闲扯几句
大家好,我是你们的老朋友青戈,之前分享了一篇Java爬虫的入门实战教程,收获了不少赞,看来大家伙对爬虫的热情度还是蛮高的哈。既然大家都这么想学爬虫,那今天就安排点刺激的。那你要非问我有多刺激,那我只能告诉,我看完…流鼻血了…🤪
插播一条反爬信息:本文作者:
程序员青戈,博客:https://blog.csdn.net/xqnode
我知道大家平时工作生活都挺累的,要是程序员的话就更苦逼了,加不完的班,敲不完的bug,着实让老哥我有点心疼啊,那么这期就给大家放一波福利。高能预警!一大批美女即将来袭,请各位朋友们把持住,把持住啊!

啥?看的不过瘾?我就知道你这么说,同样作为兄弟的我非常能理解啊,那么下面这篇教程你得好好看看了,因为这将直接决定你今晚能不能睡个好觉😂
进入主题
今天我们爬取的网站是 唯美女生网 ,我们进来看看
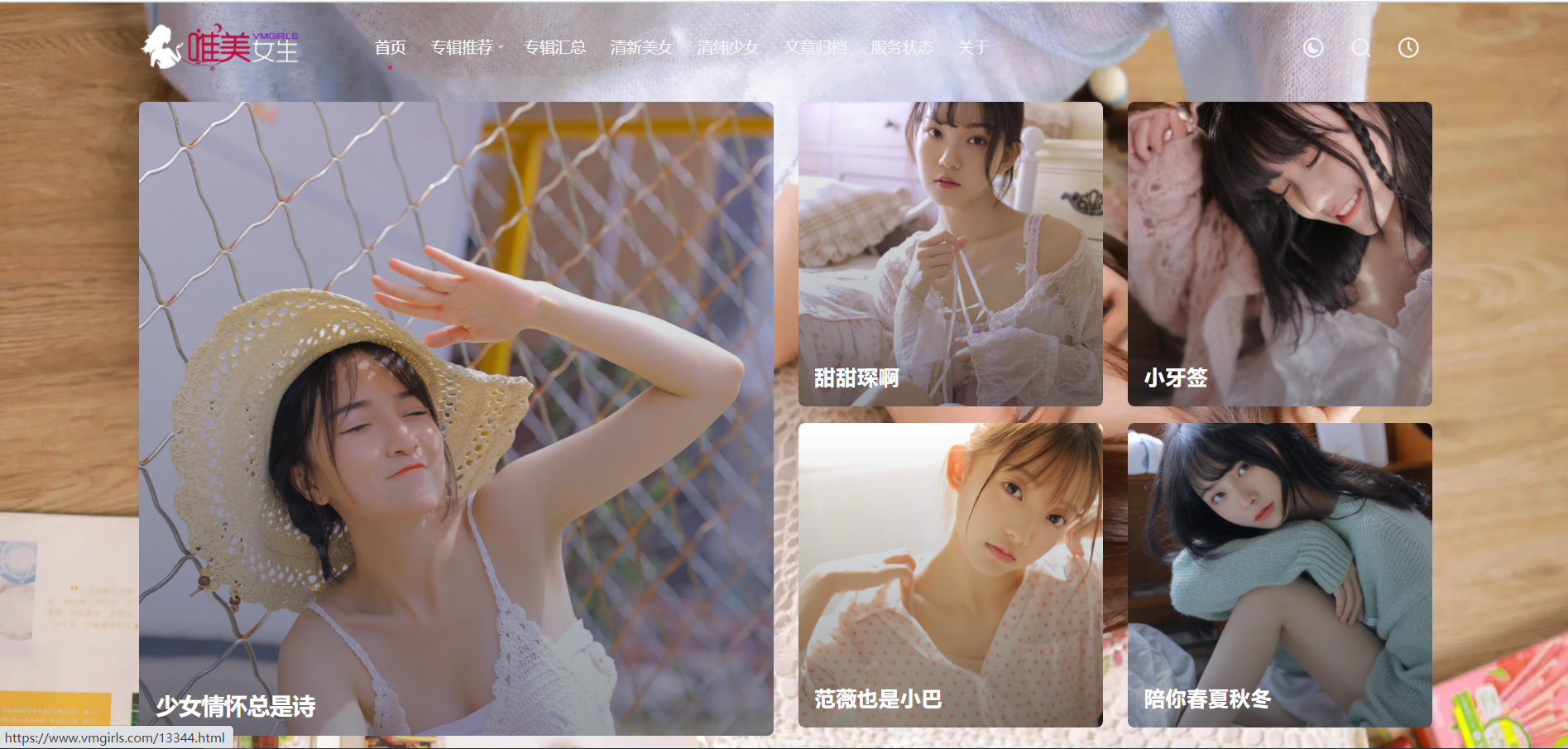
是不是很哇塞?都是好看的小姐姐😎这谁顶得住啊,我就点进去瞅一眼

卧槽?这什么鬼?小姐姐怎么变大妈了!

导演:搞错了,再来!

啊这,为什么让小小年纪的我看到这个?兄弟们,我又相信爱情了!曾经有一段真挚的爱情摆在我的面前,我没有好好珍惜,现在,她回来了,还是那么清纯、羞涩,穿着碎花的裙子,趴在床上向我微笑。
这,不就是青春吗?
这,不就是爱情吗?
还等什么?我来啦!
网页代码分析
回归主题哈,各位,我这个人有个不好的习惯,看到美女就走神,真是抱歉了,差点忘记了今天是来写代码的😅
这个网站的站长估计每天被爬虫的烦死了,服务器顶着巨大的压力,曾经一段时间还频繁宕机。为了解决后患,他干脆关了网页的f12功能,不让看代码了,防止无数的se狼们搞他的小站,毕竟人家也不容易,你们干太猛了,怼太深了,不给人家活路啊
今天我为了写这篇教程,也是花尽了心思啊,想尽办法拿到了他的源码,你们猜我是怎么搞的?
不知道你们观察过没,平时你在看网站源代码的时候,地址栏的前面会多这一段:view-source:,后面跟的就是你实际的网站的地址,比如百度的源码是这样的:view-source:https://www.baidu.com

那么同样的道理,我们也可以使用这个地址看这个网站的源代码,比如:view-source:https://www.vmgirls.com/15215.html

我们从网页的源代码分析可以找到图片的位置,分析得出 a标签的href 属性就是图片的地址:

随便点开看一下,证实我的想法:

OK,确定了图片的位置,那就好办了
开始撸码
还是老规矩,我们继续使用 Jsoup 来进行网页数据抓取,先引入jsoup的包:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
连接目标网页,得到 Document 对象:
java">Document document = Jsoup.connect("https://www.vmgirls.com/15298.html").get();
从Document对象中获取到目标图片所在父级的 div ,获取到这个div之后,事情就简单多了。
我们从这个div中获取所有的a标签,然后判断,a标签的href属性是否包含 jpeg 关键字,如果包含了,那就是我们需要抓取的图片。
java">Elements elements = element.getElementsByTag("a");
for (Element a : elements) {
String href = a.attr("href");
if(href.contains("jpeg")) {
System.out.println(href);
}
}
打印下结果,确实是拿到了所有的图片。

到了这一步算不算完成了呢?肯定没有啊,我们还没有下载到本地磁盘里面呢。不在自己电脑里怎么能在夜深人静的时候自己偷偷看啊😆
那我们就得想办法把这些链接下载下来啊,Java下载网络文件非常简单,我这里为了省事呢,直接使用了第三方的工具类 hutool ,感兴趣的同学们可以自己去了解一下 hutool 这个甜甜的工具类啊,保证你用完一次就爱上他。官网地址:https://www.hutool.cn/
引入hutool
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.3.7</version>
</dependency>
下载图片到本地磁盘:
java">for (Element a : elements) {
String href = a.attr("href");
if(href.contains("jpeg")) {
System.out.println(href);
// 下载图片到项目根路径下的imgs文件夹中
HttpUtil.downloadFile("https:" + href, new File(System.getProperty("user.dir") + "/imgs"));
}
}
再跑一遍:

控制台显示下载完成,我们打开本地磁盘的文件夹看看:


非常完美啊,看到这一排排的美女图片,内心还是有那么一丝丝的小躁动的 [害羞]
批量下载
刚才演示的是下载单个网页中的图片,那么很多坏家伙又会很好奇,怎么批量下载美女图片?
别以为我不知道你们的小心思哈,因为我也在琢磨呢,哈哈🤣
你别说,我还真找到办法了。
经过没日没夜的研究,我发现,不同网页的地址,是通过数字控制的,比如:https://www.vmgirls.com/14636.html 和 https://www.vmgirls.com/15298.html
那么就是说我们找到了这个数字,问题就迎刃而解了。
那么去哪找这个数字呢?答案肯定是在首页啊,打开首页的源代码看看:

我注意到这个 class=media-content 的 a 标签中包含了我们所需要的数据,所以我们来循环一次看看,是不是能拿到:
java">Document main = Jsoup.connect("https://www.vmgirls.com").get();
Elements medias = main.getElementsByClass("media-content");
for (Element media : medias) {
System.out.println(media.attr("href"));
}
跑了一下代码,确实拿到了这个数字的地址,但是数据还是有点混乱。

我们需要做进一步的筛选,筛选出末尾是html结尾的地址。
java">Document main = Jsoup.connect("https://www.vmgirls.com").get();
Elements medias = main.getElementsByClass("media-content");
for (Element media : medias) {
String href = media.attr("href");
if (href.endsWith("html")) {
System.out.println(href);
}
}
再跑一次,这就完美了:

接下来就好办了,有了网页的地址,我们只需要挨个循环,就能批量得到网页的数据了!
完整代码:
java">Document main = Jsoup.connect("https://www.vmgirls.com").get();
Elements medias = main.getElementsByClass("media-content");
for (Element media : medias) {
String url = media.attr("href");
if (url.endsWith("html")) {
Document document = Jsoup.connect("https://www.vmgirls.com/" + url).get();
Element element = document.getElementsByClass("nc-light-gallery").get(0);
Elements elements = element.getElementsByTag("a");
for (Element a : elements) {
String href = a.attr("href");
if (href.contains("jpeg")) {
System.out.println(href);
HttpUtil.downloadFile("https:" + href, new File(System.getProperty("user.dir") + "/imgs"));
}
}
}
}
System.out.println("下载完成");
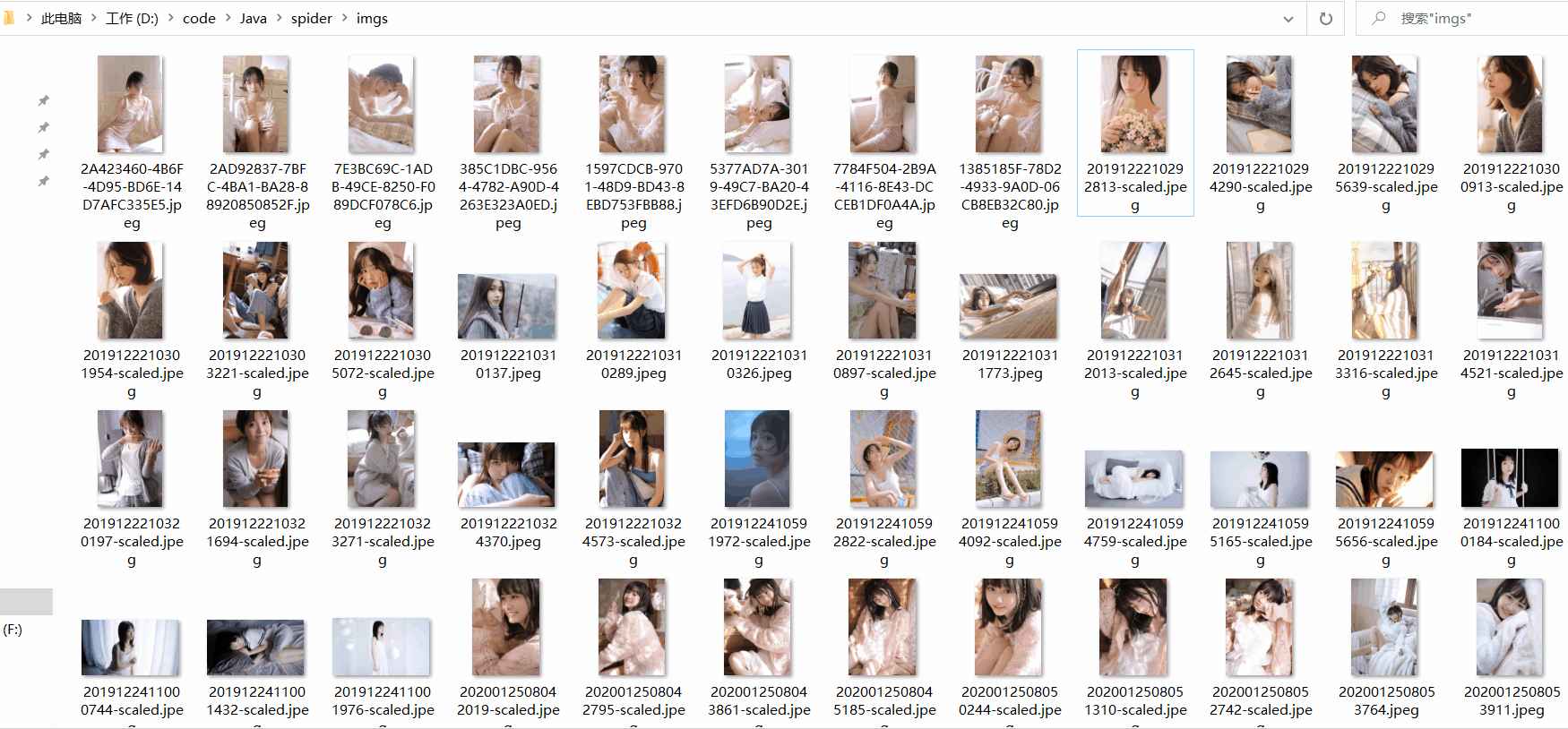
怎么样?看到这琳琅满目的妹子,都是青春期的诱惑啊!心动没?没事,代码拿去,自己跑跑,晚上在被窝里偷偷看也没人知道的🤭
至少,我不会说出去~
我是
程序员青戈,没错,逗比青年就是我了,还不赶紧来关注这个骚味十足的年轻人😋
我的原创公众号:
Java学习指南最近正在筹备一批Java干货教程,现在关注还赶得上趟哦🤩
感谢你的阅读,看完别忘记三连哦🍭我们下期见~