基础学习
装饰器
部署
IMX6ULL
软件工程
DOM型XSS
STM32CubeMX
bert
websocket
klee
CAS
龙蜥
ida
kernel
模块测试
xargs
机场调度管理系统
粘包拆包
Conditional注解
量子计算
代理ip
2024/4/13 6:47:58
Python爬虫代理IP(代理池)——加载和使用
下载地址:https://github.com/
或者直接打开:https://github.com/jhao104/proxy_pool下载完成后注意后面的文档:解压缩文件后打开:打开cmd窗口安装:pip install APScheduler3.2.0(依次安装5个)…

网络IP地址如何更改?怎么使用动态代理IP提高网速?
网络IP地址更改以及使用动态代理IP提高网速的步骤如下: 一、更改IP地址 1. 打开浏览器,输入路由器登陆地址并登陆路由器后台管理界面。 2. 找到“高级设置”或“无线设置”或“VPN设置”一栏,点击“断开”,即可断开网络࿰…

Redis 优缺点、安装与使用以及可视化工具RedisDesktopManager的安装使用(操作是爬取代理ip)
介绍
Redis:Redis是一个基于内存的高性能key-value数据库。
Redis数据支持类型:支持多种数据类型——string、list、hash(散列)、sets(集合)、sorted set(有序集合)
Redis优点:
1.单线程,利用Redis队列技术…

突破技术边界:R与jsonlite库探秘www.snapchat.com的数据之旅
概述
Snapchat是一款流行的社交媒体应用,它允许用户发送和接收带有滤镜和贴纸的照片和视频,以及创建和观看故事和发现内容。Snapchat的数据是非常有价值的,因为它可以反映用户的行为、偏好和趋势。然而,Snapchat的数据并不容易获…

新闻报道的未来:自动化新闻生成与爬虫技术
概述
自动化新闻生成是一种利用自然语言处理和机器学习技术,从结构化数据中提取信息并生成新闻文章的方法。它可以实现大规模、高效、多样的新闻内容生产。然而,要实现自动化新闻生成,首先需要获取可靠的数据源。这就需要使用爬虫技术&#…

Scrapy设置代理IP方法(超详细)
Scrapy是一个灵活且功能强大的网络爬虫框架,用于快速、高效地提取数据和爬取网页。在某些情况下,我们可能需要使用代理IP来应对网站的反爬机制、突破地理限制或保护爬虫的隐私。下面将介绍在Scrapy中设置代理IP的方法,以帮助您更好地应对这些…

解析Perl爬虫代码:使用WWW__Mechanize__PhantomJS库爬取stackoverflow.com的详细步骤
在这篇文章中,我们将探讨如何使用Perl语言和WWW::Mechanize::PhantomJS库来爬取网站数据。我们的目标是爬取stackoverflow.com的内容,同时使用爬虫代理来和多线程技术以提高爬取效率,并将数据存储到本地。
Perl爬虫代码解析
首先࿰…

简单而高效:使用PHP爬虫从网易音乐获取音频的方法
概述
网易音乐是一个流行的在线音乐平台,提供了海量的音乐资源和服务。如果你想从网易音乐下载音频文件,你可能会遇到一些困难,因为网易音乐对其音频资源进行了加密和防盗链的处理。本文将介绍一种使用PHP爬虫从网易音乐获取音频的方法&…

赋能数据收集:从机票网站提取特价优惠的JavaScript技巧
背景介绍
在这个信息时代,数据的收集和分析对于旅游行业至关重要。在竞争激烈的市场中,实时获取最新的机票特价信息能够为旅行者和旅游企业带来巨大的优势。 随着机票价格的频繁波动,以及航空公司和旅行网站不断推出的限时特价优惠ÿ…

挑战音频爬虫的技术迷宫:Watir和Ruby的奇妙合作
概述
音频爬虫是一种可以从网站上抓取音频文件的程序。音频爬虫的应用场景很多,比如语音识别、音乐推荐、声纹分析等。然而,音频爬虫也面临着很多技术挑战,比如音频文件的格式、编码、加密、隐藏、动态加载等。如何突破这些技术障碍…

如何获取美团的热门商品和服务
导语
美团是中国最大的生活服务平台之一,提供了各种各样的商品和服务,如美食、酒店、旅游、电影、娱乐等。如果你想了解美团的热门商品和服务,你可以使用爬虫技术来获取它们。本文将介绍如何使用Python和BeautifulSoup库来编写一个简单的爬虫…

PHP爬虫技术:利用simple_html_dom库分析汽车之家电动车参数
摘要/导言
本文旨在介绍如何利用PHP中的simple_html_dom库结合爬虫代理IP技术来高效采集和分析汽车之家网站的电动车参数。通过实际示例和详细说明,读者将了解如何实现数据分析和爬虫技术的结合应用,从而更好地理解和应用相关技术。
背景/引言
随着电…

挖掘网络宝藏:利用Scala和Fetch库下载Facebook网页内容
介绍
在数据驱动的世界里,网络爬虫技术是获取和分析网络信息的重要工具。本文将探讨如何使用Scala语言和Fetch库来下载Facebook网页内容。我们还将讨论如何通过代理IP技术绕过网络限制,以爬虫代理服务为例。
技术分析
Scala是一种多范式编程语言&…

深入浅出:Objective-C中使用MWFeedParser下载豆瓣RSS
摘要
本文旨在介绍如何在Objective-C中使用MWFeedParser库下载豆瓣RSS内容,同时展示如何通过爬虫代理IP技术和多线程提高爬虫的效率和安全性。
背景
随着信息量的激增,爬虫技术成为了获取和处理大量网络数据的重要手段。Objective-C作为一种成熟的编程…
Python爬虫获取代理ip及端口
爬取代理ip
可以作为模块使用,在使用代理ip的时候直接调用该模块即可。import re
import urllib.requestdef ExtractIP(urlhttp://www.xicidaili.com/):headers {User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:58.0) Gecko/20100101 Firefox/58.0}# url…
代理IP使用的IP协议有哪些?优质的动态IP有什么特征?
一、代理IP使用的IP协议 代理IP使用的主要IP协议有三种:HTTP协议、SOCKS协议和FTP协议。 1. HTTP协议:是最常用的协议,通过HTTP协议传输的数据是明文,它可以在任意多的机器上使用,并且工作方式是可靠的。它是一个无状态…

R语言爬虫程序自动爬取图片并下载
R语言本身并不适合用来爬取数据,它更适合进行统计分析和数据可视化。而Python的requests,BeautifulSoup,Scrapy等库则更适合用来爬取网页数据。如果你想要在R中获取网页内容,你可以使用rvest包。 以下是一个简单的使用rvest包爬取…

加速数据采集:用OkHttp和Kotlin构建Amazon图片爬虫
引言
曾想过轻松获取亚马逊上的商品图片用于项目或研究吗?是否曾面对网络速度慢或被网站反爬虫机制拦截而无法完成数据采集任务?如果是,那么本文将为您介绍如何用OkHttp和Kotlin构建一个高效的Amazon图片爬虫解决方案。
背景介绍
亚马逊&a…

【HTTP爬虫ip实操】智能路由构建高效稳定爬虫系统
在当今信息时代,数据的价值越来越受到重视。对于许多企业和个人而言,网络爬取成为了获取大量有用数据的关键手段之一。然而,在面对反爬机制、封锁限制以及频繁变动的网站结构时,如何确保稳定地采集所需数据却是一个不容忽视且具挑…

是否有无限提取的代理IP?作为技术你需要知道这些
最近有互联网行业的技术小伙伴问到,有没有可以无限提取的代理IP?就是比如我一秒钟提取几万、几十万次,或者很多台机器同时调用API提取链接,这样可以吗?看到这个问题,不禁沉思起来,其实理论上是存…
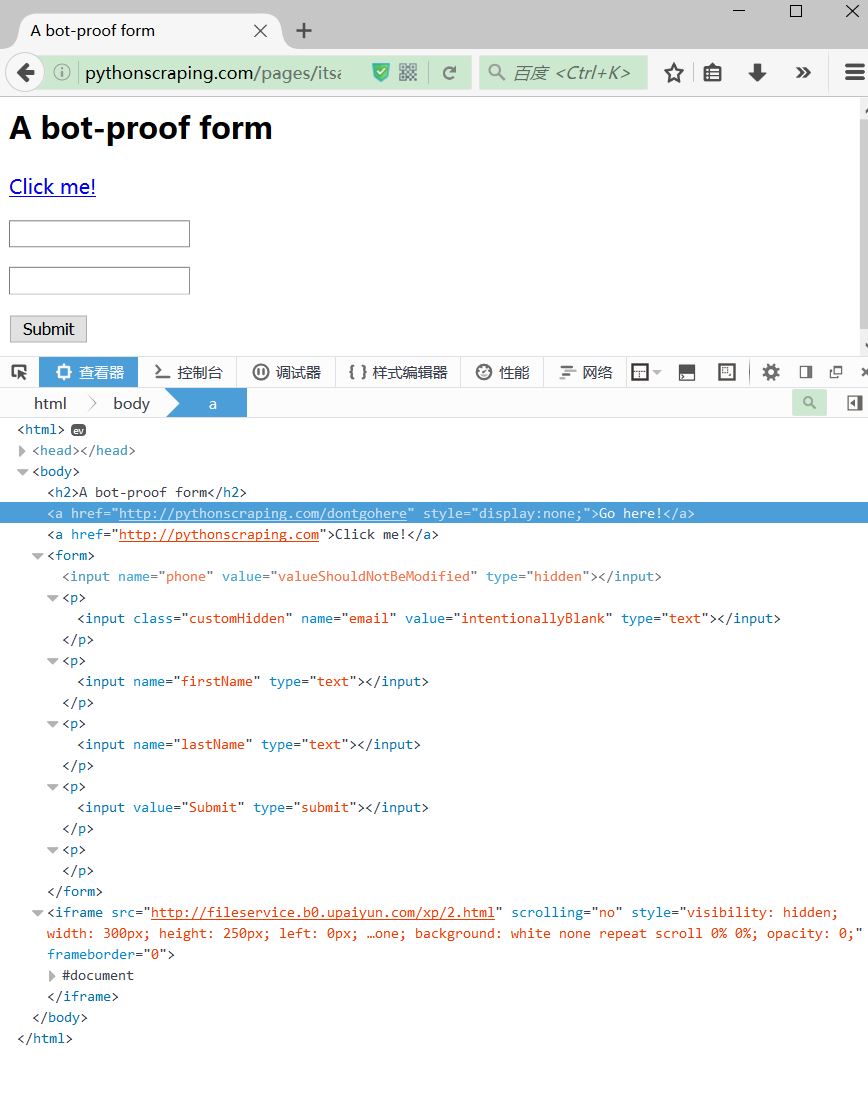
Python爬虫防封杀方法集合
Python 2.7 IDE Pycharm 5.0.3 前言
在爬取的过程中难免发生ip被封和403错误等等,这都是网站检测出你是爬虫而进行反爬措施,这里自己总结下如何避免方法1:设置等待时间
有一些网站的防范措施可能会因为你快速提交表单而把你当做机器人爬虫…

Python爬虫使用代理IP的实现
使用爬虫时,如果目标网站对访问的速度或次数要求较高,那么你的 IP 就很容易被封掉,也就意味着在一段时间内无法再进行下一步的工作。这时候代理 IP 能够给我们带来很大的便利,不管网站怎么封,只要能找到一个新的代理 I…
超快速的python代理IP提取程序
从国外的代理IP网站提取代理IP, 100%可用!!!
py代码:
# -*- coding:utf-8 -*-
import requests
import re
import execjsti """请选择提取的数量: 0.30个代理IP
1.50个代理IP
2.100个代理IP
3.200个代理IP
4.300个代理IP
5.500个代理IP请输入你要提取数量的编…

C#编程艺术:Fizzler库助您高效爬取www.twitter.com音频
数据是当今数字时代的核心资源,但是从互联网上抓取数据并不容易。本文将教您如何利用C#编程艺术和Fizzler库高效爬取Twitter上的音频数据,让您轻松获取所需信息。
Twitter简介
Twitter是全球最大的社交媒体平台之一,包含丰富的音频资源。用…

超越常规:用PHP抓取招聘信息
在人力资源管理方面,有效的数据采集可以为公司提供宝贵的人才洞察。通过分析招聘网站上的职位信息,人力资源专员可以了解市场上的人才供给情况,以及不同行业和职位的竞争状况。这样的数据分析有助于企业制定更加精准的招聘策略,从…

跨越网络边界:借助C++编写的下载器程序,轻松获取Amazon商品信息
背景介绍
在数字化时代,数据是新的石油。企业和开发者都在寻找高效的方法来收集和分析网络上的信息。亚马逊,作为全球最大的电子商务平台之一,拥有丰富的商品信息,这对于市场分析和竞争情报来说是一个宝贵的资源。
问题陈述
然…

掌握网络抓取技术:利用RobotRules库的Perl下载器一览小红书的世界
引言
在信息时代的浪潮下,人们对于获取和分析海量网络数据的需求与日俱增。网络抓取技术作为满足这一需求的关键工具,正在成为越来越多开发者的首选。而Perl语言,以其卓越的文本处理能力和灵活的特性,脱颖而出,成为了…

亮数据代理IP轻松解决爬虫数据采集痛点
文章目录 一、爬虫数据采集痛点二、为什么使用代理IP可以解决?2.1 爬虫和代理IP的关系2.2 使用代理IP的好处 三、亮数据代理IP的优势3.1 IP种类丰富3.1.1 动态住宅代理IP3.1.2 静态住宅代理IP3.1.3 机房代理IP3.1.4 移动代理IP 3.2 高质量IP全球覆盖3.3 超级代理服务…

获取代理IP(proxy_pool)
1.首先拉取代码
https://github.com/jhao104/proxy_pool.git
2.配置py环境:
pip install -r requirements.txt 配置配置文件(redis)(Config中)
DB_TYPE getenv(db_type, REDIS).upper()
DB_HOST getenv(db_host,…

增强Java技能:使用OkHttp下载www.dianping.com信息
在这篇技术文章中,我们将探讨如何使用Java和OkHttp库来下载并解析www.dianping.com上的商家信息。我们的目标是获取商家名称、价格、评分和评论,并将这些数据存储到CSV文件中。此外,我们将使用爬虫代理来绕过任何潜在的IP限制,并实…

手机与电脑更改IP地址怎么使用代理IP?
在现代互联网时代,代理IP已成为许多人日常生活和工作中不可或缺的一部分。通过代理IP,用户可以隐藏自己的真实IP地址,并获得更好的网络体验。本文将详细介绍如何在手机和电脑上更改IP地址并使用代理IP。 一、手机使用代理IP 1. 打开手机设置&…

巧用简单工具:PHP使用simple_html_dom库助你轻松爬取JD.com
概述
爬虫技术是一种从网页上自动提取数据的方法,它可以用于各种目的,比如数据分析、网站监控、竞争情报等。爬虫技术的难度和复杂度取决于目标网站的结构和反爬策略,有些网站可能需要使用复杂的工具和技巧才能成功爬取,而有些网…
网络IP地址被限制怎么使用代理IP破解呢?
网络IP地址被限制是一个常见的问题,尤其对于需要进行大量网络访问的用户来说更是如此。当您的IP地址被限制时,您可能会遇到无法正常访问某些网站或服务的情况。在这种情况下,使用代理IP是一种常见的解决方案。 一、了解代理IP 代理IP是一种通…

使用代理IP时有哪些小技巧?大数据技术人员必看
很多大数据行业和跨境行业的用户都会使用到一个工具,就是代理IP工具,不过很多人对它的研究不深,其实在使用它时是有一些小技巧的,它不仅可以帮助我们隐蔽我们的真实IP地址,实现多账号矩阵运营,同时还能让我…

如何在ForeSpider爬虫软件中设置代理IP?
作者 | 前嗅 来源 | 前嗅大数据(www.forenose.com)
今天为大家介绍一下:如何在ForeSpider数据采集器中设置代理IP。
前嗅ForeSpider数据采集引擎,一款通用的数据采集系统,还带有数据挖掘、清洗分类及筛选导出的功能&…

深入探讨网络抓取:如何使用 Scala 和 Dispatch 获取 LinkedIn 图片
网络抓取是一种从互联网上获取数据的技术,它可以用于各种目的,例如数据分析、信息检索、竞争情报等。网络抓取的过程通常包括以下几个步骤:
发送 HTTP 请求到目标网站解析响应的 HTML 文档提取所需的数据存储或处理数据
在本文中࿰…

代理IP采集数据:挖掘洞察力的关键工具
在当今数字化时代,数据被视为珍贵的资源,对于企业和组织来说,获取准确、有价值的数据是至关重要的。在数据采集的过程中,代理IP(Internet Protocol)发挥着关键的作用。本文将介绍代理IP在数据采集中的应用&…

使用代理IP技术实现爬虫同步获取和保存
概述
在网络爬虫中,使用代理IP技术可以有效地提高爬取数据的效率和稳定性。本文将介绍如何在爬虫中同步获取和保存数据,并结合代理IP技术,以提高爬取效率。
正文
代理IP技术是一种常用的网络爬虫技术,通过代理服务器转发请求&a…

打破常规思维:Scrapy处理豆瓣视频下载的方式
概述
Scrapy是一个强大的Python爬虫框架,它可以帮助我们快速地开发和部署各种类型的爬虫项目。Scrapy提供了许多方便的功能,例如请求调度、数据提取、数据存储、中间件、管道、信号等,让我们可以专注于业务逻辑,而不用担心底层的…