最近做了猫眼爬虫和数据分析,收获很多,记录在此。爬虫和数据分析是两个模块,可以参考目录:
目录
一、猫眼爬虫
1. 猫眼爬虫第一步——找到我们需要的数据
2. 猫眼爬虫第二步——获取数据
3. 猫眼爬虫第三步——解析数据
4. 猫眼爬虫第四步——存储文件
数据分析是第二块,以后有空了再更新。
一、猫眼爬虫
1. 猫眼爬虫第一步——找到我们需要的数据
打开网站猫眼验证中心:https://www.maoyan.com/board/4, 就是我们想要爬的页面了。
按F12打开开发工具,以便定位我们需要的元素的标签。
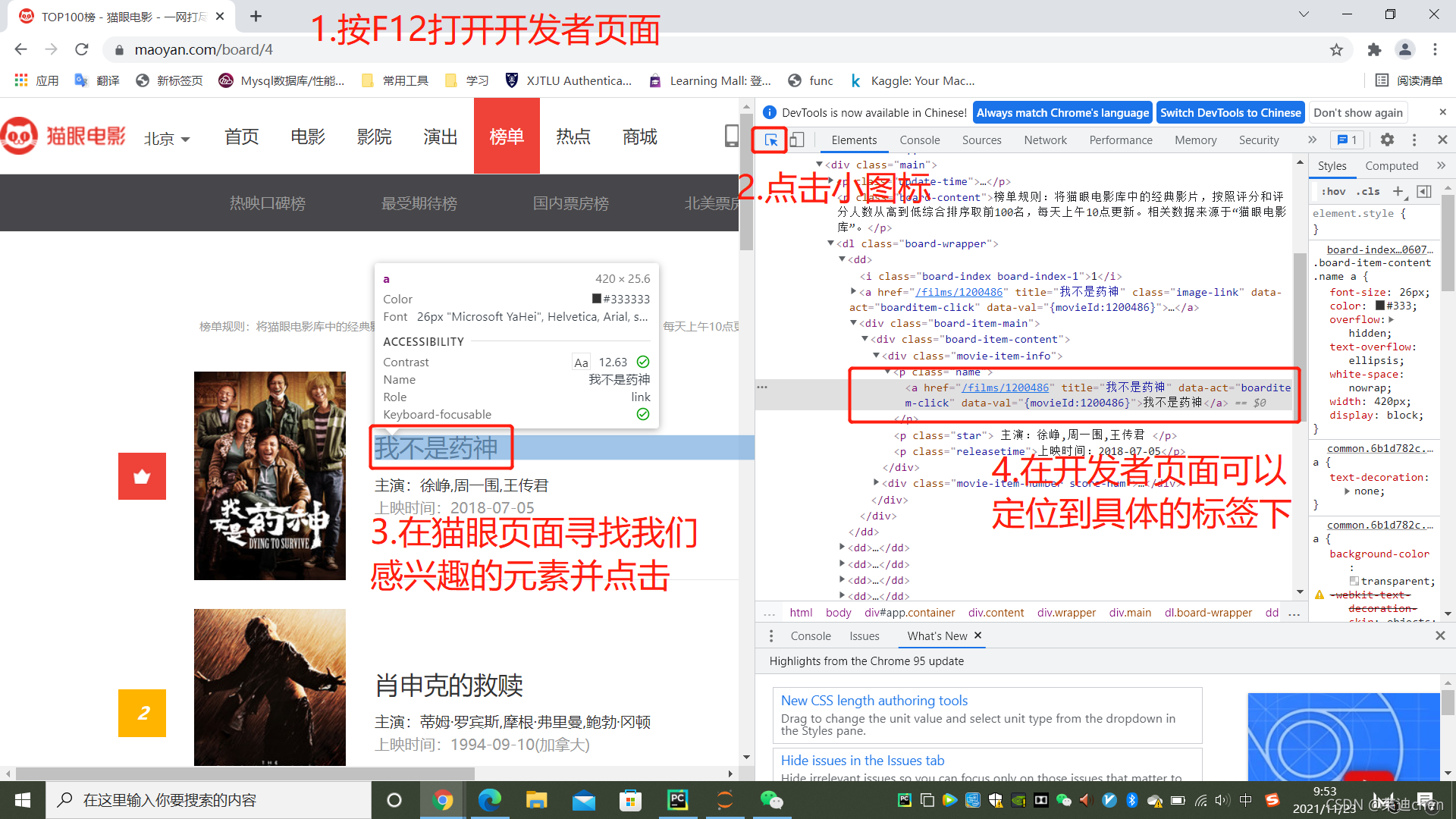
Tips: 可以按control+U打开HTML页面进行定位,更清晰,可以打开的页面如下:
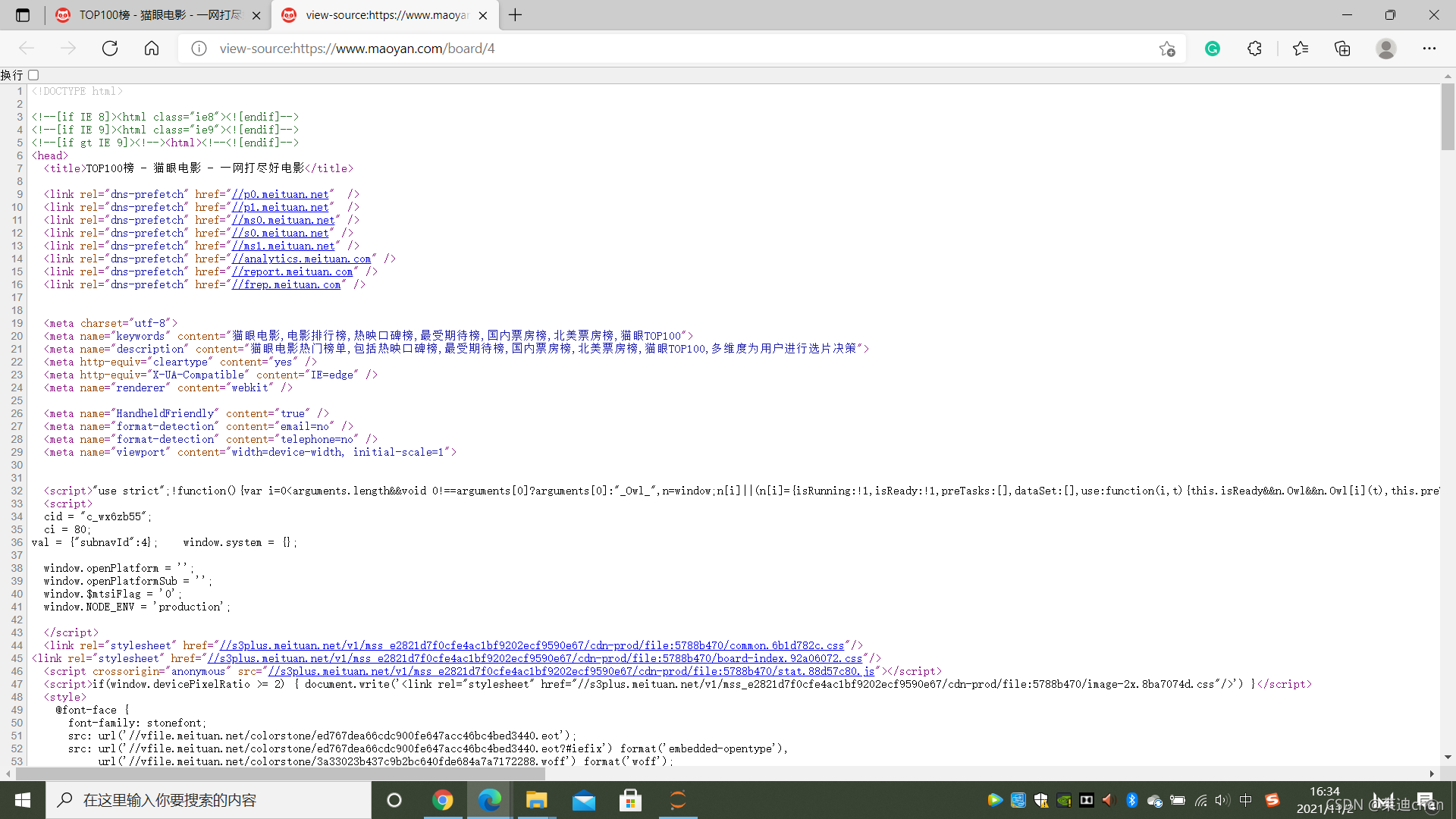
用control + F 可以快速定位,找到我们需要的元素,这个页面不是必须打开的,只是打开看更清晰,看各个标签的关系很清楚。
用此方法我们可以确定我们需要什么数据以及它们的位置在哪里,接下来开始获取这些数据。
2. 猫眼爬虫第二步——获取数据
先导入我们需要的库:
python"># for data scraping
#encoding:utf-8
import requests
from bs4 import BeautifulSoup
import time as ti
import csv
from lxml import etree
import re
# for data analyzing
import pandas as pd接下来获取数据,代码如下:
python">#Part I: camouflage and request response:
def get_html(url):
#Because many web pages have anti crawlers, we add hearders disguise
#In the cat's eye movie web page -- F12 -- Network -- all -- 4 -- header -- find the user agent
#Copy and paste the content
headers = { # 设置header
'Accept' : 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding' : 'gzip, deflate, br',
'Accept-Language' : 'zh-CN,zh;q=0.9',
'Cache-Control' : 'no-cache',
'Connection' : 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Edg/94.0.992.50',
'referer' : 'https://passport.meituan.com/',
'Cookie' : '__mta=42753434.1633656738499.1634781127005.1634781128998.34; uuid_n_v=v1; _lxsdk_cuid=17c5d879290c8-03443510ba6172-6373267-144000-17c5d879291c8; uuid=60ACEF00317A11ECAAC07D88ABE178B722CFA72214D742A2849B46660B8F79A8; _lxsdk=60ACEF00317A11ECAAC07D88ABE178B722CFA72214D742A2849B46660B8F79A8; _csrf=94b23e138a83e44c117736c59d0901983cb89b75a2c0de2587b8c273d115e639; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1634716251,1634716252,1634719353,1634779997; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1634781129; _lxsdk_s=17ca07b2470-536-b73-84%7C%7C12'
}
#The purpose of responding to the request, combined with the disguise of hearders, is to let the server know that this is not a crawler, but a person
#Get website information using get
result = requests.get(url, headers = headers)
#Because the crawler is fast, the server may make an error 403
#Write a judgment, 200 is success
if result.status_code == 200:
#The response is successful and a string is returned
return result.text
returnheaders的目的是让网站不要把我们的爬虫程序当成爬虫,而是当成人的行为。设置方法就是猫眼主页--F12--Network -- all -- 4 -- header -- 找到对应信息复制粘贴过来。其实headers不是必须加的,只是为了防止猫眼反爬,一般只加user agent就够了,但是我当时还是被反爬了,同学建议我多写些信息,所以就加的很详细。
以上就可以获得HTML页面的全部信息了。
3. 猫眼爬虫第三步——解析数据
在获得HTML页面的信息后,我们需要解析HTML内容,定位提取我们需要的信息,代码如下:
python">def parsing_html(html):
ti.sleep(1)
#patter = re.compile('<dd>.*?board-index')
bsSoup = BeautifulSoup(html, 'html.parser')
#a = [x.find("i").text for x in bsSoup.find_all("dd")]
movies = bsSoup.find_all("dd")
a = []
for i in movies:
ti.sleep(0.1)
rating = i.find('i').text
title = i.find("a").get("title")
actors = re.findall("主演:(.*)",i.find("p",class_ = "star").text)[0]
time = re.findall("上映时间:(.*)",i.find("p",class_ = "releasetime").text)[0]
url1 = "https://maoyan.com" + i.find("p",class_ = "name").a.get("href")
score = i.find("i",class_ = "integer").text + i.find("i",class_ = "fraction").text
movie = get_html(url1)
bsMovie = BeautifulSoup(movie, 'html.parser')
#print(bsMovie)
director = bsMovie.find("a",class_= "name").text.replace("\n","").replace(" ","")
income = bsMovie.find_all("div", class_= "mbox-name")
income = income[-2].text if income else "暂无"
location_and_duration = bsMovie.find("div", class_="movie-brief-container").find_all("li", class_="ellipsis")[1].text.split('/')
duration = location_and_duration[1].strip()
location = location_and_duration[0].strip()
ti.sleep(0.5)
m_type_list = [t.text.strip() for t in bsMovie.find("div", class_="movie-brief-container").find("li", class_="ellipsis").find_all("a",class_="text-link")]
m_type = ','.join(m_type_list)
ti.sleep(0.2)
#print(m_type)
c = {'Rating' : rating,
'Title' : title,
'Name of director' : director,
'Name of actors' : actors,
'Cumulative income' : income,
'Duration': duration,
'Type' : m_type,
'Country or a Region' : location,
'Release time' : time,
'Web link' : url1,
'Score' : score
}
a.append(c)
return a4. 猫眼爬虫第四步——存储文件
现在我们的需要的信息以及可以爬出来了,我们需要把这些信息储存到文件里:
python">def write_to_file(content):
with open('maoyan.csv','a',encoding='utf-8-sig')as csvfile:
writer = csv.writer(csvfile)
values = list(content.values())
writer.writerow(values)因为我们是想爬前100的信息,可是一页只有十个电影的信息,这个时候就需要循环十次,才可以爬完 100个电影信息:
python">def next_page(offset):
url = 'http://maoyan.com/board/4?offset='+str(offset)
html = get_html(url)
for item in parsing_html(html):
print(item)
write_to_file(item)注意我这里用了print,把写入文件的信息也打印出来了,这样方便我自己看结果来进行调整。
调用以上函数,并循环十次:
python">for i in range(10):
next_page(offset=10*i)
ti.sleep(1)运行结果被打印出来了:
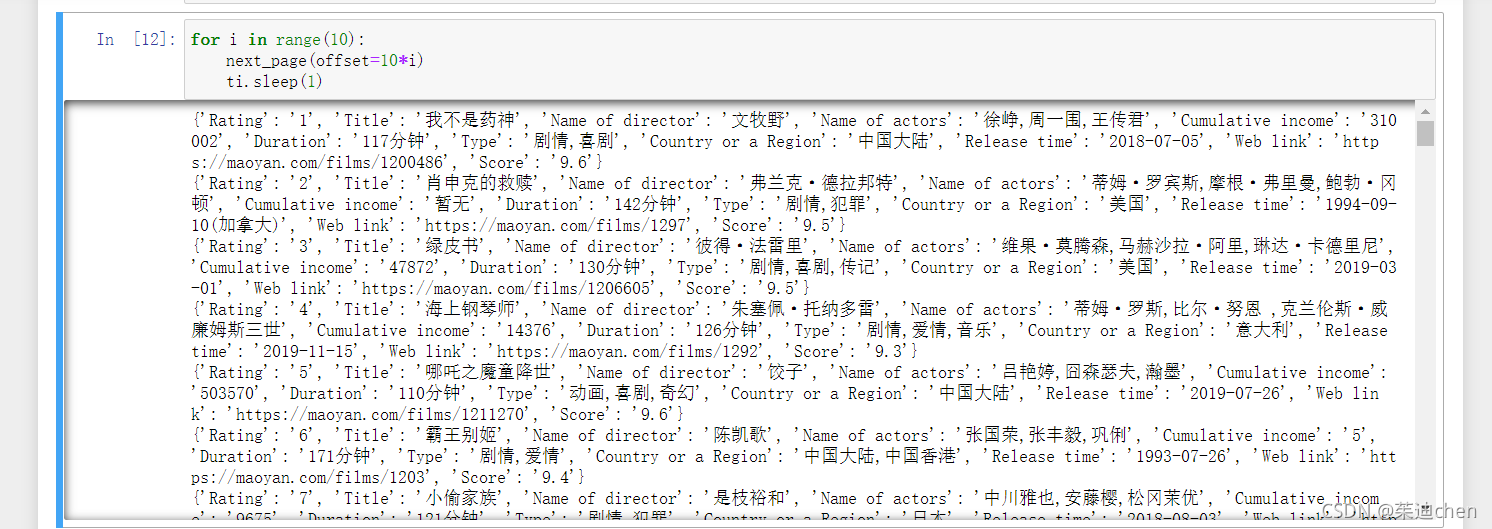
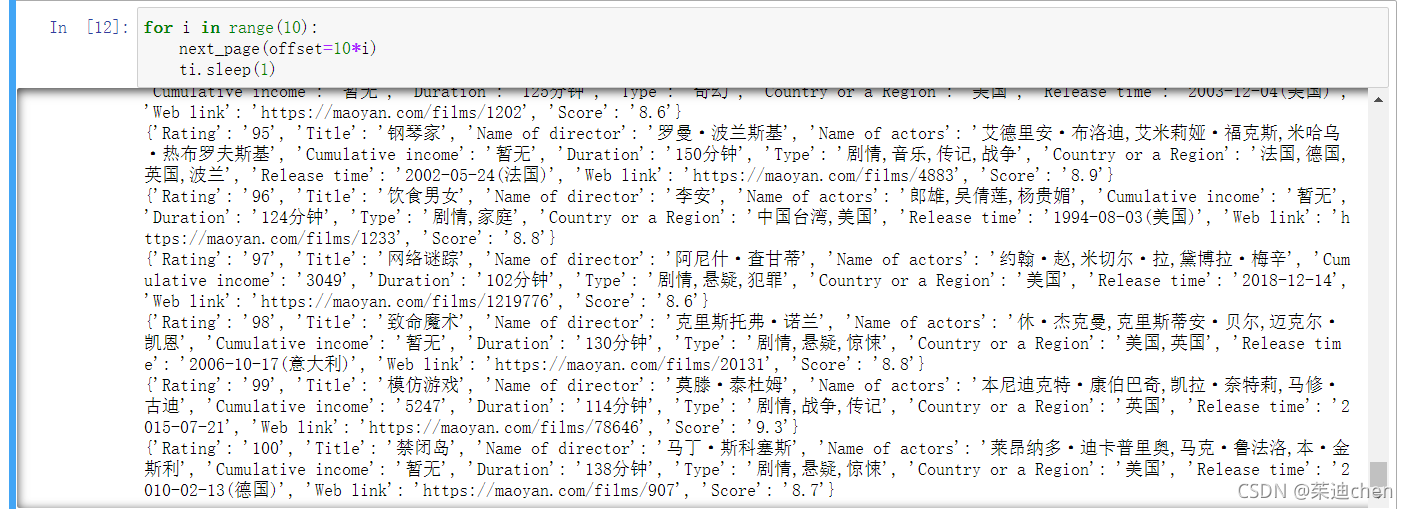 正好一百条信息,是我们想要的结果!
正好一百条信息,是我们想要的结果!
我们给爬出来的信息写一个表头,方便我们查询:
python">df = pd.read_csv("maoyan.csv", header=None, index_col=None)
df.columns = ['Rating',
'Title',
'Name_of_director',
'Name_of_actors',
'Cumulative_income',
'Duration',
'Type',
'Country_or_a_Region',
'Release_time',
'Web_link',
'Score']
df.to_csv("maoyan.csv", index=False)在文件夹中打开我们刚刚写入的文件,效果如下:
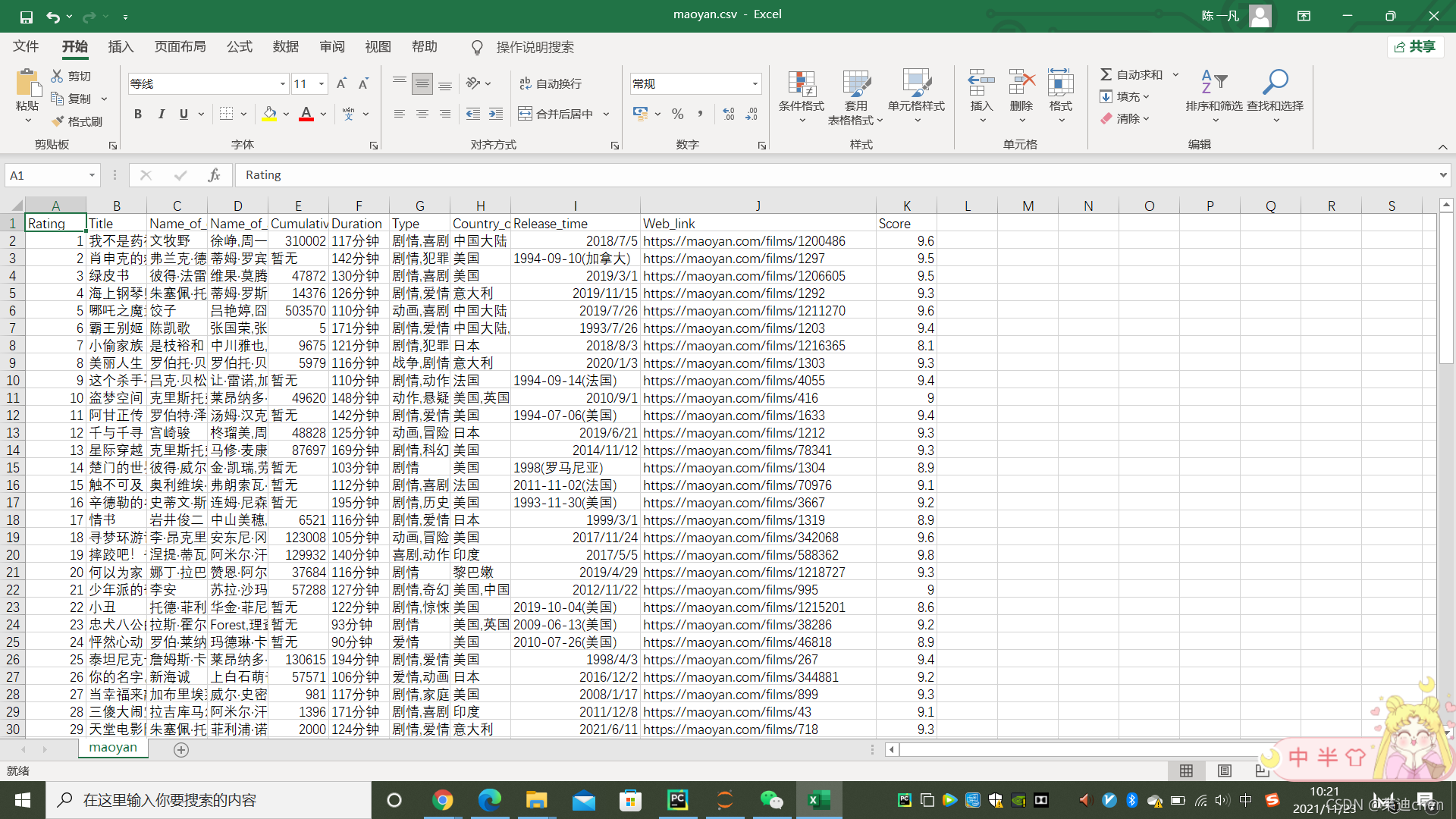 效果很好,爬虫部分结束!
效果很好,爬虫部分结束!