1、scrapy
scrapy作为一款优秀的爬虫框架,在爬虫方面有这众多的优点。能快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。
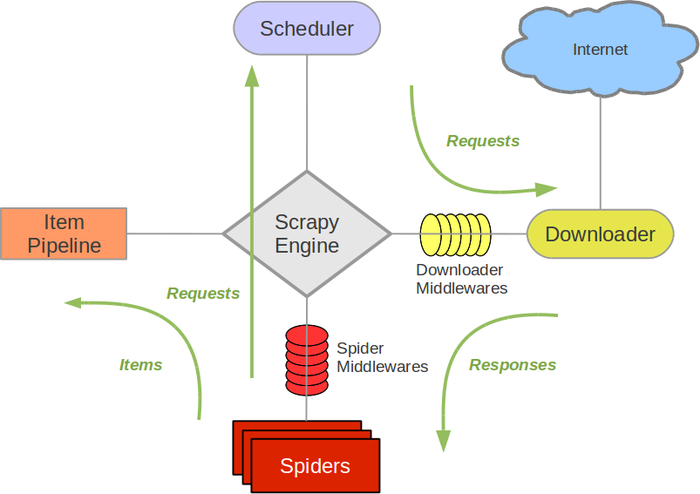
它的主要组件有如下几种:
引擎(Scrapy):用来处理整个系统的数据流处理, 触发事务(框架核心)
调度器(Scheduler):用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader):用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spider):爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(pipelines):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件(Downloader Middlewares):位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应
爬虫中间件(Spider Middlewares):介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middlewares):介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
2、常用功能
1.创建scrapy项目:
scrapy startproject xxx
scrapy genspider baidu baidu.com
scrapy crawl baidu
2.start_requests方法
在启动scrapy项目会默认运行start_requests方法,通过重写这个方法可以实现很多功能
3.配置DUPEFILTER_CLASS
配置DUPEFILTER_CLASS可以达到去重,可以用scrapy的也可以用scrapy-redis的。
4.自动携带cookie
在获取请求时加上参数 meta={'cookiejar': True} 可以实现自动携带cookie,这样就不需要自己写了。
5.通过下载中间件实现代理
在Middlewares.py 里的xxDownloaderMiddleware类中的process_request方法里可以设置代理,设置request.meta['proxy'] 就行
3、scrapy-redis
使用这个首先需要安装redis,这个不说。scrapy-redis常用的设置有如下一些:
1 去重+调度器: 2 REDIS_HOST = '127.0.0.1' # 主机名 3 REDIS_PORT = 6379 # 端口 4 # REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置) 5 REDIS_PARAMS = {} # Redis连接参数 默认:REDIS_PARAMS = {'socket_timeout': 30,'socket_connect_timeout': 30,'retry_on_timeout': True,'encoding': REDIS_ENCODING,}) 6 # REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient' # 指定连接Redis的Python模块 默认:redis.StrictRedis 7 REDIS_ENCODING = "utf-8" 8 9 # 有引擎来执行:自定义调度器 10 # from scrapy_redis.scheduler import Scheduler 11 SCHEDULER = 'scrapy_redis.scheduler.Scheduler' 12 13 SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表) 14 SCHEDULER_QUEUE_KEY = '%(spider)s:requests' # 调度器中请求存放在redis中的key 15 SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 对保存到redis中的数据进行序列化,默认使用pickle 16 SCHEDULER_PERSIST = False # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空 17 SCHEDULER_FLUSH_ON_START = True # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空 18 # SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。 19 SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则,在redis中保存时对应的key 20 SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'# 去重规则对应处理的类 21 DUPEFILTER_DEBUG = False
通过对这些配置进行更改就可以实现scrapy-redis了,当然有些代码还是需要改的。
![[MAC OS] 解压Assets.car获取资源图片](http://upload-images.jianshu.io/upload_images/1616478-674b9308518be167.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)