本篇主要介绍,爬取html数据后,将html的正文内容存储为json或csv格式。
1 json格式存储
选定要爬取的网站后,我们利用之前学过的内容,如:Beautiful Soup、xpath等方式解析,来获取我们希望得到的内容。
1.1 获取数据
首先使用urllib访问页面https://www.lagou.com/zhaopin/Python/?labelWords=label
获取html内容,代码如下:
from urllib import request
try:
url = 'https://www.lagou.com/zhaopin/Python/?labelWords=label'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'}
req = request.Request(url, headers=header)
response = request.urlopen(req).read().decode('utf-8')
except request.URLError as e:
if hasattr(e, 'reason'):
print(e.reason)
elif hasattr(e, 'code'):
print(e.code)通过上面的代码获取了html内容,接下来就要分析html来提取我们需要的内容了。
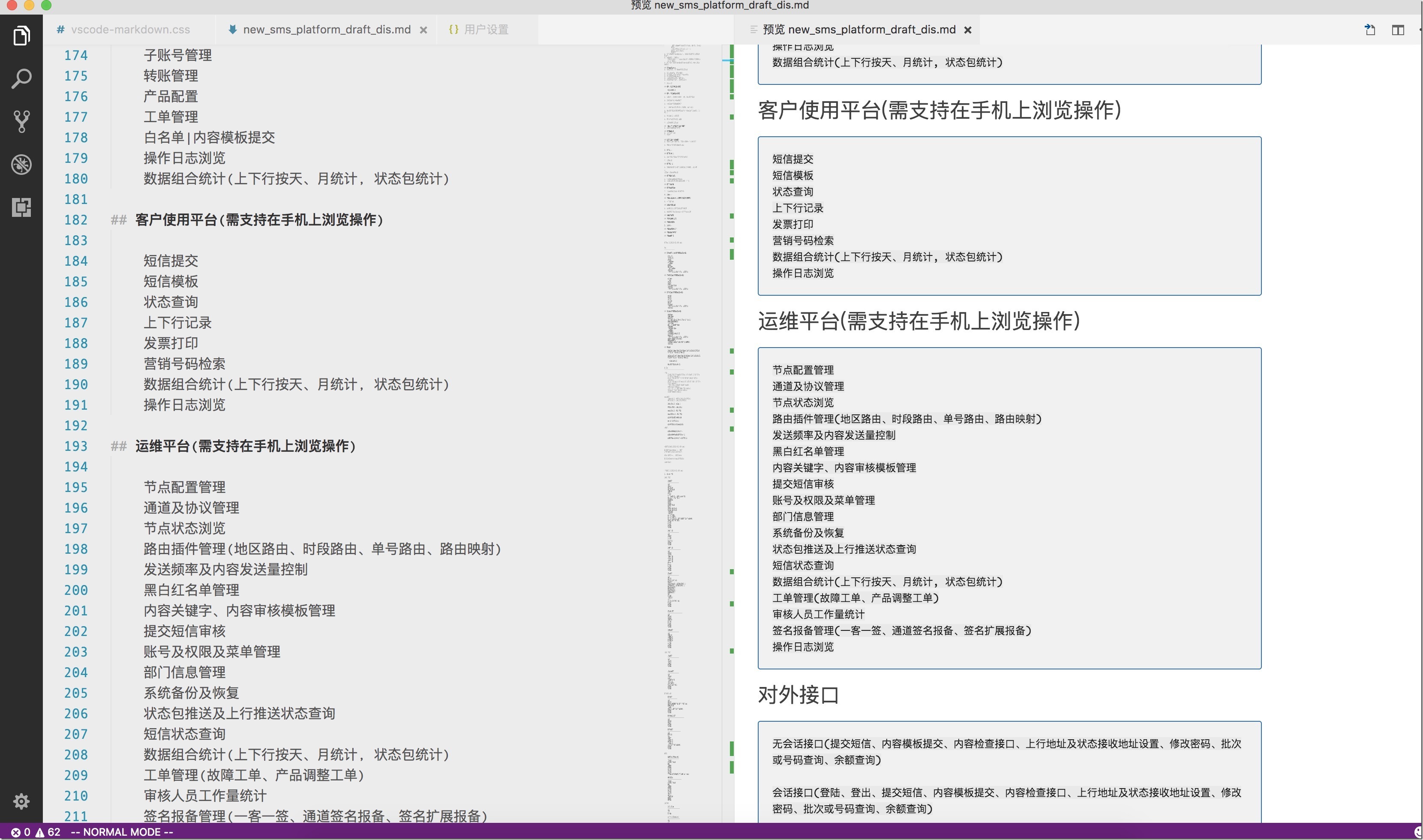
打开拉钩页面,使用ctrl+ F12打开火狐浏览器工具,可以看到我们想要获取的内容,职位、工作地点、薪资、发布的公司等信息都在一个div中,如下图: 爬虫中级篇(五)数据存储(无数据库版)" />
爬虫中级篇(五)数据存储(无数据库版)" />
下一步我们就使用之前介绍过的Beautiful Soup获取这个div内容,同时也可以获取我们需要的内容,通过工具我们可以看到我们需要的内容所在的标签,见下图: 爬虫中级篇(五)数据存储(无数据库版)" />
爬虫中级篇(五)数据存储(无数据库版)" />
# 生成soup实例
soup = BeautifulSoup(response, 'lxml')
# 获取class=‘list_item_top’的div标签
divlist = soup.find_all('div', class_='list_item_top')
# 定义空列表
content = []
# 通过循环,获取需要的内容
for list in divlist:
# 职位名称
job_name = list.find('h3').string
# 职位详细页面
link = list.find('a', class_="position_link").get('href')
# 招聘的公司
company = list.find('div', class_='company_name').find('a').string
# 薪水
salary = list.find('span', class_='money').string
print(job_name, company, salary, link)
content.append({'job': job_name, 'company': company, 'salary': salary, 'link': link})都是通过Beautiful Soup的方法获取的内容,如果不懂,大家可以翻翻之前的工具篇。输出的内容如下:
Python 开发工程师 还呗-智能信贷领先者 10k-15k https://www.lagou.com/jobs/2538412.html
Python开发工程师 天玑科技 10K-20K https://www.lagou.com/jobs/3608088.html
Python 兜乐科技 6k-12k https://www.lagou.com/jobs/4015725.html
Python 妙计旅行 8k-16k https://www.lagou.com/jobs/3828627.html
Python工程师 洋钱罐 25k-35k https://www.lagou.com/jobs/3852092.html
Python软件开发工程师 深信服科技集团 15k-20k https://www.lagou.com/jobs/4009780.html
Python开发 问卷网@爱调研 15k-25k https://www.lagou.com/jobs/3899604.html
Python Veeva 25k-35k https://www.lagou.com/jobs/3554732.html
python工程师 多麦 10k-20k https://www.lagou.com/jobs/3917781.html
python工程师 北蚁 8k-12k https://www.lagou.com/jobs/3082699.html
python研发工程师 数美 15k-30k https://www.lagou.com/jobs/3684787.html
python开发工程师 紫川软件 12k-19k https://www.lagou.com/jobs/3911802.html
python开发工程师 老虎证券 20k-40k https://www.lagou.com/jobs/3447959.html
Python开发 印孚瑟斯 10k-20k https://www.lagou.com/jobs/3762196.html
Python工程师 江苏亿科达 10k-20k https://www.lagou.com/jobs/3796922.html好,数据有了,就差存储了。
1.2 数据存储(json)
python通过json模块对数据进行编码和解码。编码过程是,通过json模块的dumps和dump对数据进行python对象到json对象的转换,解码过程是,通过json模块的loads和load对数据进行json对象到python对象的转换。
编码
dump将python 对象序列化为一个JSON格式的流,存储到文件,转换时类型变化如下: 爬虫中级篇(五)数据存储(无数据库版)" />
爬虫中级篇(五)数据存储(无数据库版)" />
json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
dumps将obj序列化为JSON格式的str
json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
解码
load对Python对象进行反序列化,可以从文件读取
json.load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
 爬虫中级篇(五)数据存储(无数据库版)" />
爬虫中级篇(五)数据存储(无数据库版)" />
loads对Python对象进行反序列化
json.loads(s, *, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
了解了json操作,现在就可以把之前获取的拉钩数据存储为json了,见下面代码:
with open('lagou.json', 'w') as fp:
# indent表示缩进,如果输入这个参数,json的数据会按照找个缩进存储
# 如果不设置,则按最紧凑方式存储
json.dump(content, fp=fp, indent=4)好了,存储为json格式就说到这里了。完整代码如下:
# -*- coding: utf-8 -*-
import json
from bs4 import BeautifulSoup
from urllib import request
try:
url = 'https://www.lagou.com/zhaopin/Python/?labelWords=label'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'}
req = request.Request(url, headers=header)
response = request.urlopen(req).read().decode('utf-8')
except request.URLError as e:
if hasattr(e, 'reason'):
print(e.reason)
elif hasattr(e, 'code'):
print(e.code)
# 生成soup实例
soup = BeautifulSoup(response, 'lxml')
# 获取class=‘list_item_top’的div标签
divlist = soup.find_all('div', class_='list_item_top')
# 定义空列表
content = []
# 通过循环,获取需要的内容
for list in divlist:
# 职位名称
job_name = list.find('h3').string
# 职位详细页面
link = list.find('a', class_="position_link").get('href')
# 招聘的公司
company = list.find('div', class_='company_name').find('a').string
# 薪水
salary = list.find('span', class_='money').string
print(job_name, company, salary, link)
content.append({'job': job_name, 'company': company, 'salary': salary, 'link': link})
with open('lagou.json', 'w') as fp:
# indent表示缩进,如果输入这个参数,json的数据会按照找个缩进存储
# 如果不设置,则按最紧凑方式存储
json.dump(content, fp=fp, indent=4)2 csv格式存储
所谓的CSV(Comma Separated Values)格式是电子表格和数据库最常用的导入和导出格式。
python的csv模块实现类以csv格式读取和写入表格数据。它允许程序员说,“以Excel的格式编写这些数据”,或者“从Excel生成的文件中读取数据”,而不知道Excel使用的CSV格式的详细信息。程序员还可以描述其他应用程序所理解的CSV格式,或者定义他们自己的专用CSV格式。
写数据到csv文件中
# -*- coding: utf-8 -*-
import csv
# 定义第一行
header = ['id', 'name']
# 2条数据
d1 = [1, "xiaoming"]
d2 = [2, "lucy"]
# 打开csv文件,newline作用是去掉空行,不加结果之间会有一个空行
with open('test.csv', 'w', newline='') as f:
# 建立写入对象
writer = csv.writer(f)
# 写入数据
writer.writerow(header)
writer.writerow(d1)
writer.writerow(d2)生成的csv文件内容如下:
id,name
1,xiaoming
2,lucy写字典到csv文件
import csv
with open('names.csv', 'w', newline='') as csvfile:
# 定义名称,也就是header
fieldnames = ['first_name', 'last_name']
# 直接将fieldnames写入,写入字典使用DictWriter方法
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# 调用writeheader方法加入header
writer.writeheader()
# 写入字典数据
writer.writerow({'first_name': 'Baked', 'last_name': 'Beans'})
writer.writerow({'first_name': 'Lovely', 'last_name': 'Spam'})
writer.writerow({'first_name': 'Wonderful', 'last_name': 'Spam'})获取的csv文件内容如下:
first_name,last_name
Baked,Beans
Lovely,Spam
Wonderful,Spam读取csv文件
# -*- coding: utf-8 -*-
import csv
with open('xingming.csv', 'r') as f:
# 创建reader对象
reader = csv.reader(f)
# reader是可迭代对象,可以通过for循环获取内容
for row in reader:
print(row)结果如下:
['id', 'name']
['1', 'xiaoming']
['2', 'lucy']以字典形式读入csv文件
import csv
with open('names.csv', 'r') as f:
# 定义字典阅读对象
reader = csv.DictReader(f)
# 打印第一行名称
print(reader.fieldnames)
# 循环打印字典内容
for row in reader:
print(row['first_name'], row['last_name'])输出结果:
['first_name', 'last_name']
Baked Beans
Lovely Spam
Wonderful Spam所以爬取拉钩网数据,如果存储到csv文件的代码如下:
# -*- coding: utf-8 -*-
import csv
from bs4 import BeautifulSoup
from urllib import request
try:
url = 'https://www.lagou.com/zhaopin/Python/?labelWords=label'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'}
req = request.Request(url, headers=header)
response = request.urlopen(req).read().decode('utf-8')
except request.URLError as e:
if hasattr(e, 'reason'):
print(e.reason)
elif hasattr(e, 'code'):
print(e.code)
# 生成soup实例
soup = BeautifulSoup(response, 'lxml')
# 获取class=‘list_item_top’的div标签
divlist = soup.find_all('div', class_='list_item_top')
# 定义空列表
content = []
# 通过循环,获取需要的内容
for list in divlist:
# 职位名称
job_name = list.find('h3').string
# 职位详细页面
link = list.find('a', class_="position_link").get('href')
# 招聘的公司
company = list.find('div', class_='company_name').find('a').string
# 薪水
salary = list.find('span', class_='money').string
# print(job_name, company, salary, link)
content.append({'job': job_name, 'company': company, 'salary': salary, 'link': link})
with open('lagou.csv', 'a', newline='') as f:
# 定义header
fieldnames = ['job', 'company', 'salary', 'link']
# 通过DictWriter方法写入字典
writer = csv.DictWriter(f, fieldnames=fieldnames)
# 写入header
writer.writeheader()
# 循环获取content内容,写入csv文件
for row in content:
writer.writerow(row)获取的数据如下: 爬虫中级篇(五)数据存储(无数据库版)" />
爬虫中级篇(五)数据存储(无数据库版)" />
哎呦!突然发现今天的例子还是存为csv格式合适,找工作新技能,你get了吗~!
转载于:https://blog.51cto.com/linuxliu/2058923