开发语言
自定义气泡提示框
windows
docker
分子对接
sqlserver
二叉树
Toast提示信息
安全测试
前缀和
macos
度中心性
多态和虚函数的使用底层实现原理
OpenAI
软考高级系统架构设计师系列
cannon
断点
django-redis
高精地图
网上购书系统
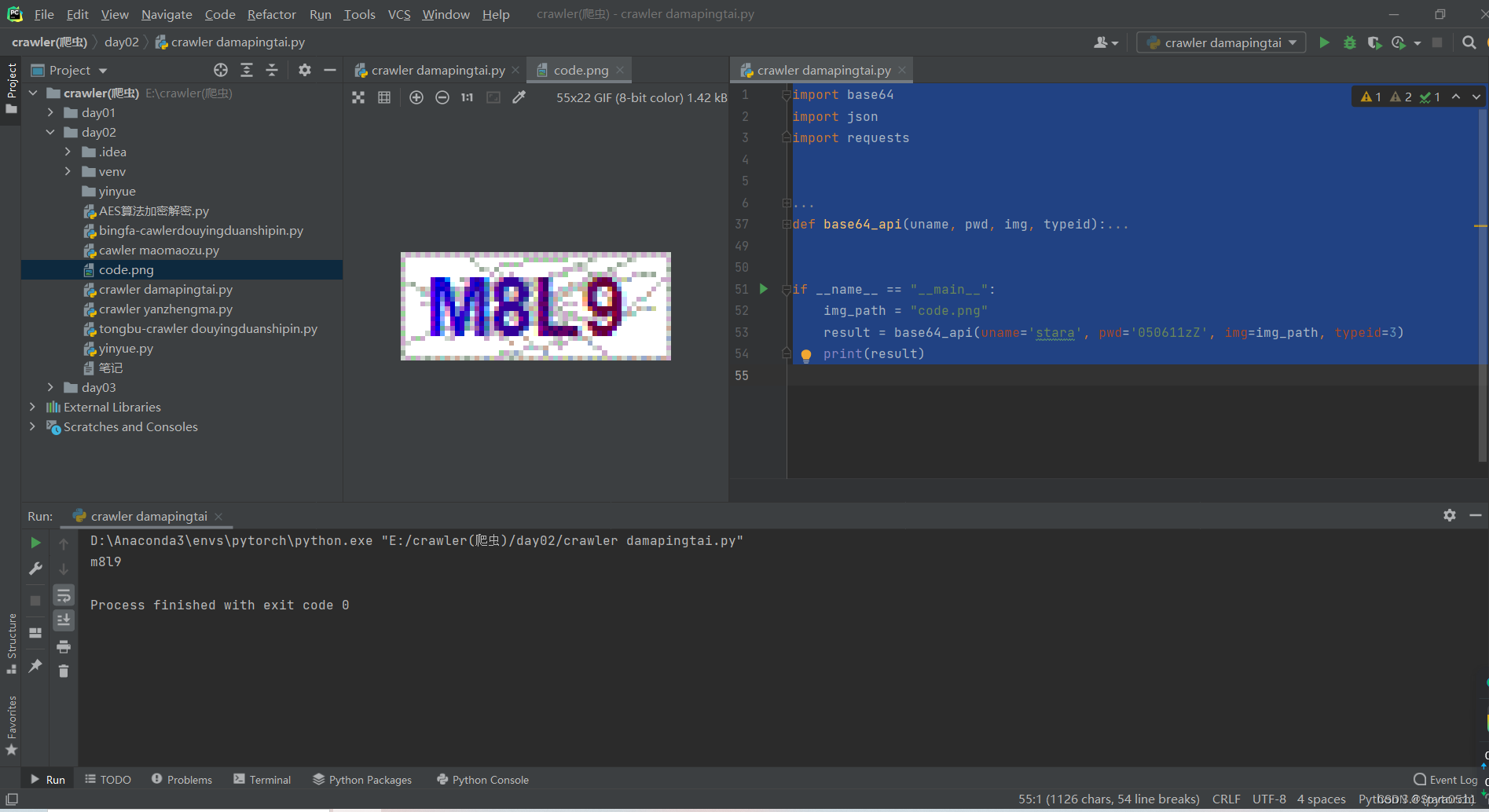
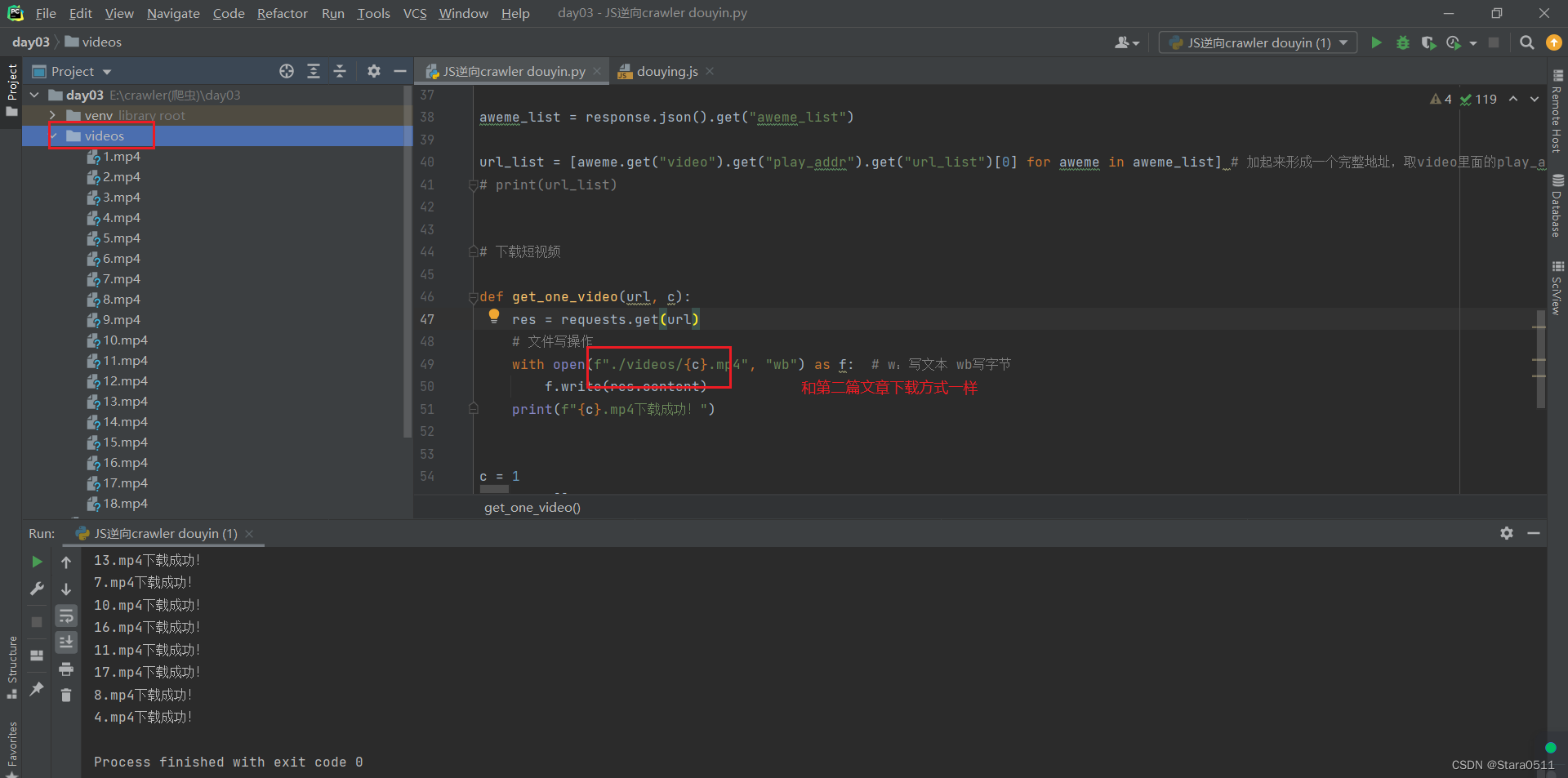
Crawler
2024/9/2 11:58:30

使用 Curl 和 DomCrawler 下载抖音视频链接并存储到指定文件夹
项目需求
假设我们需要从抖音平台上下载一些特定的视频,以便进行分析、编辑或其他用途。为了实现这个目标,我们需要编写一个爬虫程序来获取抖音视频的链接,并将其保存到本地文件夹中。
目标分析
在开始编写爬虫之前,我们需要了…

Crawler4j实例爬取爱奇艺热播剧案例
前言
热播剧数据在戏剧娱乐产业中扮演着着名的角色。热了解播剧的观众喜好和趋势,对于制作方和广告商来说都具有重要的参考价值。然而,手动收集和整理这些数据是在本文中,我们将介绍如何利用 Python 爬虫技术和 Crawler4j 实例来自动化爬取爱…

使用 JDAudioCrawler 将下载的音频存储到本地存储
前言
在当今数字化时代,音频数据的获取和处理变得越来越重要。本文将访问网易云音乐为案例,介绍如何使用JDAudioCrawler这个强大的工具,将音频数据存储下载到本地存储中。将详细介绍实现的流程和代码细节。
什么是 JDAudioCrawler
DAudioC…