大家好,我叫谢伟,是一名程序员。
我写过很多爬虫,这是我最后一次在文章中内提及爬虫。以后都不再写了,想要研究其他领域。
本节的主题:Golang 爬虫如何上手。
主要分下面几个步骤:
- 获取网页源代码
- 解析数据
- 存储数据
1. 获取网页源代码
使用原生的 net/http 库进行请求即可:
GET
func GetHttpResponse(url string, ok bool) ([]byte, error) {
request, err := http.NewRequest("GET", url, nil)
if err != nil {
return nil, errors.ErrorRequest
}
request.Header.Add("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36")
client := http.DefaultClient
response, err := client.Do(request)
if err != nil {
return nil, errors.ErrorResponse
}
defer response.Body.Close()
fmt.Println(response.StatusCode)
if response.StatusCode >= 300 && response.StatusCode <= 500 {
return nil, errors.ErrorStatusCode
}
if ok {
utf8Content := transform.NewReader(response.Body, simplifiedchinese.GBK.NewDecoder())
return ioutil.ReadAll(utf8Content)
} else {
return ioutil.ReadAll(response.Body)
}
}
复制代码POST
func PostHttpResponse(url string, body string, ok bool) ([]byte, error) {
payload := strings.NewReader(body)
requests, err := http.NewRequest("POST", url, payload)
if err != nil {
return nil, errors.ErrorRequest
}
requests.Header.Add("Content-Type", "application/x-www-form-urlencoded")
requests.Header.Add("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36")
client := http.DefaultClient
response, err := client.Do(requests)
if err != nil {
return nil, errors.ErrorResponse
}
fmt.Println(response.StatusCode)
defer response.Body.Close()
if ok {
utf8Content := transform.NewReader(response.Body, simplifiedchinese.GBK.NewDecoder())
return ioutil.ReadAll(utf8Content)
}
return ioutil.ReadAll(response.Body)
}
复制代码使用上面两个函数,不管是遇到的请求是Get 或者是 Post 都可以获取到网页源代码,唯一需要注意的可能是Post 请求需要正确的传递参数给请求。
使用原生的库需要写很多的代码,那有没有更简洁一些的写法?
已经有人把原生的 net/http 库,进一步的进行了封装,形成了这样一个库:gorequest.
gorequest 文档
对外暴露的接口非常的简单:
resp, body, errs := gorequest.New().Get("http://example.com/").End()
复制代码一行代码即可完成一次请求。
Post 的请求也可以比较简便的完成:
request := gorequest.New()
resp, body, errs := request.Post("http://example.com").
Set("Notes","gorequst is coming!").
Send(`{"name":"backy", "species":"dog"}`).
End()
复制代码上述两种方式,按照自己喜好选择,可以获取到网页源代码。此为第一步。
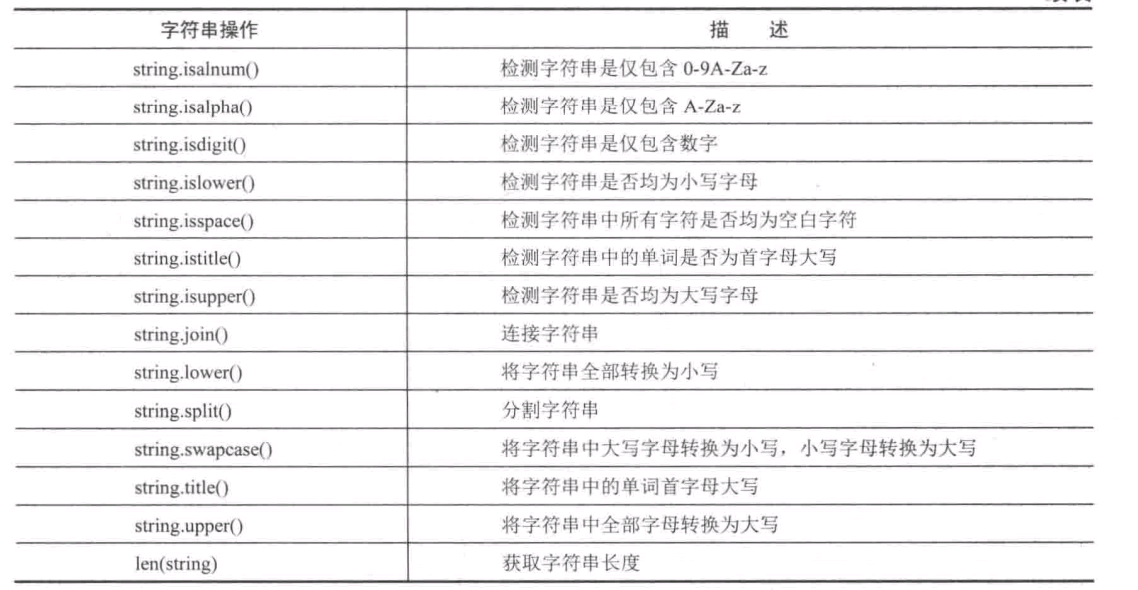
2. 解析数据
对获取到的网页源代码,我们需要进行进一步的解析,得到我们需要的数据。
依据响应的不同类型,我们可以选择不同的方法。
一般如果响应是 html 格式的数据,那么我们可以很友好的选择正则表达式或者Css 选择器获取到我们需要的内容。
但如果是json 数据呢,那么我们可以使用原生的 encoding/json 库来进行对得倒的数据反序列化,也能将数据获取到。
好,知道了具体的方法,那么我们的目标就是:
- 熟悉正则表达式用法,知道相应的情况下如何编写正则表达式
- 熟悉 json 的序列化和反序列化
- 熟悉 css 选择器各符号代表的意思,能在chrome 调试窗口写出css 选择器
1. 基本思路
- 清晰需要的内容
- 分析网页
- 获取网页信息
- 解析网页信息
2. 分析网页
- Chrome 浏览器审查元素,查看网页源代码
3. 网页响应值的类型
4. 请求的类型
- Get : 常见,直接请求即可
- Post : 需要分析请求的参数,构造请求,向对方服务器端发送请求,再解析响应值
5. 请求头部信息
- Uer-Agent 头部信息
6. 存储
- 本地: text、json、csv
- 数据库: 关系型(postgres、MySQL), 非关系型(mongodb), 搜索引擎(elasticsearch)
7. 图片处理
- 请求
- 存储
8. 其他
- 代理: ip 池
- User-Agent: 模拟浏览器
- APP: APP 数据需要使用抓包工具:Mac(Charles)、Windows(Fiddler)(分析出Api)
9. 难点
- 分布式
- 大规模抓取
实例
- 中国票房
- 中影指数
- 懂球帝
- GithubTrending
- 古诗文
- 猫眼票房
- 糯米票房
- Pexels图片社区
- 全球票房排行榜
几大要点
如何获取网页源代码
- 原生 net/http
- gorequest (基于原生的net/http 封装)
Web客户端请求方法
- Get 绝大多少数
- Post
Web服务端响应
- json
- html
Web服务端响应的处理方式
存储数据方式
- Text
- Json
- Csv
- db
前三种,涉及文件读写;最后者涉及数据库操作
源代码
仅供参考: 参考
全文完,我是谢伟,再会。