简介
目标站点:https://lol.52pk.com/pifu/hero
实现方式:selenium进行图片信息获取并翻页,requests请求图片的url并保存图片到本地
Python实现
运行程序前,请先确认已经安装了requests、selenium第三方模块,并下载了Chrome浏览器对应的webdriver
python"># coding=utf-8
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
import requests
import time
class HeroPicDown:
def __init__(self):
self.start_url = 'https://lol.52pk.com/pifu/hero/hero_1.shtml'
self.driver = webdriver.Chrome() # 我的chromedriver.exe和该脚本在同一路径,所以我不需要指定可执行文件路径
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36"
}
# 定义起始函数,打开皮肤第一页
def start(self):
self.driver.get(self.start_url)
self.driver.maximize_window()
def parse(self):
try:
wait = WebDriverWait(self.driver, 10) # 设置driver等待时间为10s
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'selectContent'))) # 等待皮肤列表被加载完成
lis = self.driver.find_elements_by_xpath("//div[@class='selectContent']/ul/li") # 获取皮肤列表的li标签
for li in lis:
pic_url = li.find_element_by_xpath("./a/img").get_attribute('src') # 获取皮肤图片的url
title = li.find_element_by_xpath("./a/div/strong").text # 称呼:比如暗夜猎手
name = li.find_element_by_xpath("./a/div/p").text # 名称:比如薇恩
file_name = title + "_" + name + '_' + pic_url.split('/')[-1] # 拼接保存名称
self.down_pic(pic_url, file_name) # 下载图片并保存到指定路径
print(f"第{self.driver.current_url.split('/')[-1].center(100, '=')}页面爬取完毕") # 爬取一页之后打印完成信息
# 定位下一页按钮,并点击
try:
next_page = self.driver.find_element_by_xpath("//*[@id='page__next']/a")
if next_page:
next_page.click()
self.parse()
# 如果最后一页元素不能定位,即已经是最后一页,我们就打印退出信息
except NoSuchElementException as e:
print('已经是最后一页,等待程序结束...')
except Exception as e:
print(e)
# 定义下载图片保存函数
def down_pic(self, pic_url, file_name):
try:
res = requests.get(pic_url, headers=self.headers)
with open(file=r'C:\Users\Administrator\Desktop\Hero pic\%s' % file_name, mode='wb') as f:
f.write(res.content)
print(f'{file_name}下载完毕...')
except Exception as e:
print(e)
# 等待10s关闭浏览器
def close(self):
time.sleep(10)
self.driver.quit()
# 程序入口
if __name__ == '__main__':
start = time.time()
h = HeroPicDown()
h.start()
h.parse()
end = time.time()
print(f'爬虫运行结束,耗时:{end - start}秒')
部分结果展示
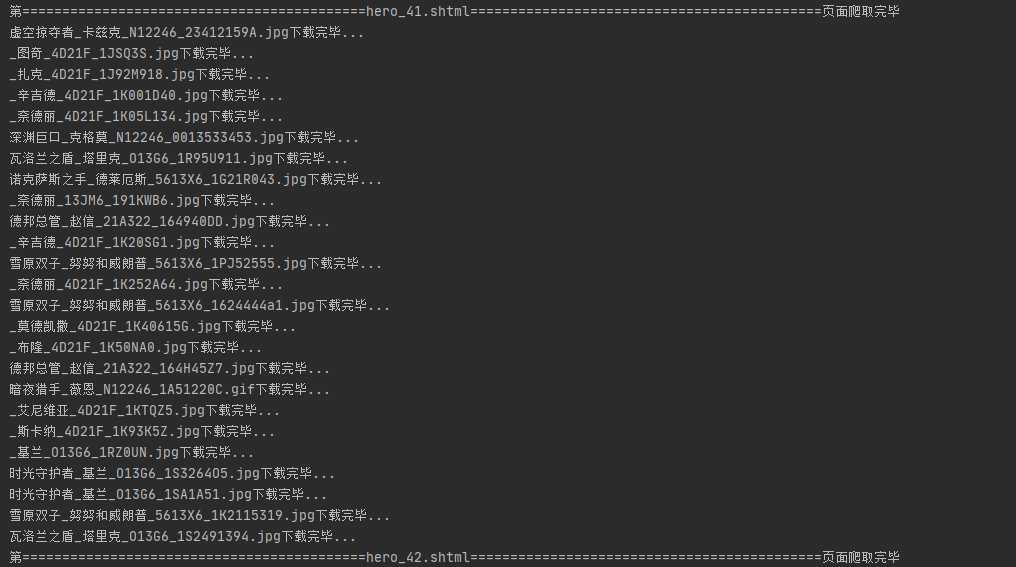
- 程序的打印信息
- 程序执行耗时

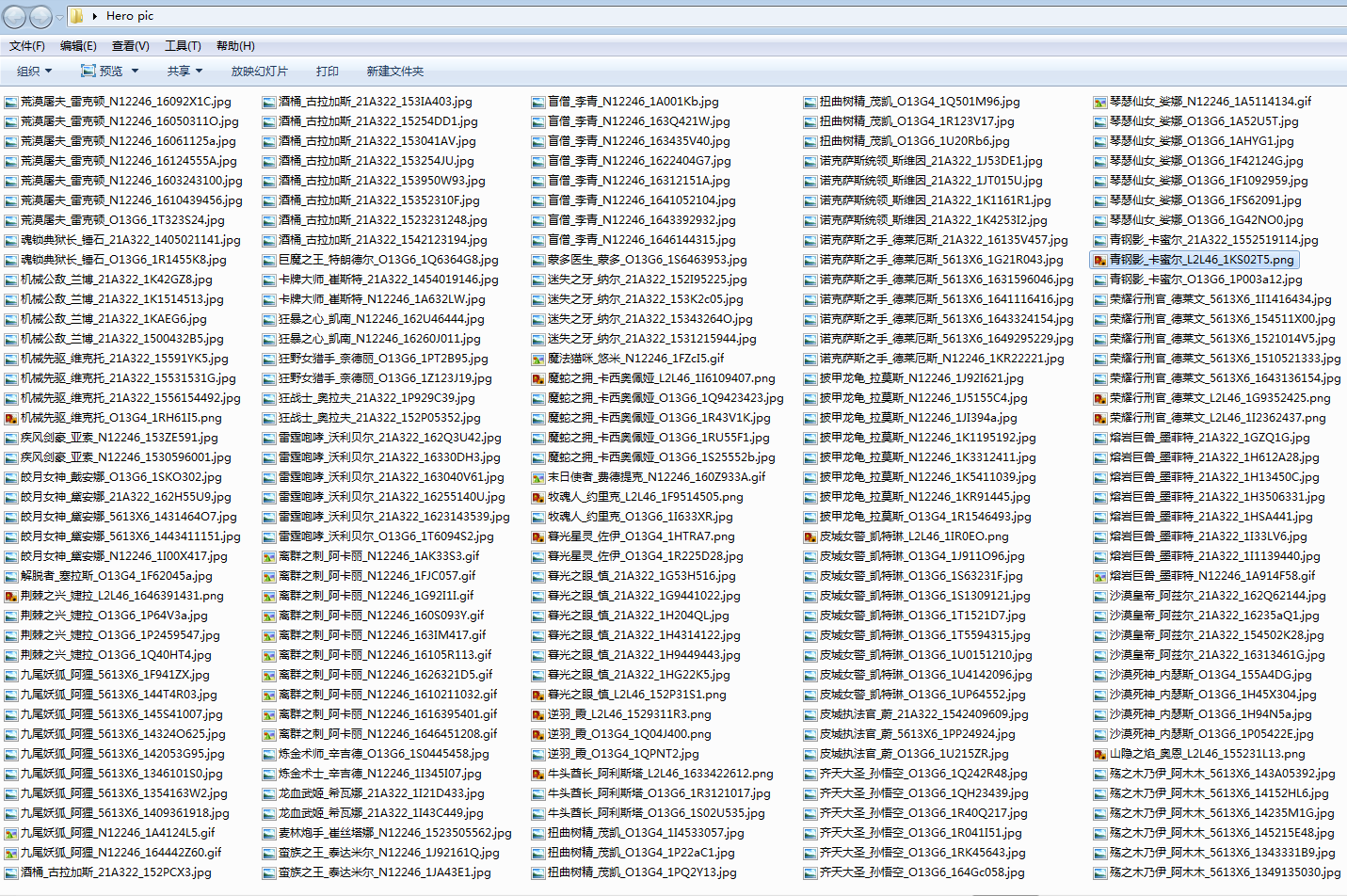
- 保存的图片