区块链
知识图谱
企业微信
SDRAM
汇编
cocos2dx-lua
实时音视频
HuggingFace
科研绘图
Exchanger
嵌入式linux
django-redis
软件考试
前沿技术
鹈鹕优化算法(POA)
BFC
默认浏览器
EFR32
应用现代化
大学生志愿者
爬取
2024/4/24 17:47:30

Python爬虫 | 爬取全书网小说斗罗大陆
网络爬虫:可以理解成网页蜘蛛,在网页上采集数据
爬取流程:
1、导入模块
2、打开网页,获取原码
3、获取章节原码
4、获取正文
5、过滤‘杂质’
6、保存下载 废话不多说开始爬!!!
今天爬…

java解析html
目录 场景描述一.引入依赖二.调用接口响应回来的html三.测试代码 场景描述 我调用外部接口,但是返回来的数据是html的格式,所以我就需要进行处理来获得我想要的数据。我使用的是jsoup。 一.引入依赖
<dependency><groupId>org.jsoup</gr…
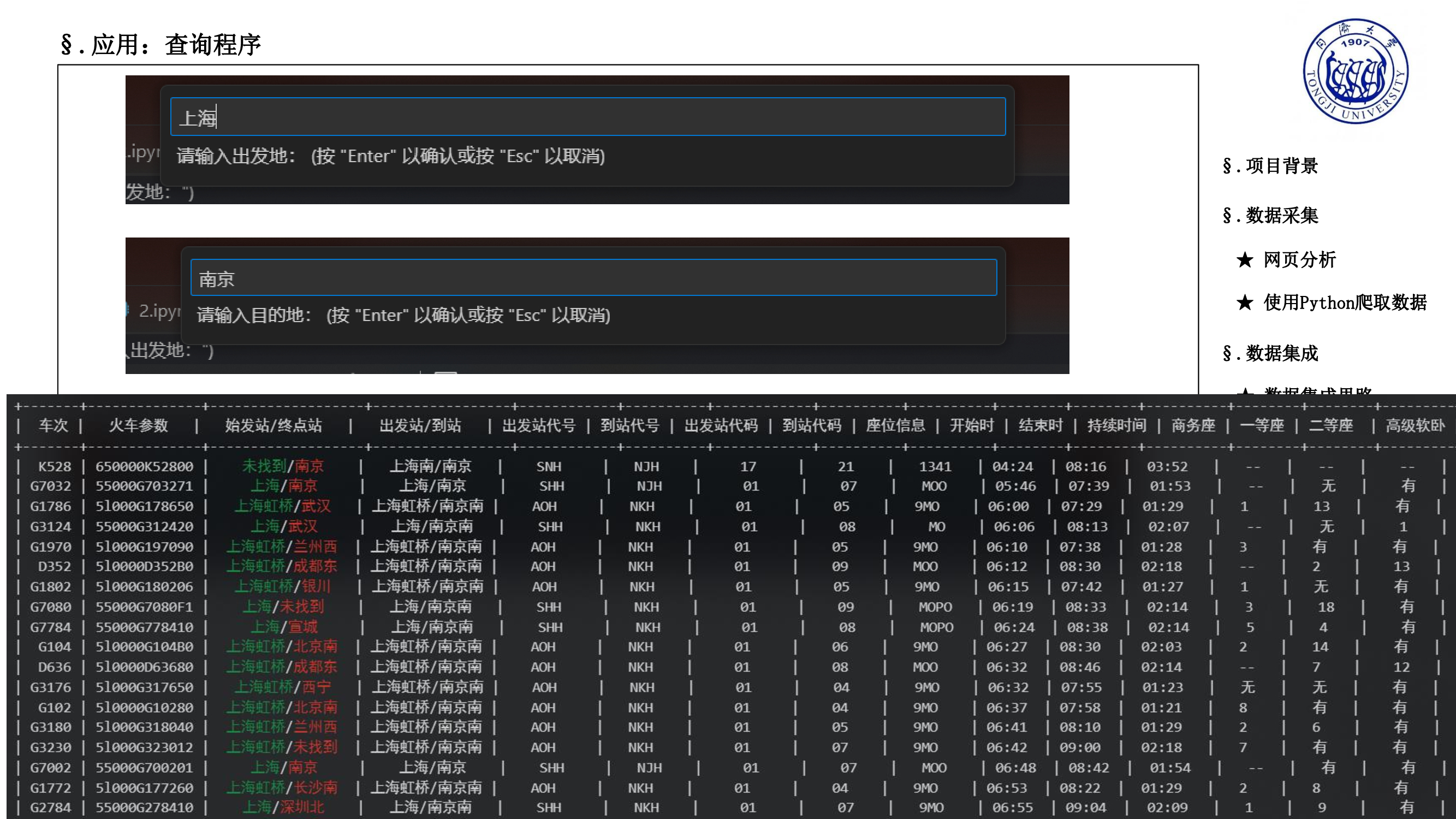
【项目分享】RailTracker: 火车票务数据采集与分析
🚄 RailTracker: 高铁票务数据采集与可视化 🌟
从12306使用爬虫爬取火车站及车次信息、火车票价
项目地址:https://github.com/Zhu-Shatong/RailTracker 点击链接前往项目 通过本项目,我们将带领访问者手把手完成火车票数据采集…