前段时间,一朋友让我做个小脚本,抓一下某C2C商城上竞争对手的销售/价格数据,好让他可以实时调整自己的营销策略。自己之前也有过写爬虫抓某宝数据的经历,实现的问题不大,于是就答应了。初步想法是利用pyhton中的urllib.request和re两个lib(本文示例用的是Pyhton 3.4 ,2.x的请自行切换),外加上其他的统计分析功能的话,最多两个晚上(白天要工作)可以搞定。实际上做的过程中,遇到了两个主要困难:
(1)电商网站对于交易数据的保护很好。小爬虫动不动就会被ban掉或者采用一些其他的保护措施使得其无法正常采集所需的数据,需要添加额外的代码处理各种虐心的情况;
(2)正则表达式实在是难写,而且很复杂和很难维护。于是自己也思考有没有其他的解决方案——本文就是对其中一解决方案的初步介绍。
一开始想到的当然是著名的第三方库
Beautifulsoup(作为一个广东男人,我习惯把它称为”靓汤“)。这个库很强大,但正因为它强大,需要一点学习时间而我需要快点上手,于是只好日后再学(到时再写一篇Beautifulsoup学习总结)。权衡以后,最后目光转向了Python Standard Library中的html.parser。
html.parser是一个非常简单和实用的库,它的核心是HTMLParser类。从源码来看,它内部封装了一系列regular expression。工作的流程是:当你feed给它一个类似HTML格式的字符串时,它会调用goahead方法向前迭代各个标签,并调用对应的parse_xxxx方法提取start_tag, tag, attrs data comment和end_tag等等标签信息和数据,然后调用对应的方法对这些抽取出来的内容进行处理。整个HTMLParser的大致结构如下图所示:
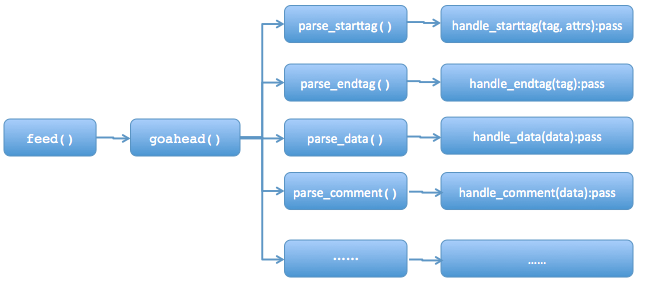
可以发现,处理开始标签(handle_starttag)、结束标签(handle_endtag)和处理数据(handle_data)等处理函数在HTMLParser里是没有实现的(pass),这需要我们继承HTMLParser这个类的并覆盖这些方法。详细可以参阅python文档,这里重点介绍几个常用的方法:
- feed(data):主要用于接受带html标签的str,当调用这个方法时并提供相应的data时,整个实例(instance)开始执行,结束执行close()。
- handle_starttag(tag, attrs): 这个方法接收Parse_starttag返回的tag和attrs,并进行处理,处理方式通常由使用者进行覆盖,本身为空。例如,连接的start tag是<a>,那么对应的参数tag=’a’(小写)。attrs是start tag <>中的属性,以元组形式(name, value)返回(所有这些内容都是小写)。例如,对于<A HREF="http://www.baidu.com“>,那么内部调用形式为:handle_starttag(’a’,[(‘href’,’http://www.baidu.com)]).
- handle_endtag(tag):跟上述一样,只是处理的是结束标签,也就是以</开头的标签。
- handle_data(data):处理的是网页的数据,也就是开始标签和结束标签之间的内容。例如:<script>...</script>的省略号内容
- reset():将实例重置,包括作为参数输入的数据进行清空。
举个例子吧。例如我们有以下一堆带HTML标签的数据,
<h3 class="
tb-main-title" data-title="
【金冠现货/全色/顶配版】Xiaomi/小米 小米note移动联通4G手机">
【金冠现货/全色/顶配版】Xiaomi/小米 小米note移动联通4G手机
</h3>
<p class=" tb-subtitle">
【购机即送布丁套+高清贴膜+线控耳机+剪卡器+电影支架等等,套餐更多豪礼更优惠】 【购机即送布丁套+高清贴膜+线控耳机+剪卡器+电影支架等等,套餐更多豪礼更优惠】 【金冠信誉+顺丰包邮+全国联保---多重保障】
</p>
<div id=" J_TEditItem" class=" tb-editor-menu"></div>
</h3>
<p class=" tb-subtitle">
【购机即送布丁套+高清贴膜+线控耳机+剪卡器+电影支架等等,套餐更多豪礼更优惠】 【购机即送布丁套+高清贴膜+线控耳机+剪卡器+电影支架等等,套餐更多豪礼更优惠】 【金冠信誉+顺丰包邮+全国联保---多重保障】
</p>
<div id=" J_TEditItem" class=" tb-editor-menu"></div>
</div>
<h3 class="
tb-main-title" data-title="
【现货增强/标准】MIUI/小米 红米手机2红米2移动联通电信4G双卡">
【现货增强/标准】MIUI/小米 红米手机2红米2移动联通电信4G双卡
</h3>
<p class=" tb-subtitle">
[红米手机2代颜色版本较多,请亲们阅读购买说明按需选购---感谢光临] 【金皇冠信誉小米手机集市销量第一】【购买套餐送高清钢化膜+线控通话耳机+ 剪卡器(含还原卡托)+ 防辐射贴+专用高清贴膜+ 擦机布+ 耳机绕线器+手机电影支架+ 一年延保服务+ 默认享受顺丰包邮 !
</p>
<div id=" J_TEditItem" class=" tb-editor-menu"></div>
【现货增强/标准】MIUI/小米 红米手机2红米2移动联通电信4G双卡
</h3>
<p class=" tb-subtitle">
[红米手机2代颜色版本较多,请亲们阅读购买说明按需选购---感谢光临] 【金皇冠信誉小米手机集市销量第一】【购买套餐送高清钢化膜+线控通话耳机+ 剪卡器(含还原卡托)+ 防辐射贴+专用高清贴膜+ 擦机布+ 耳机绕线器+手机电影支架+ 一年延保服务+ 默认享受顺丰包邮 !
</p>
<div id=" J_TEditItem" class=" tb-editor-menu"></div>
</div>
很明显,这里面包含了两台手机,我们的目标是提取两个手机的名字出来。
由于当我们feed这个html到HTMLParser中后,他们所有的标签都迭代,如果需要它只提取我们需要的数据时,我们需要设置当handle_starttag遇到那个标签和属性时,才调用handle_data并print出我们的结果,这个时候我们可以使用一个flg作为判定,代码如下:
python">
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
python comments">#定义一个MyParser继承自HTMLParser
python keyword">class
python plain">MyParser(HTMLParser):
python spaces">
python plain">re
python keyword">=
python plain">[]
python comments">#放置结果
python spaces">
python plain">flg
python keyword">=
python value">0
python comments">#标志,用以标记是否找到我们需要的标签
python spaces">
python keyword">def
python plain">handle_starttag(
python color1">self
python plain">, tag, attrs):
python spaces">
python keyword">if
python plain">tag
python keyword">=
python keyword">=
python string">'h3'
python plain">:
python comments">#目标标签
python spaces">
python keyword">for
python plain">attr
python keyword">in
python plain">attrs:
python spaces">
python keyword">if
python plain">attr[
python value">0
python plain">]
python keyword">=
python keyword">=
python string">'class'
python keyword">and
python plain">attr[
python value">1
python plain">]
python keyword">=
python keyword">=
python string">'tb-main-title'
python plain">:
python comments">#目标标签具有的属性
python spaces">
python color1">self
python plain">.flg
python keyword">=
python value">1
python comments">#符合条件则将标志设置为1
python spaces">
python keyword">break
python spaces">
python keyword">else
python plain">:
python spaces">
python keyword">pass
python spaces">
python spaces">
python keyword">def
python plain">handle_data(
python color1">self
python plain">, data):
python spaces">
python keyword">if
python color1">self
python plain">.flg
python keyword">=
python keyword">=
python value">1
python plain">:
python spaces">
python color1">self
python plain">.re.append(data.strip())
python comments">#如果标志为我们需要的标志,则将数据添加到列表中
python spaces">
python color1">self
python plain">.flg
python keyword">=
python value">0
python comments">#重置标志,进行下次迭代
python spaces">
python keyword">else
python plain">:
python spaces">
python keyword">pass
python plain">my
python keyword">=
python plain">MyParser()
python plain">my.feed(html)
|
运行结果如下,达到了我们的预期:

上面只是HTMLParser一个非常简单的应用,但却可以反应了HTMLParser这个类的一些特质。有了这些基本的认识后,我们就可以将相关功能进行扩展,从而形成一个标准的爬虫了。下次,我们将利用相关的知识,构建一个基本的网络爬虫,敬请期待哦。
--------------------------------------------------
本文为作者原创文章,转摘请注明出处:@Datazen