网络爬虫:可以理解成网页蜘蛛,在网页上采集数据
爬取流程:
1、导入模块
2、打开网页,获取原码
3、获取章节原码
4、获取正文
5、过滤‘杂质’
6、保存下载
废话不多说开始爬!!!
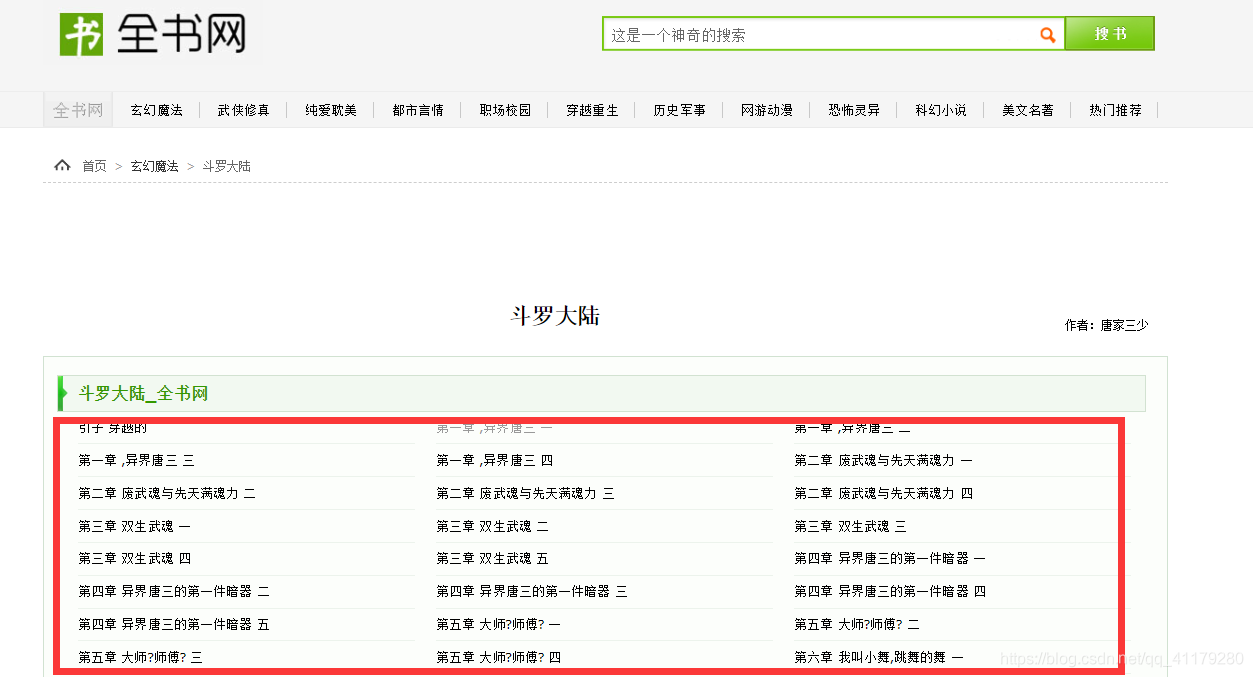
今天爬的网站是 全书网—斗罗大陆
准备工作、首先我们先导入两个模块
python">import urllib.request #打开和浏览url中内容
import re #匹配我们需要的内容第一步、打开网站,获得源代码
python">import urllib.request
import re
def run():
html = urllib.request.urlopen("http://www.quanshuwang.com/book/1/1379").read() #打开网站链接,并储存下来
html = html.decode('gbk') #将 字节 --->>> str
print(html)
run()运行结果就是获取到了网页的源代码,由于太长了,挑重点的往上复制 ,可以看出网页源代码存在我们想要的信息,每篇文章的网页链接,我们想要获取到,就需要用到re正则表达式了。
(-----------------------此处省略了一堆--------------------------)
<li><a href="http://www.quanshuwang.com/book/1/1379/7392650.html" title="引子 穿越的,共2712字">引子 穿越的</a></li>
<li><a href="http://www.quanshuwang.com/book/1/1379/7392651.html" title="第一章 ,异界唐三 一,共2082字">第一章 ,异界唐三 一</a></li>
<li><a href="http://www.quanshuwang.com/book/1/1379/7392652.html" title="第一章 ,异界唐三 二,共2117字">第一章 ,异界唐三 二</a></li>
<li><a href="http://www.quanshuwang.com/book/1/1379/7392653.html" title="第一章 ,异界唐三 三,共2109字">第一章 ,异界唐三 三</a></li>
<li><a href="http://www.quanshuwang.com/book/1/1379/7392654.html" title="第一章 ,异界唐三 四,共1967字">第一章 ,异界唐三 四</a></li>
<li><a href="http://www.quanshuwang.com/book/1/1379/7392655.html" title="第二章 废武魂与先天满魂力 一,共1920字">第二章 废武魂与先天满魂力 一</a></li>
<li><a href="http://www.quanshuwang.com/book/1/1379/7392656.html" title="第二章 废武魂与先天满魂力 二,共1956字">第二章 废武魂与先天满魂力 二</a></li>
(-----------------------此处省略了一堆--------------------------)
第二步、获取章节源代码
python">import urllib.request
import re
def run():
html = urllib.request.urlopen("http://www.quanshuwang.com/book/1/1379").read() #打开网站链接,并储存下来
html = html.decode('gbk') #将 字节 --->>> str
get_url =re.compile(r'<li><a href="(.*?)" title=".*?">(.*?)</a></li>') #设置匹配的条件
get_html_url =re.findall(get_url,html) #开始匹配
print(get_html_url) #输出一下看看
run()运行结果就是我们获得了一个列表,列表里有包含章节url和文章标题的元组,然后我们就可以通过遍历获取每个章节的url然后再进行和第一步一样的事情,获取章节所在页面的原码。
D:\alien_invasion\venv\Scripts\python.exe D:/alien_invasion/venv/斗罗大陆_爬虫/get_斗罗大陆.py
[('http://www.quanshuwang.com/book/1/1379/7392650.html', '引子 穿越的'), ('http://www.quanshuwang.com/book/1/1379/7392651.html', '第一章 ,异界唐三 一'), ('http://www.quanshuwang.com/book/1/1379/7392652.html', '第一章 ,异界唐三 二'), ('http://www.quanshuwang.com/book/1/1379/7392653.html', '第一章 ,异界唐三 三'),(-----------------------此处省略了一堆--------------------------)
('http://www.quanshuwang.com/book/1/1379/7393365.html', '第二百三十五章 完美融合之双神战双神'), ('http://www.quanshuwang.com/book/1/1379/7393366.html', '第二百三十六章 大结局,最后一个条件')]
通过遍历列表,利用索引 url[0] 方式,获取网页链接
python">import urllib.request
import re
def run():
html = urllib.request.urlopen("http://www.quanshuwang.com/book/1/1379").read() #打开网站链接,并储存下来
html = html.decode('gbk') #将 字节 --->>> str
get_url =re.compile(r'<li><a href="(.*?)" title=".*?">(.*?)</a></li>') #设置匹配规则
get_html_urls =re.findall(get_url,html) #匹配
for url in get_html_urls: #遍历每个url
content_h = urllib.request.urlopen(url[0]).read() #根据每个url获取页面原码
content_html = content_h.decode('gbk')
print(content_html)
run()结果没问题,不信你自己搞下
4.获取正文
利用re正则获取正文
python">import urllib.request
import re
def run():
html = urllib.request.urlopen("http://www.quanshuwang.com/book/1/1379").read() #打开网站链接,并储存下来
html = html.decode('gbk') #将 字节 --->>> str
get_url =re.compile(r'<li><a href="(.*?)" title=".*?">(.*?)</a></li>') #设置匹配规则
get_html_urls =re.findall(get_url,html) #匹配
for url in get_html_urls: #遍历每个url
content_h = urllib.request.urlopen(url[0]).read() #根据每个url获取页面原码
content_html = content_h.decode('gbk')
reg = re.compile(r'</script> (.*?)<script type="text/javascript">',re.S) #设置匹配规则
content = re.findall(reg,content_html) #匹配
print(content)
run()可以看出我们抓出的正文存在在一个列表中,但是中间有我们不想要的信息,比如: 或者 <br />
['新书小三先开通了,方便书友们收藏。本书会在12月20曰,《琴帝》结束的同时同步开始更新。保持小三一贯的不断更衔接传统。小三相信,这本书将会给书友们带来更大的惊喜。多谢大家的支持<br />\r\n<br />\r\n ---------------------------------------<br />\r\n<br />\r\n 巴蜀,历来有天府之国的美誉,其中,最有名的门派莫过于唐门。<br />\r\n<br />\r\n 唐门所在是一个神秘的地方,许多人只知道,那是一个半山腰,而唐门所在这座山的山顶有一个令人胆颤心惊的名字,——鬼见愁。<br />\r\n<br />\r\n 从鬼见愁悬崖上扔出一块石头,开了这个世界,但他的另一次命运却刚刚开始。<br />\r\n<br />\r\n ----------------------------------------<br />\r\n<br />\r\n 大家自然看得出,书里的小三穿越了。他将来到另一个世界,一个充斥着全新设定的世界。这本新书的设定,小三足足构思了半年时/>\r\n 本集预告:唐门外门弟子唐三,因偷学内门绝学为唐门所不容,跳崖明志时却来到了另一个世界,这是一个武魂的世界。
------------------------------省略了一堆-----------------------
而立志修炼唐门绝技的唐三,会去修炼他的武魂么他的武魂又是什么呢请阅本集。<br />\r\n<br />\r\n 本来小三还想发个本集人物设定出来,但后来一想,还是先保留了,不过悄悄告诉大家,在出场人物中,会有惊喜。嘿嘿。']
5.过滤杂质
我们用replace函数替换掉我们不需要的杂质。
python">import urllib.request
import re
def run():
html = urllib.request.urlopen("http://www.quanshuwang.com/book/1/1379").read() #打开网站链接,并储存下来
html = html.decode('gbk') #将 字节 --->>> str
get_url =re.compile(r'<li><a href="(.*?)" title=".*?">(.*?)</a></li>') #设置匹配规则
get_html_urls =re.findall(get_url,html) #匹配
for url in get_html_urls: #遍历每个url
content_h = urllib.request.urlopen(url[0]).read() #根据每个url获取页面原码
content_html = content_h.decode('gbk')
reg = re.compile(r'</script> (.*?)<script type="text/javascript">',re.S) #设置匹配规则
content = re.findall(reg,content_html) #匹配
content = content[0].replace(' ',' ').replace('<br />',' ') #将杂质替换成空格
print(content)
run()这样就得到我们需要的文章了
新书小三先开通了,方便书友们收藏。本书会在12月20曰,《琴帝》结束的同时同步开始更新。保持小三一贯的不断更衔接传统。小三相信,这本书将会给书友们带来更大的惊喜。多谢大家的支持
---------------------------------------
巴蜀,历来有天府之国的美誉,其中,最有名的门派莫过于唐门。
------------------------再次省略一堆----------------------------------
他也一定会很欣慰,他的努力终究没有白费。可是,这一切都来的太迟了一些。
鬼见愁,那扔下一块石头也要数上十九秒,似乎超越十八层地狱的存在,又怎么可能允许一个活人被云雾释放而归唐三走了,他永远的离开了这个世界,但他的另一次命运却刚刚开始。
6.写入文件
python">import urllib.request
import re
def run():
html = urllib.request.urlopen("http://www.quanshuwang.com/book/1/1379").read() #打开网站链接,并储存下来
html = html.decode('gbk') #将 字节 --->>> str
get_url =re.compile(r'<li><a href="(.*?)" title=".*?">(.*?)</a></li>') #设置匹配规则
get_html_urls =re.findall(get_url,html) #匹配
for url in get_html_urls: #遍历每个url
content_h = urllib.request.urlopen(url[0]).read() #根据每个url获取页面原码
content_html = content_h.decode('gbk')
reg = re.compile(r'</script> (.*?)<script type="text/javascript">',re.S) #设置匹配规则
content = re.findall(reg,content_html) #匹配
content = content[0].replace(' ',' ').replace('<br />',' ') #将杂质替换成空格
with open(url[1]+'.txt','w')as a: #写文件,并以章节名称命名
a.write(content)
run()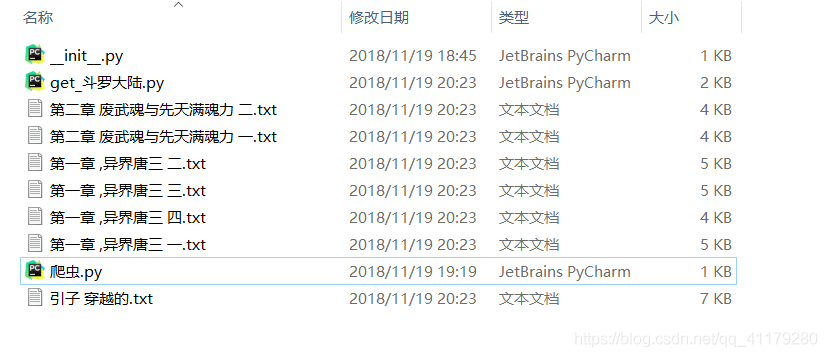
一个简单的爬虫就KO了!开心吧!