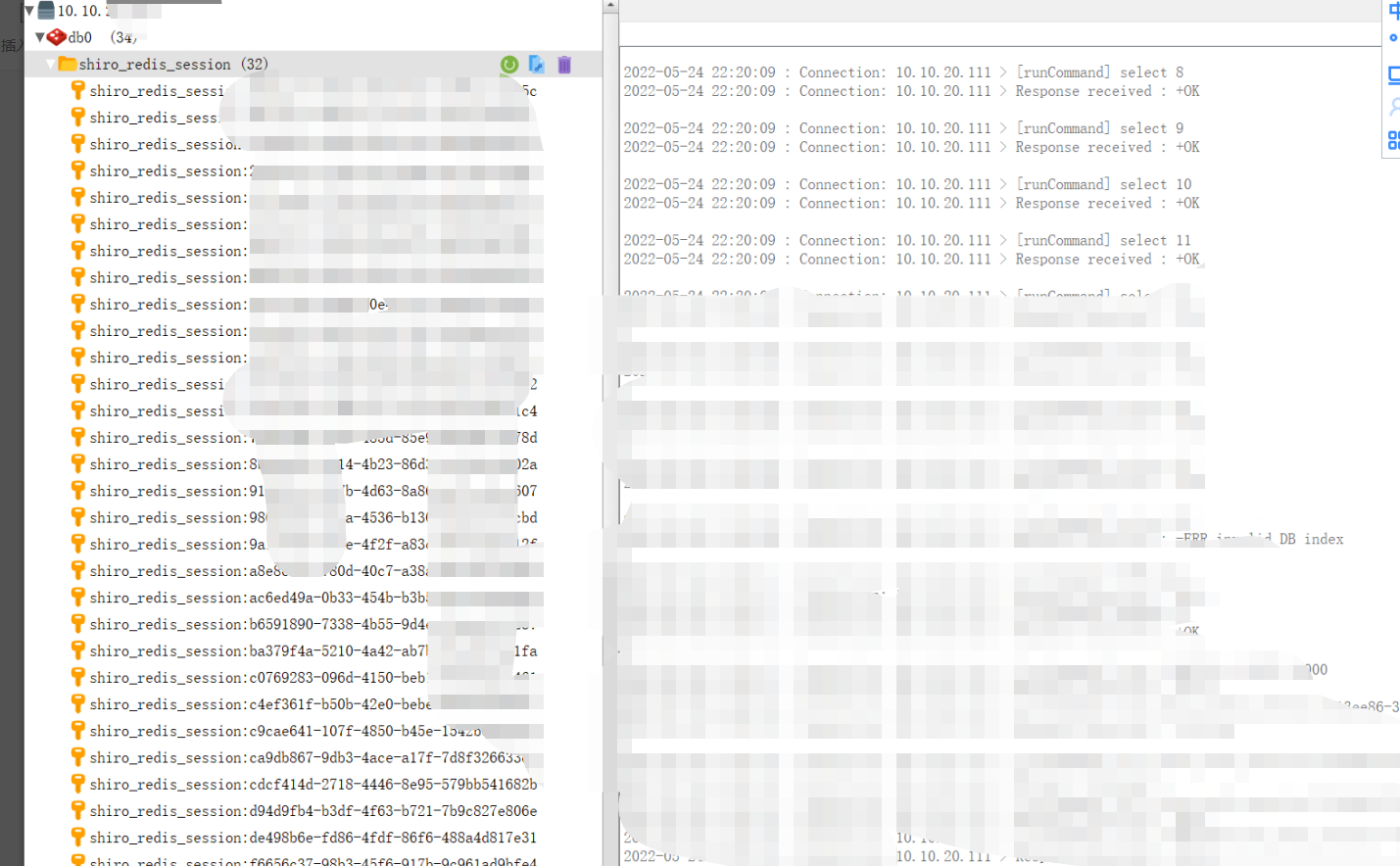
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库。用 Python 编写,真正的为人类着想。
Python 标准库中的 urllib2 模块提供了你所需要的大多数 HTTP 功能,但是它的 API 太渣了。它是为另一个时代、另一个互联网所创建的。它需要巨量的工作,甚至包括各种方法覆盖,来完成最简单的任务。
在Python的世界里,事情不应该这么麻烦。
Requests 使用的是 urllib3,因此继承了它的所有特性。Requests 支持 HTTP 连接保持和连接池,支持使用 cookie 保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码。现代、国际化、人性化。
(以上转自Requests官方文档)
2、Requests模块安装
点此下载
然后执行安装
|
1
|
$ python setup.py install
|
个人推荐使用pip安装
|
1
|
pip install requests
|
也可以使用easy_install安装
|
1
|
easy_install requests
|
尝试在IDE中import requests,如果没有报错,那么安装成功。
3、Requests模块简单入门

#HTTP请求类型
#get类型
r = requests.get('https://github.com/timeline.json') #post类型 r = requests.post("http://m.ctrip.com/post") #put类型 r = requests.put("http://m.ctrip.com/put") #delete类型 r = requests.delete("http://m.ctrip.com/delete") #head类型 r = requests.head("http://m.ctrip.com/head") #options类型 r = requests.options("http://m.ctrip.com/get") #获取响应内容 print r.content #以字节的方式去显示,中文显示为字符 print r.text #以文本的方式去显示 #URL传递参数 payload = {'keyword': '日本', 'salecityid': '2'} r = requests.get("http://m.ctrip.com/webapp/tourvisa/visa_list", params=payload) print r.url #示例为http://m.ctrip.com/webapp/tourvisa/visa_list?salecityid=2&keyword=日本 #获取/修改网页编码 r = requests.get('https://github.com/timeline.json') print r.encoding r.encoding = 'utf-8' #json处理 r = requests.get('https://github.com/timeline.json') print r.json() #需要先import json #定制请求头 url = 'http://m.ctrip.com' headers = {'User-Agent' : 'Mozilla/5.0 (Linux; Android 4.2.1; en-us; Nexus 4 Build/JOP40D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Mobile Safari/535.19'} r = requests.post(url, headers=headers) print r.request.headers #复杂post请求 url = 'http://m.ctrip.com' payload = {'some': 'data'} r = requests.post(url, data=json.dumps(payload)) #如果传递的payload是string而不是dict,需要先调用dumps方法格式化一下 #post多部分编码文件 url = 'http://m.ctrip.com' files = {'file': open('report.xls', 'rb')} r = requests.post(url, files=files) #响应状态码 r = requests.get('http://m.ctrip.com') print r.status_code #响应头 r = requests.get('http://m.ctrip.com') print r.headers print r.headers['Content-Type'] print r.headers.get('content-type') #访问响应头部分内容的两种方式 #Cookies url = 'http://example.com/some/cookie/setting/url' r = requests.get(url) r.cookies['example_cookie_name'] #读取cookies url = 'http://m.ctrip.com/cookies' cookies = dict(cookies_are='working') r = requests.get(url, cookies=cookies) #发送cookies #设置超时时间 r = requests.get('http://m.ctrip.com', timeout=0.001) #设置访问代理 proxies = { "http": "http://10.10.10.10:8888", "https": "http://10.10.10.100:4444", } r = requests.get('http://m.ctrip.com', proxies=proxies)
4、Requests示例
json请求
1 #!/user/bin/env python
2 #coding=utf-8 3 import requests 4 import json 5 6 class url_request(): 7 def __init__(self): 8 """ init """ 9 10 if __name__=='__main__': 11 headers = {'Content-Type' : 'application/json'} 12 payload = {'CountryName':'中国', 13 'ProvinceName':'陕西省', 14 'L1CityName':'汉中', 15 'L2CityName':'城固', 16 'TownName':'', 17 'Longitude':'107.33393', 18 'Latitude':'33.157131', 19 'Language':'CN' 20 } 21 r = requests.post("http://www.xxxxxx.com/CityLocation/json/LBSLocateCity",headers=headers,data=payload) 22 #r.encoding = 'utf-8' 23 data=r.json() 24 if r.status_code!=200: 25 print "LBSLocateCity API Error " + str(r.status_code) 26 print data['CityEntities'][0]['CityID'] #打印返回json中的某个key的value 27 print data['ResponseStatus']['Ack'] 28 print json.dumps(data,indent=4,sort_keys=True,ensure_ascii=False) #树形打印json,ensure_ascii必须设为False否则中文会显示为unicode
xml请求
#!/user/bin/env python
#coding=utf-8
import requests class url_request(): def __init__(self): """ init """ if __name__=='__main__': headers = {'Content-type': 'text/xml'} XML = '<?xml version="1.0" encoding="utf-8"?><soap:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/"><soap:Body><Request xmlns="http://tempuri.org/"><jme><JobClassFullName>WeChatJSTicket.JobWS.Job.JobRefreshTicket,WeChatJSTicket.JobWS</JobClassFullName><Action>RUN</Action><Param>1</Param><HostIP>127.0.0.1</HostIP><JobInfo>1</JobInfo><NeedParallel>false</NeedParallel></jme></Request></soap:Body></soap:Envelope>' url = 'http://jobws.push.mobile.xxxxxxxx.com/RefreshWeiXInTokenJob/RefreshService.asmx' r = requests.post(url,headers=headers,data=XML) #r.encoding = 'utf-8' data = r.text print data
5、参考文档
http://cn.python-requests.org/en/latest/
http://docs.python-requests.org/en/latest/user/quickstart.html