数据结构
人工智能
数据湖
Drawable
硬件工程
WinLicense
python考级
gerapy
交友
Cartographer
2022
GPT-3
基本指令
自回归
前沿技术
信号完整性
API接口开发系列
dmidecode
比较运算符
摄像头
find_all
2024/4/25 22:05:13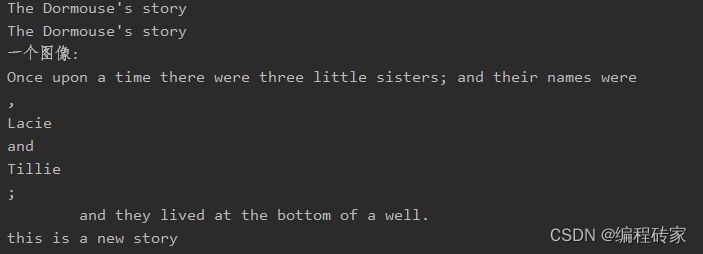
爬虫时如何利用BeautifulSoup获取我们需要的数据?
爬虫大致可以分为三步:
第一步,发送request请求获得html内容第二步,清洗数据,即从html原网页数据中筛选我们需要的数据第三步,将需要的数据储存 在第二步筛选数据是,我们往往可以利用BeautifulSoup来完成&…
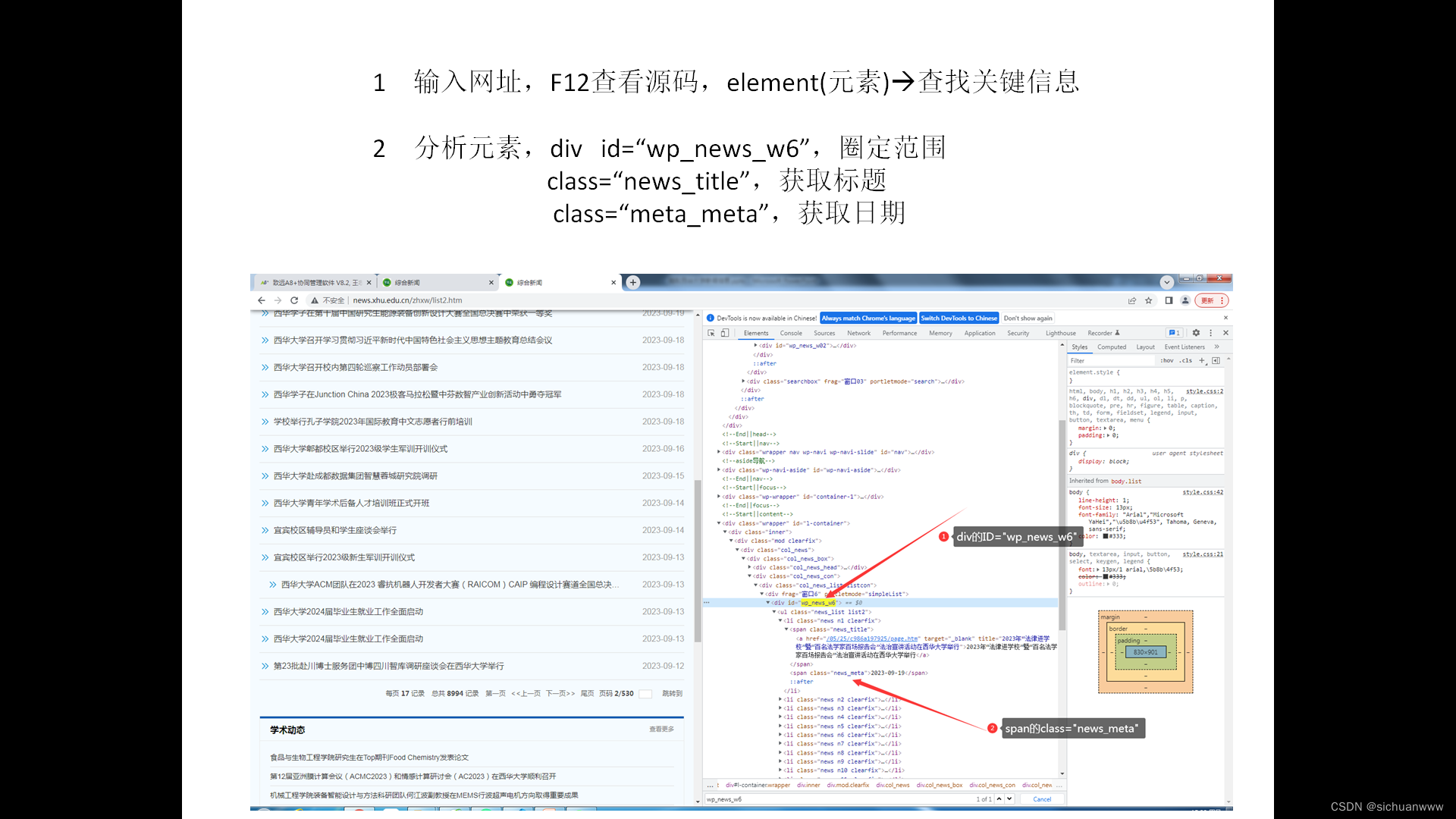
获取西华大学新闻网站信息(爬虫样例)
利用python的爬虫功能进行信息爬取,关键在于源码分析,代码相对简单。
1 源代码分析
访问网站,按下F12,进行元素查找分析。 2 代码实现
from requests import get
from bs4 import BeautifulSoupdef getXhuNews(pageNum1):&qu…