这篇文章我们将以 百度翻译 为例,分析网络请求的过程,然后使用 urllib 编写一个英语翻译的小模块
1、准备工作
首先使用 Chrome 浏览器打开 百度翻译,这里,我们选择 Chrome 浏览器自带的开发者工具对网站进行抓包分析
2、抓包分析
打开 Network 选项卡进行监控,并选择 XHR 作为 Filter 进行过滤
然后,我们在输入框中输入待翻译的文字进行测试,可以看到列表中出现三个数据包
分别是 sug、v2transapi 和 langdetect,下面我们一个一个进行分析
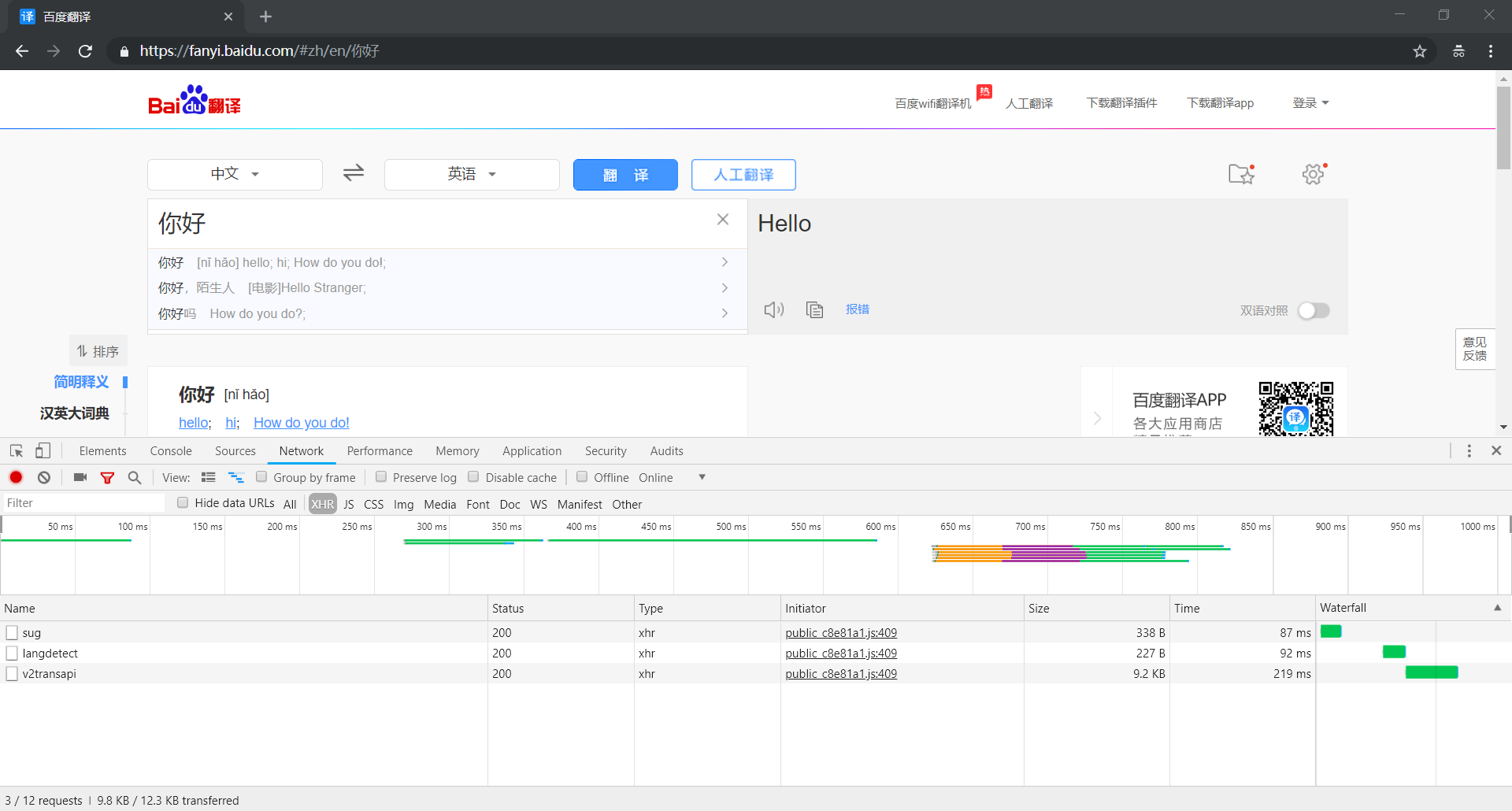
(1)分析 sug 数据包
① 打开 sug 数据包的 Preview 选项卡查看响应结果,太棒了,里面有我们需要的翻译结果
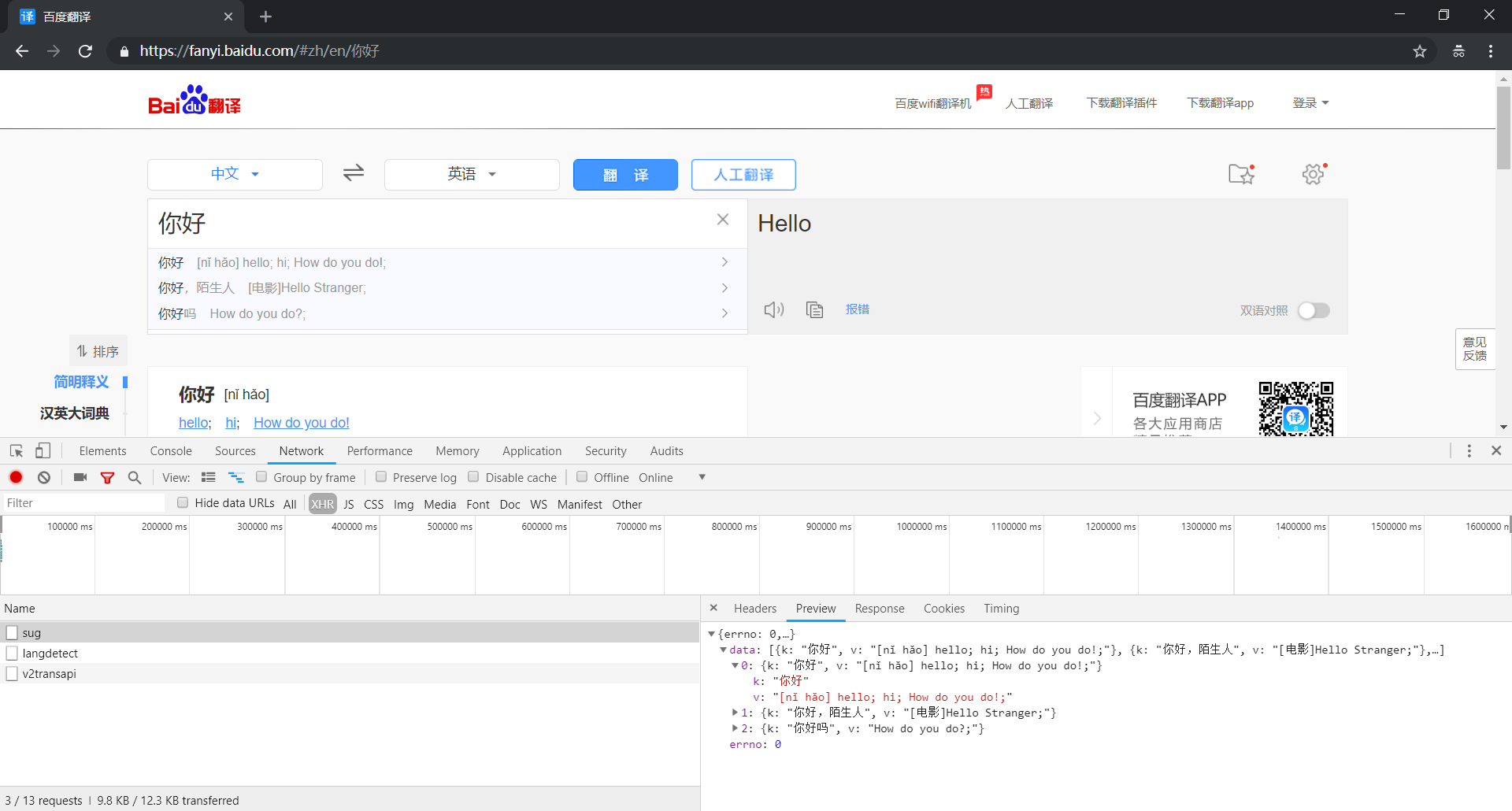
② 然后,我们可以打开 sug 数据包的 Headers 选项卡分析请求数据,使用程序模拟发送请求,基本信息如下:
- General:基本参数
Request URL : https://fanyi.baidu.com/sug—— 请求网址Request Method : POST—— 请求方法,POST 请求方法的请求参数放在 Form Data 中
- Request Headers:请求头部
User-Agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36—— 用户代理
- Form Data:表单数据
kw : 你好—— 翻译的内容
③ 下面祭上完整的代码
python">import urllib.request
import urllib.parse
import json
def translate(text):
# 参数检验
if not text:
return 'None'
# 请求网址
url = "https://fanyi.baidu.com/sug"
# 表单数据
params = {
'kw':text
}
data = urllib.parse.urlencode(params).encode('utf-8')
# 请求头部
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 构造请求对象
req = urllib.request.Request(url=url,data=data,headers=headers)
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 解析数据
content = json.loads(response.read().decode('utf-8'))
if content['errno'] == 0: # 一切正常
result = content['data'][0]['v']
else: # 发生错误
result = 'Error'
# 返回结果
return result
if __name__ == "__main__":
while True :
text = input('翻译内容:')
result = translate(text)
print("翻译结果:%s" % result)OK,一切完美解决!
等等,真的就这样结束了吗?
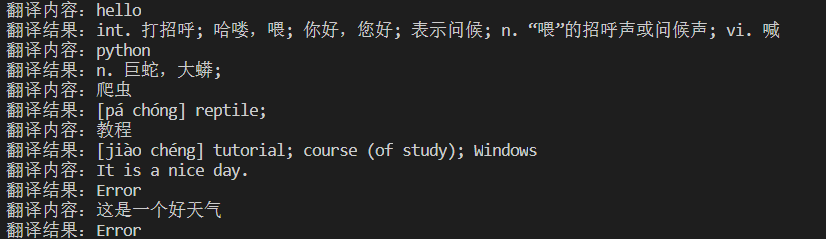
可以看到,上面的代码虽然可以完美翻译中文和英文,但是却不能翻译句子!
这可怎么办呀?别急,不是还有两个数据包没有分析嘛,再看看还有没有其它办法吧
(2)分析 v2transapi 数据包
① 打开 v2transapi 数据包的 Preview 选项卡查看响应结果,这里面竟然也有我们需要的翻译结果
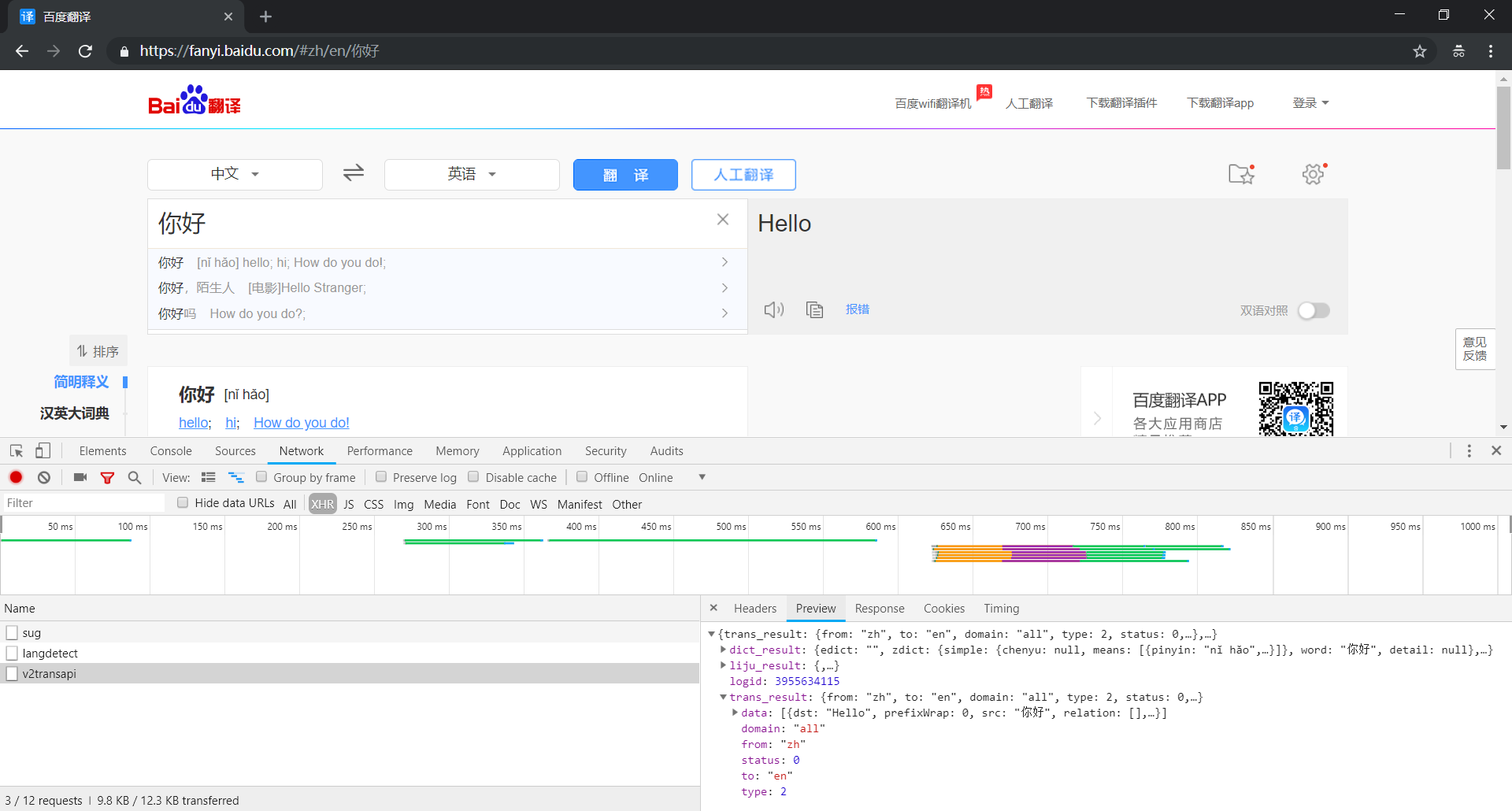
② 接下来,我们还是打开 v2transapi 数据包的 Headers 选项卡查看请求数据,其基本信息如下:
- General:基本参数
Request URL : https://fanyi.baidu.com/v2transapi—— 请求网址Request Method : POST—— 请求方法,POST 请求方法的请求参数放在 Form Data 中
- Request Headers:请求头部
User-Agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36—— 用户代理
- Form Data:表单数据
query : 你好—— 翻译的内容from : zh—— 翻译内容的语言类型,zh 代表中文,设置为 auto 可自动检测to : en—— 翻译结果的语言类型,en 代表英文,设置为 auto 可自动检测sign和token:加密参数
唉,只想简简单单爬个翻译,竟然还要涉及密码破解,没办法,只好请教百度了
一查才知道,原来百度翻译有一个公开的 API,根本就不需要涉及加密解密
只需要把上面的请求地址改成 https://fanyi.baidu.com/transapi 就可以了
③ 下面同样祭上完整的代码,其实和上面的十分类似
python">import urllib.request
import urllib.parse
import json
def translate(text):
# 参数检验
if not text:
return 'None'
# 请求网址
url = "https://fanyi.baidu.com/transapi"
# 表单数据
params = {
'query':text,
'from':'auto',
'to':'auto'
}
data = urllib.parse.urlencode(params).encode('utf-8')
# 请求头部
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 构造请求对象
req = urllib.request.Request(url=url,data=data,headers=headers)
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 解析数据
content = json.loads(response.read().decode('utf-8'))
result = content['data'][0]['dst']
# 返回结果
return result
if __name__ == "__main__":
while True :
text = input('翻译内容:')
result = translate(text)
print("翻译结果:%s" % result)下面我们来看看效果如何?

嗯,效果还可以,终于也能够翻译句子了!
3、相关拓展
有道翻译的爬取和百度翻译的十分类似,这里也顺便提及一下
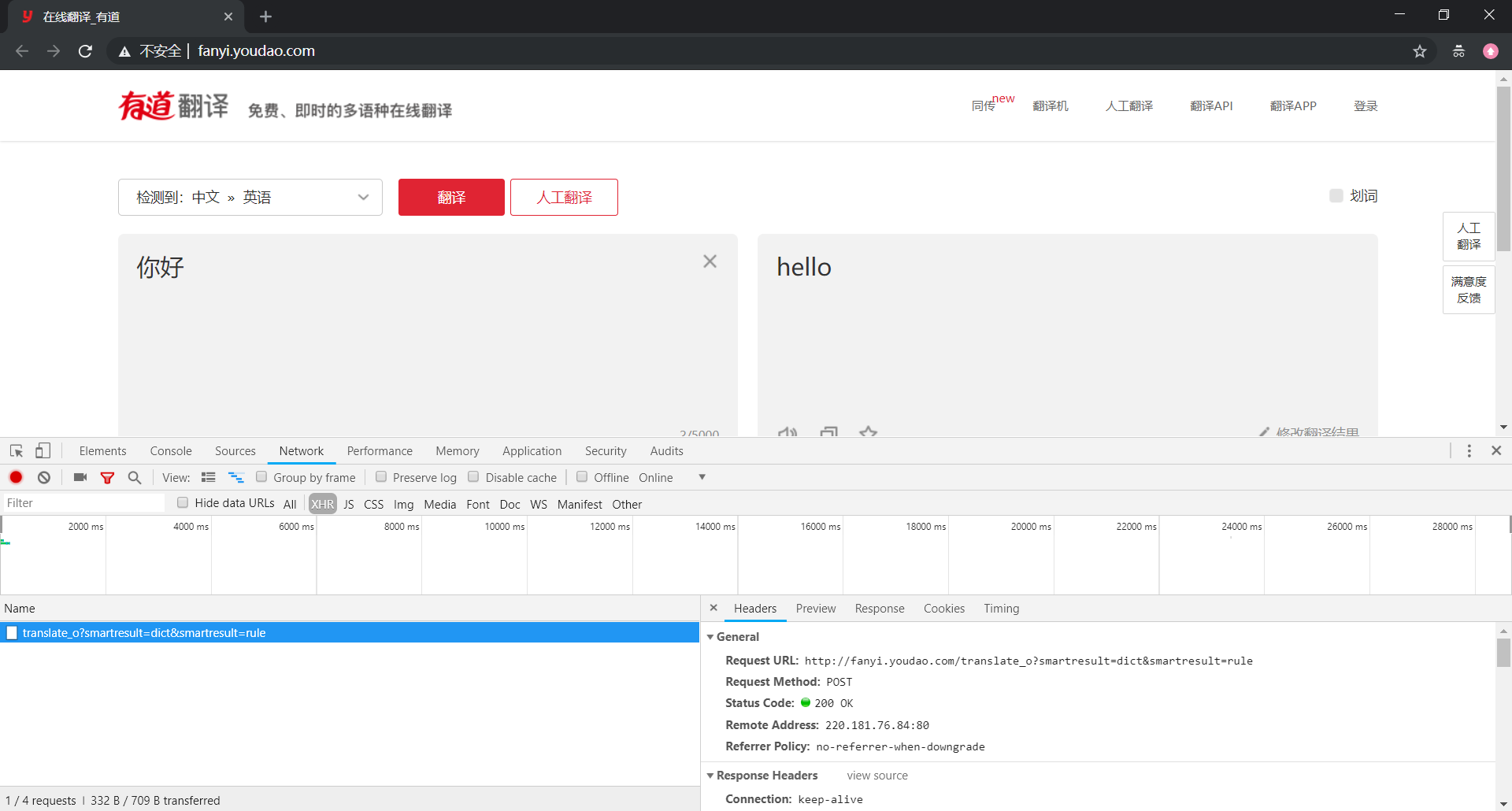
我们还是先来打开数据包的 Headers 选项卡查看请求数据,其基本信息如下:
- General:基本参数
Request URL : http://fanyi.youdao.com/translate_o—— 请求网址Request Method : POST—— 请求方法,POST 请求方法的请求参数放在 Form Data 中
- Request Headers:请求头部
User-Agent : Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36—— 用户代理
- Form Data:表单数据
i: 你好—— 翻译的内容doctype : json—— 数据类型,指定为 JSONfrom : AUTO—— 翻译内容的语言类型,自动检测to : AUTO—— 翻译结果的语言类型,自动检测sign和salt:加密参数
和百度翻译的很类似,都设置了加密参数,怎么办?也和百度翻译类似,修改一下请求地址就好
话不多说,直接放代码:
python">import urllib.request
import urllib.parse
import json
def translate(text):
# 参数检验
if not text:
return 'None'
# 请求网址
url = "https://fanyi.youdao.com/translate"
# 表单数据
params = {
'i':text,
'doctype':'json',
'from':'AUTO',
'to':'AUTO'
}
data = urllib.parse.urlencode(params).encode('utf-8')
# 请求头部
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 构造请求对象
req = urllib.request.Request(url=url,data=data,headers=headers)
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 解析数据
content = json.loads(response.read().decode('utf-8'))
if content['errorCode'] == 0: # 一切正常
result_tup = (item['tgt'] for item in content['translateResult'][0])
result = ''.join(result_tup)
else: # 发生错误
result = 'Error'
# 返回结果
return result
if __name__ == "__main__":
while True :
text = input('翻译内容:')
result = translate(text)
print("翻译结果:%s" % result)效果演示:

【爬虫系列相关文章】