关的“Python字符中出现&#的解决办法”又没有很好的解决,自己继续冲浪,费了一番功夫解决了。
这算是又加深了一下我对这些iso、Unicode编…
iOS XML数据解析
前言
最近公司的活比较少,空闲时间十分多,遍寻思着写一款APP。在这个过程中便有使用到XML数据,于是研究了一下。
目前写的这个是本地阅读软件,后续会把在写这个APP用到的技术以及遇到的问题都整理出来,通过博客的形式…
scrapy简记之抓取小说示例
scrapy 网络爬虫核心工作 通过网络向指定的 URL 发送请求,获取服务器响应内容使用某种技术(如正则表达式、XPath 等)提取页面中我们感兴趣的信息高效地识别响应页面中的链接信息,分析这些链接递归执行此处介绍的第 1、2、3 步使用…
xpath在爬虫中的使用
xpath的语法:
路径查询// 查找所有的子孙节点,不考虑层级。 / 找直接子节点 ./a/href 当前路径 ../span/text() 父级下的span的文本内容 /* 任意一个子节点 //* 任意的子孙节点
谓语查询//div[id] 查找包含所有id属性的div节点 //div[idmaincont…
【实用 Python 库】使用 XPath 与 lxml 模块在 Python 中高效解析 XML 与 HTML
在今天的信息时代,数据无处不在,从网络爬虫到数据挖掘,从文本处理到数据分析,我们时常需要从结构化文档中提取有用的信息。XPath 是一门强大的查询语言,它可以在 XML 与 HTML 等文档中定位特定的元素与数据。而在 Pyth…
利用 JDK 自带的 Document + XPath 解析 XML
利用 JDK 自带的 Document XPath 解析 XML,记录一下 准备工作 inventory.dtd 和 inventory.xml 文件 dtd 中的 PCDATA 的意思是被解析的字符数据(parsed character data)。可把字符数据想象为 XML 元素的开始标签与结束标签之间的文本。PCDA…
xpath选择器应用
文章目录xpath选择器应用xpath介绍xpath语法表达式逻辑语句 and orxpath函数xpath提取元素在scrapy项目中使用xpathlxml直接使用 xpathxpath选择器应用
xpath介绍
XPath(XML Path Language - XML路径语言),它是一种用来确定XML文档中某部分…

Scrapy与分布式开发(2.3):lxml+xpath基本指令和提取方法详解
lxmlxpath基本指令和提取方法详解
一、XPath简介
XPath,全称为XML Path Language,是一种在XML文档中查找信息的语言。它允许用户通过简单的路径表达式在XML文档中进行导航。XPath不仅适用于XML,还常用于处理HTML文档。
二、基本指令和提取…

XPath判断当前选中节点的元素类型 Python lxml判断当前Element的元素类型 爬虫爬取页面分元素类型提取纯文本
背景&前言
不知道你们做爬虫的时候,有没有碰到和我一样的情况:将页面提取成纯文本的时候,由于页面中各种链接、加粗字体等,直接提取会造成结果一坨一坨的,非常不规整。有时候还要自己对标题等元素进行修改&#x…
xpath的表达式以及用法
接下来为大家分享以下xpath的表达式以及用法。
一.选取节点
Xpath使用路径表达式在XML文档中选取节点。节点是通过沿着路径来选取的,通过路径可以找到我们想要的节点或者节点范围。 表达式 描述 用法 说明 nodename 选取此节点的所有子节点。 xpath(‘span’) 选取span…

scrapy爬虫框架使用介绍建议收藏
定义: 异步处理框架,可配置和可扩展程度非常高,Python 中使用最广泛的爬虫框架 重点来说一下scrapy的五大组件:
Scrapy框架五大组件 【1】引擎(Engine)----------整个框架核心 【2】爬虫程序(Spider)-----…

web自动化测试第17步:深入xpath元素定位详解
一、xpath高级用法基础格式
格式 /轴方法::标签名[标签属性]实例 //div/parent::span[name‘interName’]实例解释: 定位span标签,span标签是div标签的父级,且span标签的name属性值为:interlNmae
二、基础格式详解
2.1层级路径…
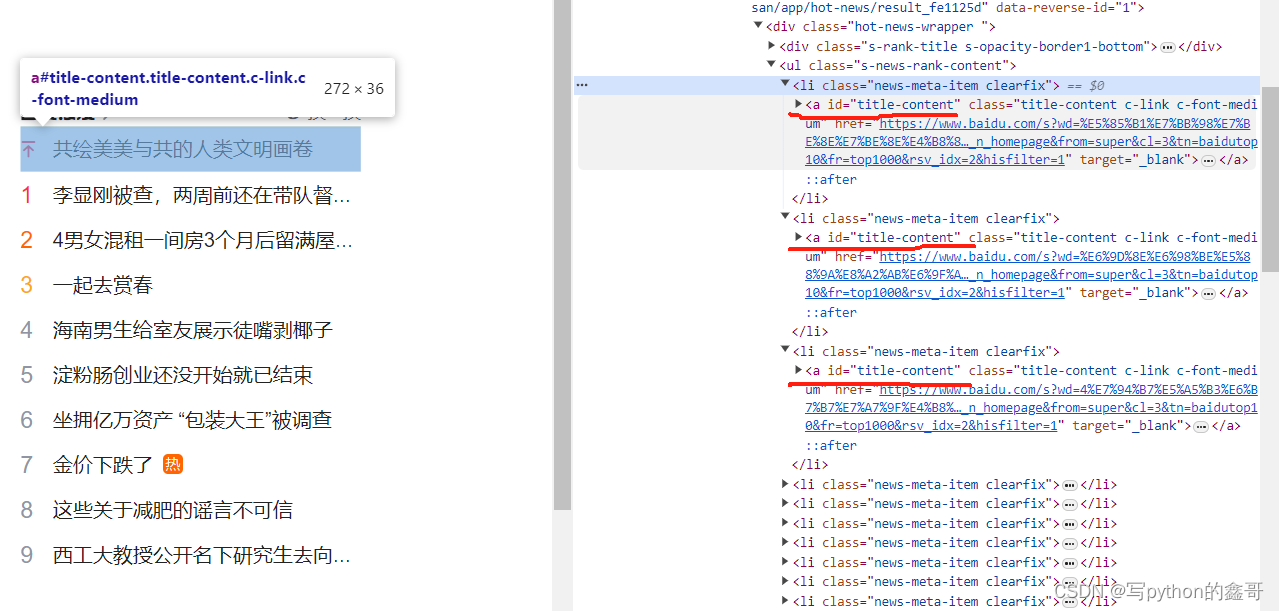
如何用Selenium通过Xpath,精准定位到“多个相同属性值以及多个相同元素”中的目标属性值
前言 本文是该专栏的第21篇,后面会持续分享python爬虫干货知识,记得关注。
相信很多同学,都有使用selenium来写爬虫项目或者自动化页面操作项目。同样,也相信很多同学在使用selenium来定位目标元素的时候,或多或少遇见到这样的情况,就是用Xpath定位目标元素的时候,页面…
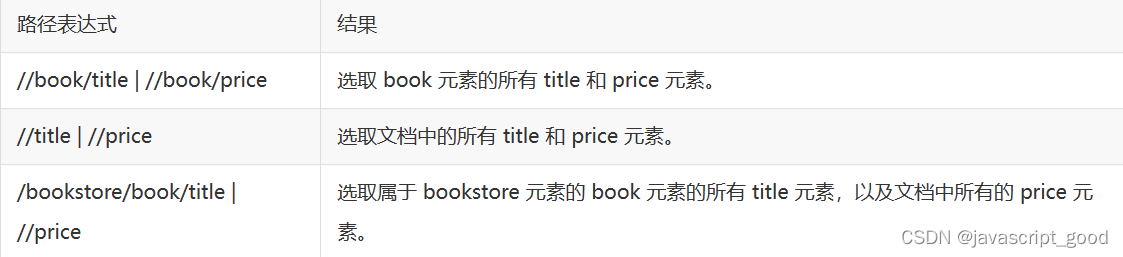
非结构化数据之XPath学习
1、XPath语法
XPath 是一门在 XML 文档中查找信息的语言。 XPath 可用来在 XML 文档中对元素和属性进行遍历。
<?xml version"1.0" encoding"ISO-8859-1"?>
<bookstore>
<book><title lang"eng">Harry Potter</t…
Xpath—解决问题的良药
何为良药? 由于在XML中存在一些问题和缺陷,针对这些问题就产生了响应的解决方案。如:
getElementById方法在解析XML时由于一些原因适不适合的: 首先XML中每个元素节点不一定有id属性。 其次XML中的两个元素节点可能有相同的id属性…
『python爬虫』xpath变化导致无法找到指定元素(持续更新中~)
目录 xpath变化的原因1. 语言设置2. 窗口大小n. 待添加~总结 欢迎关注 『python爬虫』 专栏,持续更新中 欢迎关注 『python爬虫』 专栏,持续更新中 xpath变化的原因
XPath 可能会出现变化的原因有很多,以下是一些常见的情况: 网页…

自动化爬虫seleium获取tianyancha数据
1.seleium进入tianyancha
2.代码 import xlwt
from selenium import webdriverfrom selenium.webdriver.common.keys import Keys
import timecolumns [公司名称,法定代表人,统一社会信用代码,营业期限,公司类型,参保人数,曾用名,注册地址,经营范围,经营状态,成立日期,注册资…
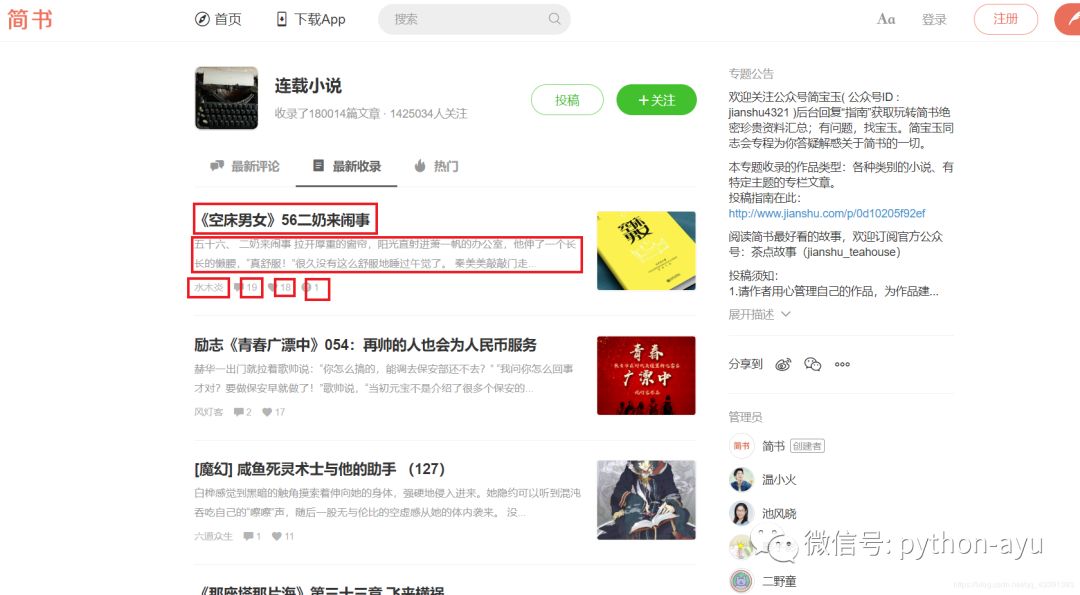
Scrapy入门实例2:爬取简书网热门专题信息(动态网页,双重Ajax接口)
目标,用Scrapy爬取每个专题的前十篇文章的概要信息。1.先在主网页抓取所有的详细页面的href进行拼接2.进入详细页面提取信息值得注意的是主网页和详细页面都是动态网页,都是Ajax加载的,不过规律很容易被发现,在谷歌开发者工具观察…
playwright下载及基本使用
playwright下载及基本使用 1. 下载playwright库2. playwright使用2.1导入库2.2 基本使用 3.XPATH元素定位方法3.1 xpath定位语法3.2 相关操作 4. 等待及缓存4.1 等待操作4.2 添加缓存 1. 下载playwright库
pip install playwright1.33.0
playwright install 2. playwright使用…
Python中使用Xpath
XPath在Python的爬虫学习中,起着举足轻重的地位,对比正则表达式 re两者可以完成同样的工作,实现的功能也差不多,但XPath明显比re具有优势,在网页分析上使re退居二线。
XPath介绍: 是什么? 全称…
【Python从入门到进阶】46、58同城Scrapy项目案例介绍
接上篇《45、Scrapy框架核心组件介绍》 上一篇我们学习了Scrapy框架的核心组件的使用。本篇我们进入实战第一篇,以58同城的Scrapy项目案例,结合实际再次巩固一下项目结构以及代码逻辑的用法。
一、案例网站介绍
58同城是一个生活服务类平台,…

Web爬虫|入门教程解析库lxml+XPth选择器
网络爬虫开发实战源码:https://github.com/MakerChen66/Python3Spider 原创不易,本文禁止抄袭、转载,多年爬虫实战开发经验总结,侵权必究! 目录一、XPth引入二、XPth使用2.1 XPth概览2.2 XPath常用规则2.3 安装三、XPt…
【爬虫】Xpath和CSS信息提取的方法异同点
类似点:
Xpath与css都有web页面定位元素的功能Xpath与css结构类似
区别:
1. Xpath比较强大,而css选择器在性能上更优,运行速度更快,语法更简洁 CSS再chrome,火狐查找速度快,效率高࿰…

C#处理HTML格式字符串获取需要的字段
首先第一步
需要先下载NuGet包
第二步
下载完成后在命名空间引用该包
第三步
var htmlDoc new HtmlDocument();htmlDoc.LoadHtml(str);var name htmlDoc.DocumentNode.SelectNodes("xpath").Innertextxpath知识点总结 XPath使用路径表达式来选取XML文档中的…
【工作记录】xpath语法笔记
XPath概述
XPath(XML Path Language)是一门解析XML文档的语言,可在XML文档中对元素和属性进行遍历,被广泛用于解析HTML文档数据。
在HTML文档中XPath通过元素(即HTML标签)和属性(即HTML标签的属性)对元素进行定位和查找。
XPath语法总结
格式功能描述…
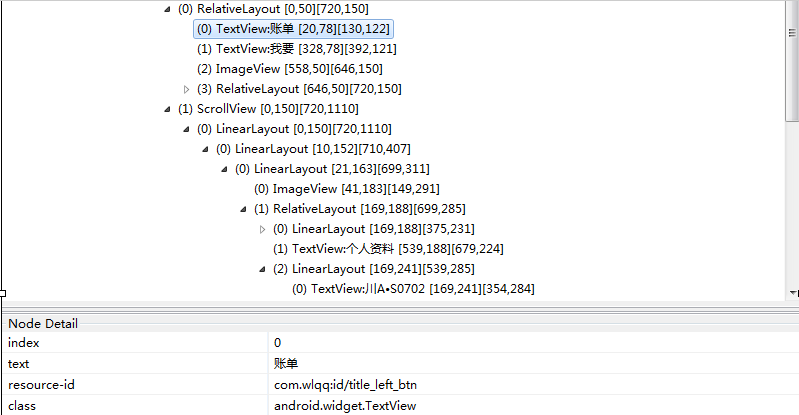
移动端关于xpath定位问题及常用方法
关于xpath定位问题及常用方法
先放一个图: A,先说说不用xpath的场景,一般是用于存在id或者name。可能没有看到name,别慌,继续看。 1,app上面定位用的最多的当然是id,也就是上面看到的resource-id,后面就是其所对应的值。所以在定位的时候可以是driver.find_element_by_…
利用xpath提取xml文档数据
之所以要引入xpath的概念,目的就是为了在匹配xml文档结构树时能够准确地找到某一个节点元素。可以把xpath比作文件管理路径:通过文件管理路径,可以按照一定的规则查找所需要的文件;同样,依据xpath所制定的规则…

用python爬取去哪儿游记攻略为十月假期做准备。。。爬虫之路,永无止境!
用python爬取去哪儿游记攻略为十月假期做准备。。。爬虫之路,永无止境!
热热闹闹的开学季又来了,小伙伴们又可以在一起玩耍了,不对是在一起学习了,哈哈。 再过几周就是国庆假期,想想还是很激动的…
解析神器PK,花落谁家?Jsoup Or Xpath?
[b][colorgreen][sizelarge]
今天简单测了下使用Jsoup和Xpath解析XML的文件的方便程度,两者都可以完成解析,提取特定的元素或节点内容,但明显Jsoup更胜一筹,我们都知道Xpath是专业的xml结构化文档的查询语言,虽然语法功…
xpath提取xml文档数据
public class Demo4 {public static void main(String[] args) throws Exception {SAXReader reader new SAXReader();Document document reader.read(new File("src/book.xml"));String value document.selectSingleNode("//作者").getText();System.o…

02-1解析xpath
我是在edge浏览器中安装的xpath,需要安装的朋友可以参考下面这篇博客最新版edge浏览器中安装xpath插件
一、xpathd的使用
安装lxml
pip install lxml ‐i https://pypi.douban.com/simple导入lxml.etree
from lxml import etreeetree.parse() 解析本地文件
htm…

XPath - 快速入门使用 - 配案例测试
文章目录1. 在线测试 - 推荐的这个在线匹配网站的比较准确2. 概述3. 语法3.1 基础语法概述3.2 测试应用3.2.1 节点 - 从根节点找子节点(不可找孙子起点)3.2.2 / - 初始起点 - 当前节点为标准3.2.3 // - 在当前节点范围内的任意位置3.2.4 . - 当前节点3.2…
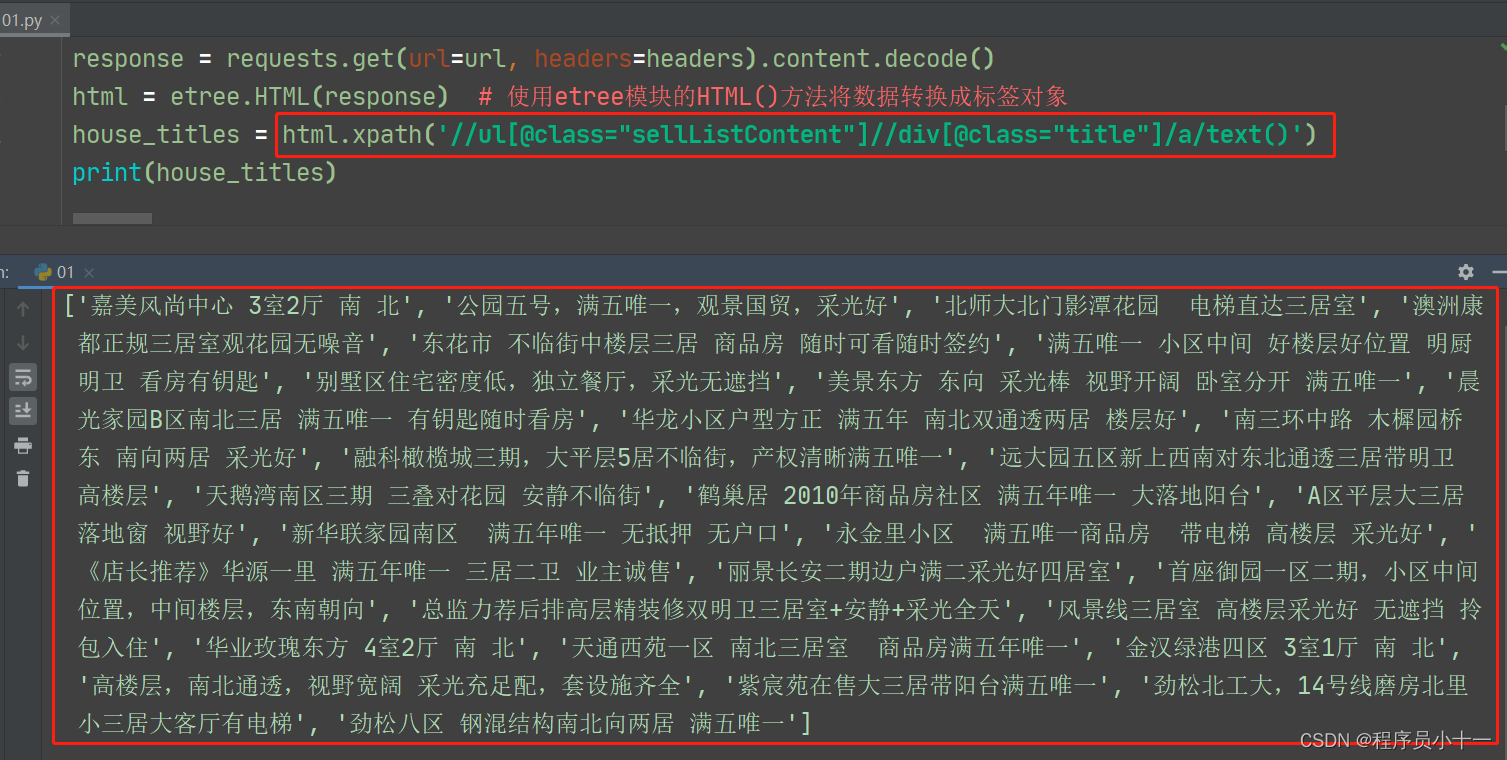
Python爬虫解析工具之xpath使用详解
文章目录 一、数据解析方式二、xpath介绍三、环境安装1. 插件安装2. 依赖库安装 四、xpath语法五、xpath语法在Python代码中的使用 一、数据解析方式
爬虫抓取到整个页面数据之后,我们需要从中提取出有价值的数据,无用的过滤掉。这个过程称为数据解析&a…

爬虫使用xpath解析时返回为空,获取不到相应的元素的原因和解决办法
在写爬虫的时候解析网页,使用最多的解析方式就是xpath解析,但是在使用在使用xpath解析的时候,明明自己写的xpath语句正确,但是返回值还是为空 原因通常是前端做的一些反爬措施,在编写网页的时候通常省略一层标签&#…

Python 网络爬虫(三):XPath 基础知识
《Python入门核心技术》专栏总目录・点这里 文章目录 1. XPath简介2. XPath语法2.1 选择节点2.2 路径分隔符2.3 谓语2.4 节点关系2.5 运算符 3. 节点3.1 元素节点(Element Node)3.2 属性节点(Attribute Node)3.3 文本节点…