vue
面试题
注记
装饰器模式
自动化
密码学
zabbix
云计算
CMake
cloud alibaba
r语言
编程
模板
gaussdb
敖丙
startup packet
管理微信小程序登录态
session_key
集成测试
期末考试
urllib
2024/4/13 12:15:09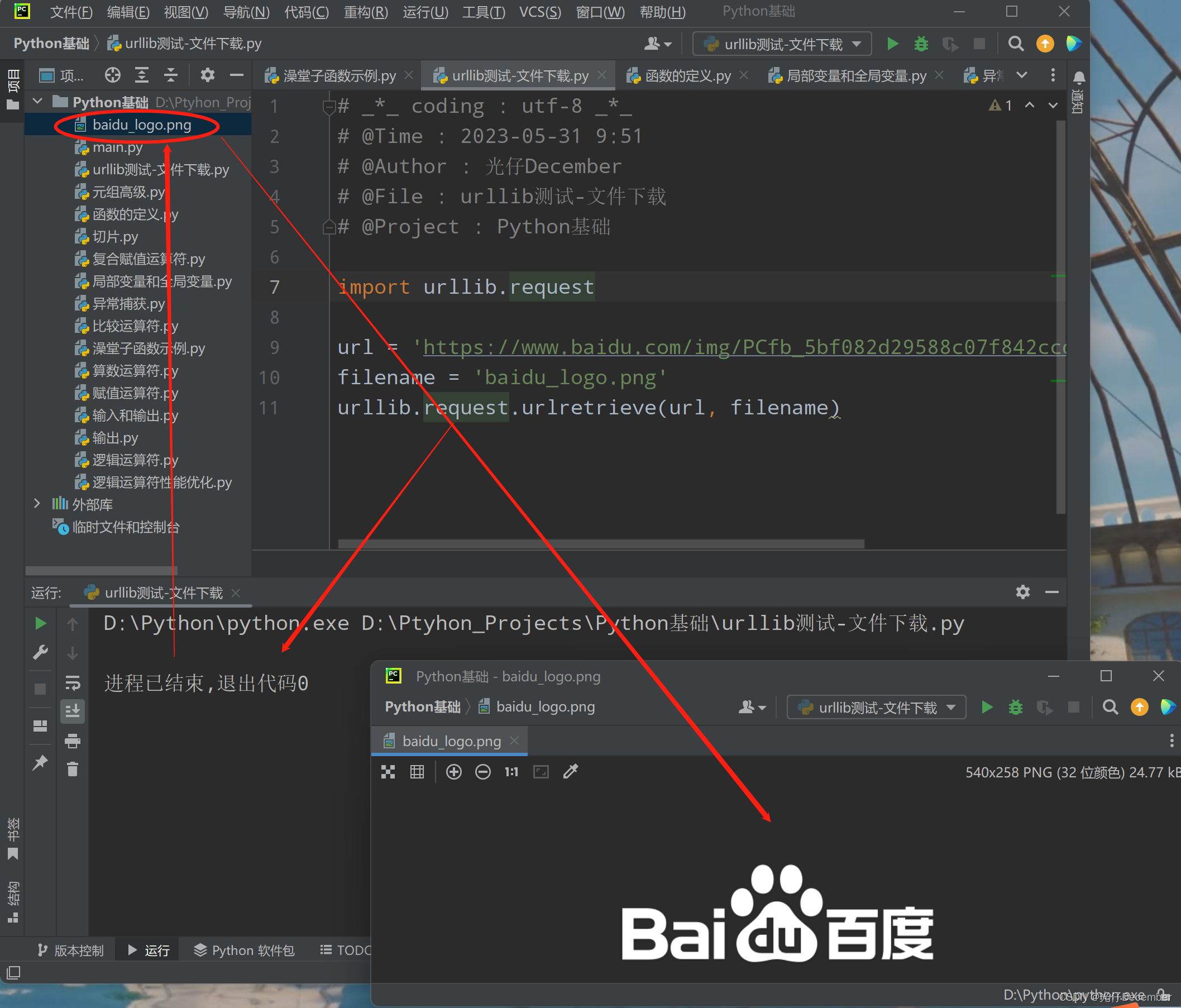
【Python从入门到进阶】22、urllib库基本使用
接上篇《21、爬虫相关概念介绍》 上一篇我们介绍了爬虫的相关概念,本篇我们来介绍一下用Python实现爬虫的必备基础,urllib库的学习。
一、Python库的概念
我们今后的学习可能需要用到很多python库(library),及引用其…

Python 高级(一):HTTP 请求与响应(urllib 模块)
大家好,我是水滴~~
本篇文章主要介绍 Python 的 urllib 模块,主要内容有:urllib库的基本使用、使用 urllib.request 模块获取网页内容及下载文件、使用 urllib.parse 解析 URL 地址、使用 urllib.error 模块处理请求异常、使用 urllib.robot…
Python中关于URL的处理(基于Python2.7版本)
参考官方文档:https://docs.python.org/3/library/urllib.html点击打开链接
1、 完整的url语法格式: 协议://用户名密码:子域名.域名.顶级域名:端口号/目录/文件名.文件后缀?参数值#标识
2 、urlparse模块对url的处理方法 urlparse模块对url的主要处理…

【网络爬虫】(1) 网络请求,urllib库介绍
各位同学好,今天开始和各位分享一下python网络爬虫技巧,从基本的函数开始,到项目实战。那我们开始吧。
1. 基本概念
这里简单介绍一下后续学习中需要掌握的概念。
(1)http 和 https 协议。http是超文本传输…
python-爬虫-urllib
网络爬虫(Web Crawler),又叫网络蜘蛛、网络机器人,是一种自动化数据采集程序
数据采集 → 数据处理 → 数据存储
常见的工作流程如下: 1.定义采集的目标(网站、APP、公众号、小程序)ÿ…
【Python从入门到进阶】40、requests的基本使用
接上篇《39、使用Selenium自动验证滑块登录》 上一篇我们介绍了使用selenium进行滑块自动验证操作。本篇我们结束selenium的章节,来学习requests库的基本使用。
一、requests与urllib的爱恨情仇
1、requests与urllib的区别
大家在前面的学习中,访问网…
【小沐学Python】网络爬虫之urllib
文章目录 1、简介2、功能介绍2.1 urllib库和requests库2.2 urllib库的模块2.2.1 urllib.request2.2.2 urllib.error2.2.3 urllib.parse2.2.4 urllib.robotparser 2.3 入门示例 3、代码示例3.1 urlib 获取网页(1)3.2 urlib 获取网页(2) with header3.3 urllib post请求 4、urlli…

使用webdriver+urllib下载哈哈网所有图片
上次刚刚用webdriver拔取了最近看的小说,并下载到了本地,但是心里并不满足,于是就想下载笑话网站上的图片,由于自动化测试用的selenium库里的webdriver能比较准确的定位元素,并且获取元素的属性,
webdrive…
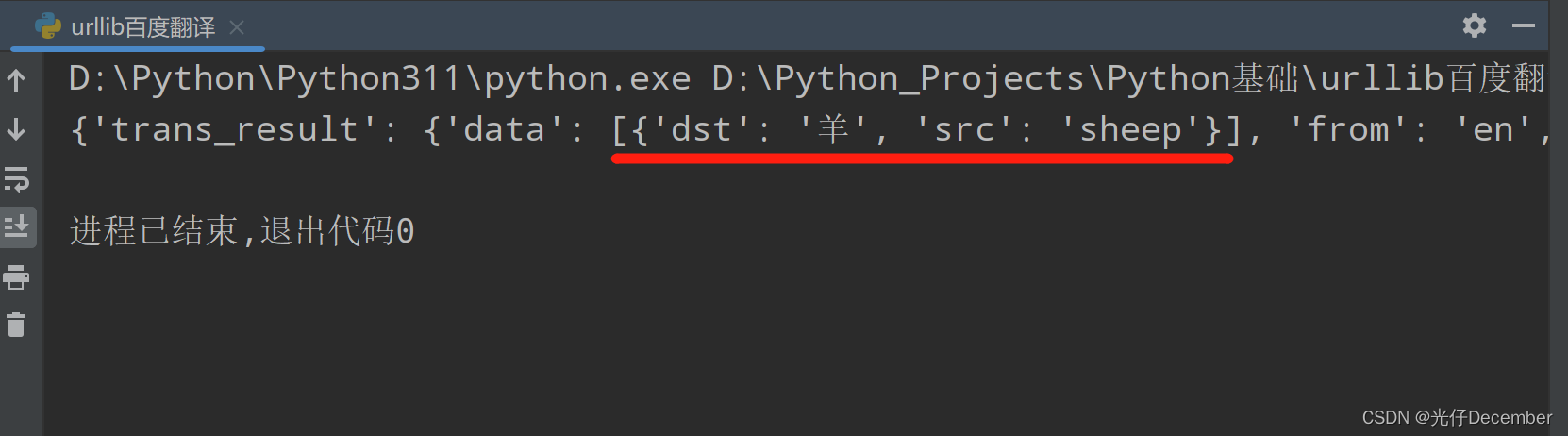
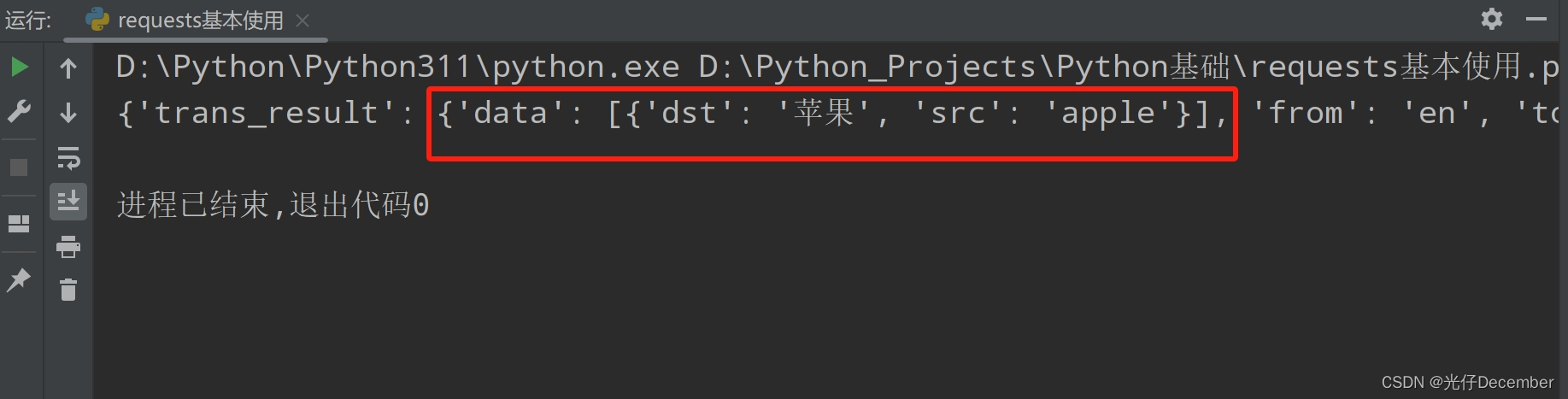
【Python从入门到进阶】23.urllib使用post请求百度翻译
接上篇《22、urllib库基本使用》 上一篇我们介绍了实现爬虫的必备基础——urllib库的学习。本篇我们来使用urllib实现百度翻译的效果。
一、在线翻译服务
当我们需要翻译一段文字时,百度翻译是一个很常用的工具。它是由百度公司开发的一款在线翻译服务,…

Python抓取数据并存入到mysql
#!/usr/bin/env python#coding:utf-8Created on Jul 21, 2013author: belongimport urllibimport reimport datetimeimport MySQLdbimport timestart_url "https://xively.com/search?qtemperature&category"工具类class Tools:def write_log(self, level, inf…

爬虫实战(一) 用Python爬取百度百科
最近博主遇到这样一个需求:当用户输入一个词语时,返回这个词语的解释
我的第一个想法是做一个数据库,把常用的词语和解释放到数据库里面,当用户查询时直接读取数据库结果
但是自己又没有心思做这样一个数据库,于是就…

Python 初步了解urllib库:网络请求的利器
目录
urllib库简介
request模块
parse模块
error模块
response模块
读取响应内容
获取响应状态码
获取响应头部信息
处理重定向
关闭响应
总结 在Python的众多库中,urllib库是一个专门用于处理网络请求的强大工具。urllib库提供了多种方法来打开和读取UR…
python3 urllib调用spring cloud服务报urllib.error.HTTPError: HTTP Error 400: Bad Request排查
背景
使用python3的urllib调用spring cloud服务接口,一直报错 File "E:\github\workspace\dbfree\src\test\common\test_paas_api_base.py", line 49, in test_zjkresp urllib.request.urlopen(req, timeout5)File "C:\Users\zhangjikuan\AppData\…
python httplib urllib urllib2区别(一撇)
目录:
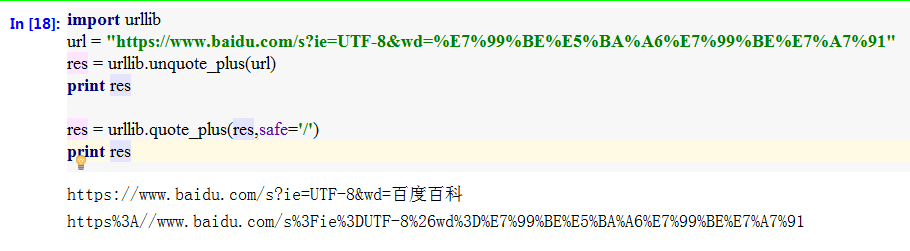
urlencode & quote & unquote (url 中带中文参数)
python httplib urllib urllib2区别(一撇)
python post请求实例 & json -- str互相转化(application/x-www-form-urlencoded \ multipart/form-data&…
【Python爬虫开发基础⑦】urllib库的基本使用
专栏:python网络爬虫从基础到实战 欢迎订阅!后面的内容会越来越有意思~ 往期推荐: 【Python爬虫开发基础①】Python基础(变量及其命名规范) 【Python爬虫开发基础②】Python基础(正则表达式) 【…
【小沐学Python】网络爬虫之requests
文章目录 1、简介2、requests方法2.1 get2.2 post 3、requests响应信息4、requests的get方法4.1 url4.2 headers4.3 params4.4 proxies4.5 verify4.6 timeout4.7 cookies4.8 身份验证 3、测试代码3.1 获取网页HTML(get)3.2 获取网页HTML(带he…
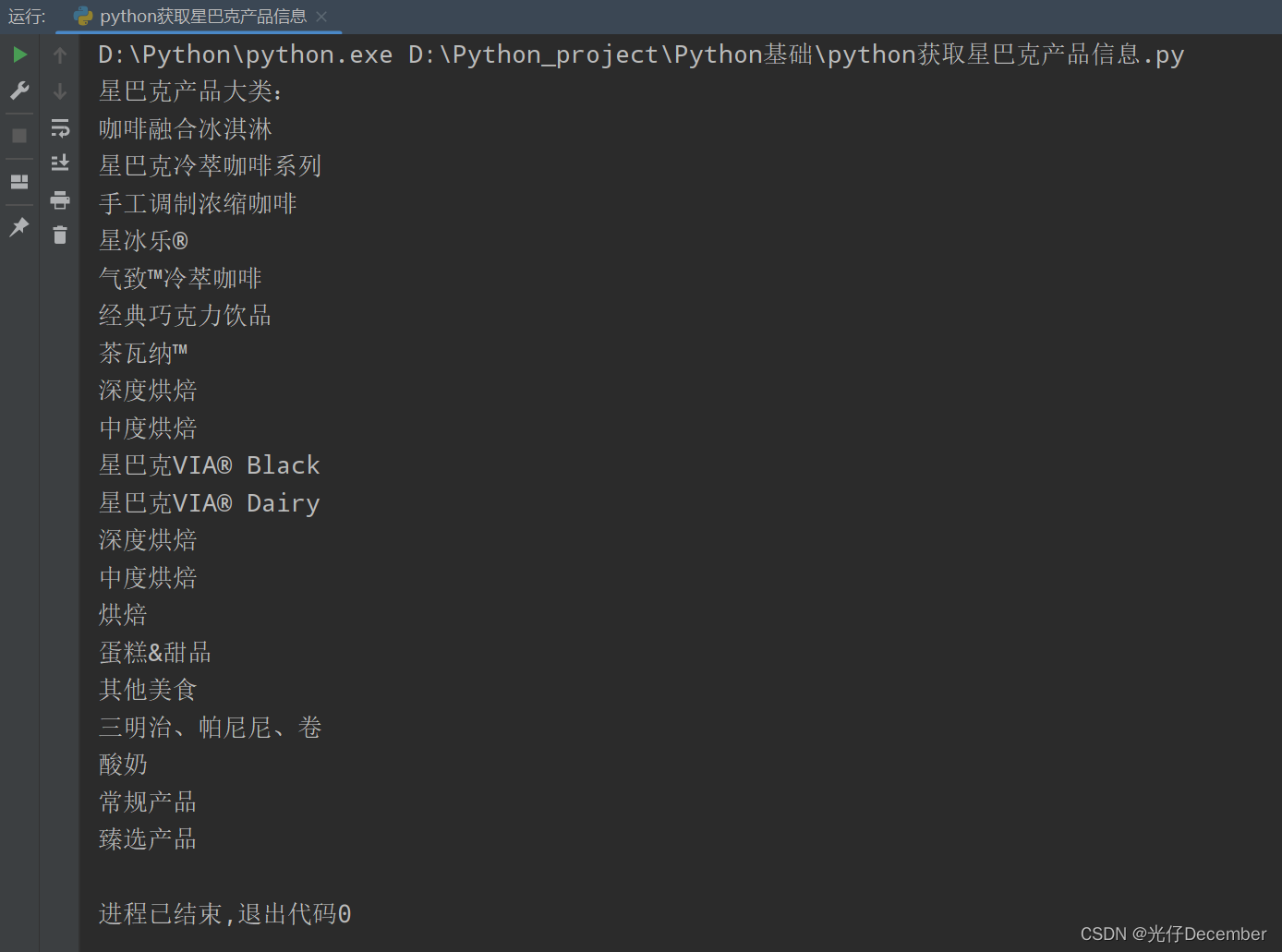
【Python从入门到进阶】33、使用bs4获取星巴克产品信息
接上篇《32、bs4的基本使用》 上一篇我们介绍了BeautifulSoup的基本概念,以及bs4的基本使用,本篇我们来使用bs4来解析星巴克网站,获取其产品信息。
一、星巴克网站介绍 星巴克官网是星巴克公司的官方网站,用于提供关于星巴克咖啡…
python——python3.x使用urllib模块下载文件
语法(只简单介绍使用) urllib.request.urlretrieve(url, filenameNone, reporthookNone, dataNone) 其中,url为下载网址,filename为存储路径
【sample】以下载luna16数据集中annotations.csv文件为例
In [1]: import urllib
In [2]: urllib.re…
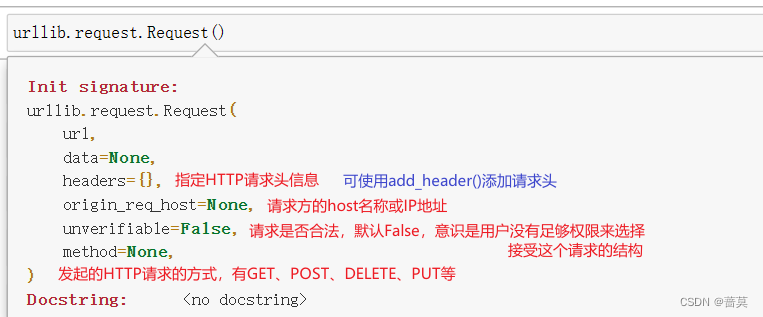
Python10-使用urllib模块处理URL
Python10-使用urllib模块处理URL 1.url库说明2.urllib.request2.1urlopen2.2urlretrieve2.3Request2.4示例 3.urllib.parse3.1urlparse3.2urlunparse3.3urlencode3.4quote3.5unquote3.6示例 1.url库说明
urllib 是 Python 标准库中的一个模块,提供了用于处理 URL&a…
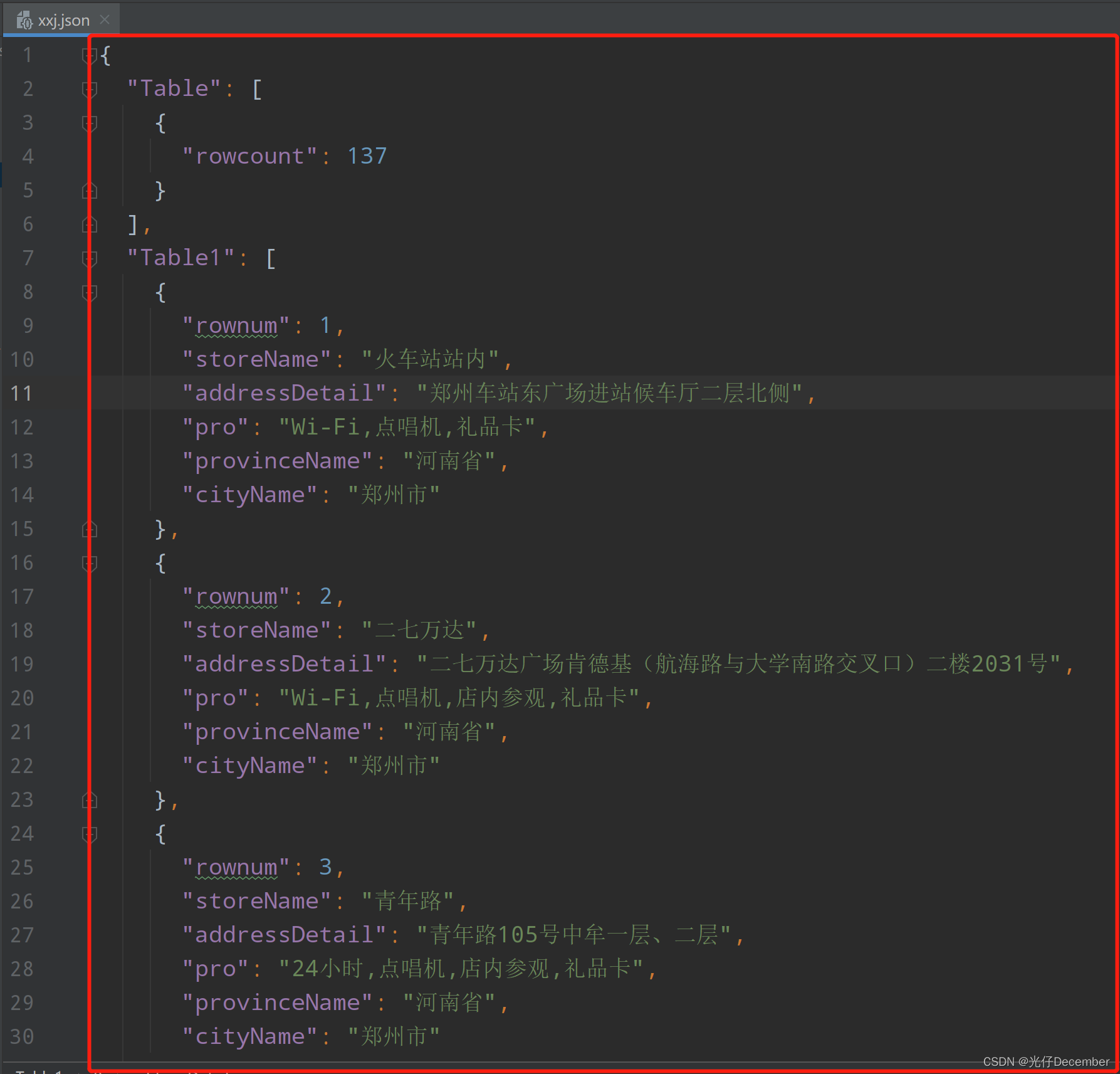
【Python从入门到进阶】25、urllib获取快餐网站店铺数据
接上篇《24、urllib获取网站电影排行》 上一篇我们讲解了如何使用urllib的get请求抓取某某电影排行榜信息。本篇我们来讲解如何使用urllib的post请求抓取某某快餐网站店铺数据。
一、某某快餐网站介绍
1、某某快餐网站
某某快餐店网址为:http://www.kfc.com.cn/k…
爬虫系列(三) urllib的基本使用
一、urllib 简介
urllib 是 Python3 中自带的 HTTP 请求库,无需复杂的安装过程即可正常使用,十分适合爬虫入门
urllib 中包含四个模块,分别是
request:请求处理模块parse:URL 处理模块error:异常处理模块…

爬虫系列(六) 用urllib和re爬取百度贴吧
这篇文章我们将使用 urllib 和 re 模块爬取百度贴吧,并使用三种文件格式存储数据,下面先贴上效果图 1、网页分析
(1)准备工作
首先我们使用 Chrome 浏览器打开 百度贴吧,在输入栏中输入关键字进行搜索,这…
Python学习之网页抓取(一)
这一篇实现的功能是:抓取匹配正则表达式的网址,并下载到本地 #!/usr/bin/env python# -*- coding: GBK -*-import urllibimport restart_url "http://www.baidu.com"#获取网站内所有链接def get_url(url):html urllib.urlopen(url)pattern …