文章目录
- 1. scrapy介绍
- 2 新建爬虫项目
- 3 新建蜘蛛文件
- 4 运行爬虫
- 5 爬取内容
- 5.1分析网页结构
- 5.2 关于Xpath解析
- 5.3 接着解析电影数据
- 5.4 下载缩略图
- 5.5 完整代码
- 6 最后说明
- 7 2023.01.23更新
- 7.1 关于分页
- 7.1.1 第一种是类似`烂番茄网`这样底部只有一个load more按钮的。每次单击这个按钮,会刷新出新一页的数据。但是每次单击时,地址栏都会携带一个page参数,每次加1.
- 异常处理
- 避免重复抓取
- 7.1.2 第二种分页,页面效果类似下面:
- 7.1.3 第三种分页,瀑布流,不携带分页参数的情况.
- 7.1.4 第四种分页,可以从下一页按钮获取下一页的链接
- 7.1.5 第五种分页,模拟点击下一页按钮(2023.02.03更新)
本例基于python3和scrapy爬虫框架,不再介绍python的基础知识和爬虫的基本知识。
1. scrapy介绍
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
首先安装scrapy:
pip3 install scrapy
2 新建爬虫项目
scrapy startproject pic
项目目录如下:

3 新建蜘蛛文件
蜘蛛文件放在spiders目录下,在spiders目录下新建一个蜘蛛文件pic.py,内容如下,并没有设计爬取操作,代码比较简单,看代码中的注释就明白了:
python">import scrapy
#类名自定义,参数固定为scrapy.Spider
class GetImage(scrapy.Spider):
name="pic" #蜘蛛名称,必须唯一,一个爬虫项目可以新建多个蜘蛛文件,蜘蛛名不能重复
def start_requests(self):
#定义要爬取的url
urls=[
'https://www.rottentomatoes.com/browse/movies_in_theaters/'
]
#请求网页内容,并将内容交给回调函数处理
for url in urls:
# yield关键字类似return,scrapy.Request发起网页请求,括号内为参数,第一个参数是Request要请求的地址,第二个参数是回调函数,表示Request取到的内容交由该回调函数处理。
yield scrapy.Request(url=url,callback=self.parse)
#上一方法需要调用的回调函数
def parse(self,response):
print("------------------------")
#此处获取上一步请求的网页内容及请求状态,print(response.body)可以获取网页内容,
#因为内容太长,这里不再输出,只输出地址和状态。
print(response)
4 运行爬虫
回到项目的根目录,运行如下命令:
scrapy crawl pic # crawl指定类文件中定义的蜘蛛名称pic
可以在运行日志中查看结果,200是网页连接正常的状态码:

5 爬取内容
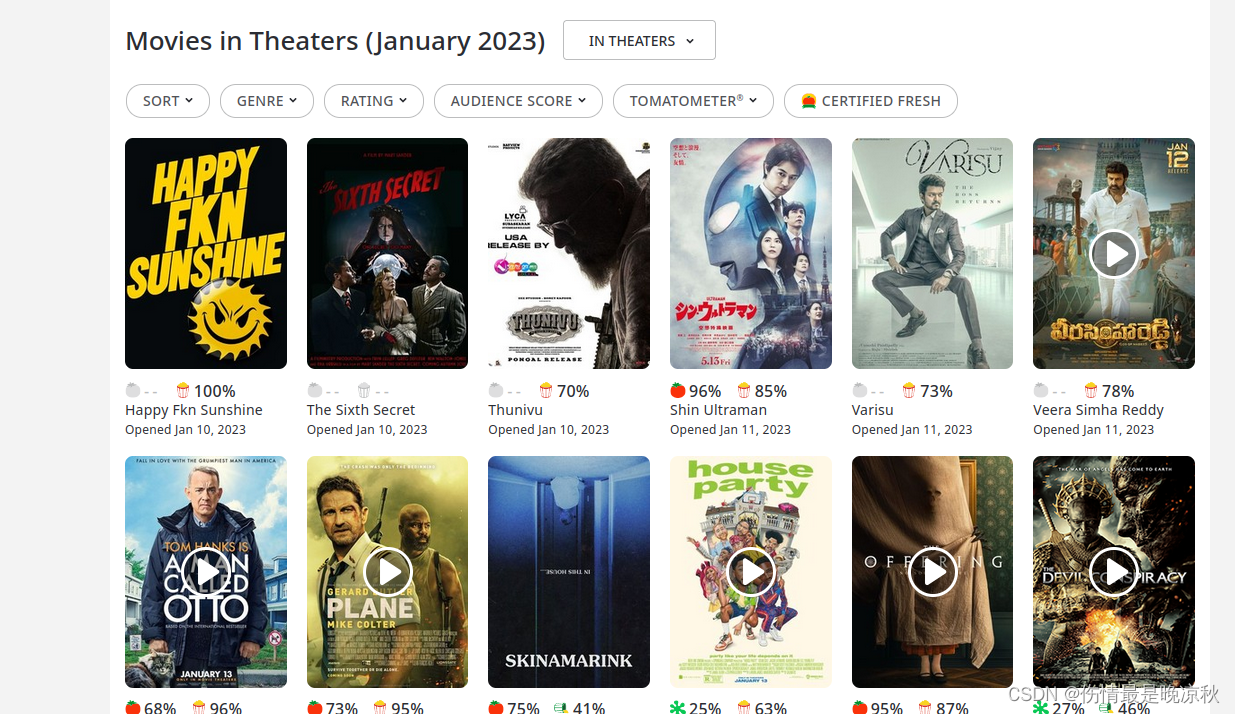
上面代码中的网址是烂番茄网的电影页面,建议在测试时尽量选择测试网站进行测试,爬取信息时请遵守网站规定,并确认是否允许爬取.示例中的网页如下图所示:
5.1分析网页结构
我们的目标是所有电影的名称和缩略图,首先通过F12查看网页的结构及目标节点的样式,如下图所示:
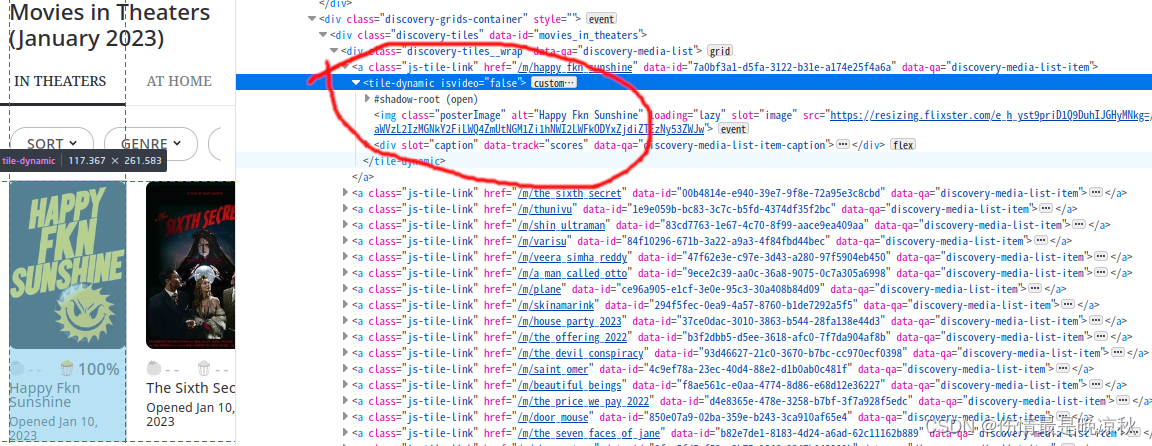 可以看到只要找
可以看到只要找tile-dynamic节点下的img标签即可。scrapy中获取节点如下所示:
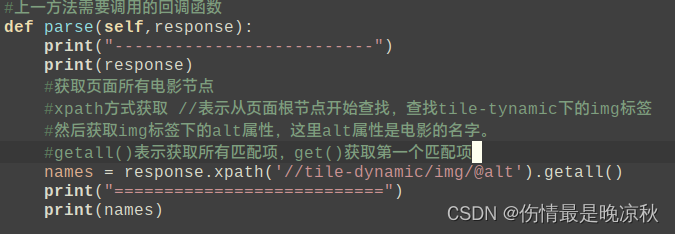
运行爬虫,获取到的电影名称如下所示,是一个列表:

5.2 关于Xpath解析
此处展示一些Xpath用法:
python"> #从html根节点查找最外层所有div
divs = response.xpath('//div')
#从html根节点查找第一个div
div = response.xpath('//div[1]')
#从上面的div中查找所有p节点,注意此时开头用./不是//
ps = div.xpath('./p')
#从上面的div中查找所有样式为col-4的p节点
ps1 = div.xpath('./p[@class="col-4"]')
#循环获取ps1中所有p节点下的img图像地址
for p in ps1:
#获取节点属性以@开头如@alt,@src,@text等
srcs = p.xpath('./img/@src').get() #或者getall(),p节点包含多张图片的情况
#更多xpath请参考官方教程:
#https://docs.scrapy.org/en/latest/topics/selectors.html#working-with-xpaths
5.3 接着解析电影数据
增加对缩略图的抓取,代码获取的缩略图如下图所示:


5.4 下载缩略图
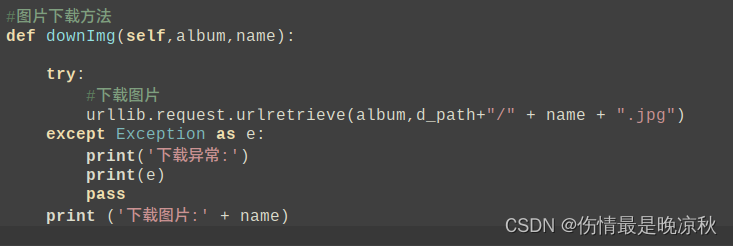
下载过程如图所示:

下载内容:

5.5 完整代码
python">import scrapy
import ssl
import os
import urllib
#定义图片下载地址,请修改为自己的路径
d_path = '/home/ubuntu/下载/albums'
#类名自定义,参数固定为scrapy.Spider
class GetImage(scrapy.Spider):
name="pic" #蜘蛛名称,必须唯一,一个爬虫项目可以新建多个蜘蛛文件,蜘蛛名不能重复
def start_requests(self):
#定义要爬取的url
urls=[
'https://www.rottentomatoes.com/browse/movies_in_theaters/'
]
#请求网页内容,并将内容交给回调函数处理
for url in urls:
# yield关键字类似return,scrapy.Request发起网页请求,括号内为参数,第一个参数是Request要请求的地址,第二个参数是回调函数,表示Request取到的内容交由该回调函数处理。
yield scrapy.Request(url=url,callback=self.parse)
#上一方法需要调用的回调函数
def parse(self,response):
print("--------------------------")
#此处获取上一步请求的网页内容及请求状态,print(response.body)可以获取网页内容,
#因为内容太长,这里不再输出,只输出地址和状态。
print(response)
#获取页面所有电影节点
#xpath方式获取 //表示从页面根节点开始查找,查找tile-tynamic下的img标签
#然后获取img标签下的alt属性,这里alt属性是电影的名字。
#getall()表示获取所有匹配项,get()获取第一个匹配项
names = response.xpath('//tile-dynamic/img/@alt').getall()
#获取页面所有电影缩略图地址
albums = response.xpath('//tile-dynamic/img/@src').getall()
for index,album in enumerate(albums):
#循环取出缩略图地址,交由函数downImg来完成图片下载
#并传入参数name,用作下载的缩略图命名
self.downImg(album,names[index])
#图片下载方法
def downImg(self,album,name):
try:
#下载图片,参数第一个是缩略图地址,第二个参数是文件保存地址+文件名称+后缀名
urllib.request.urlretrieve(album,d_path+"/" + name + ".jpg")
except Exception as e:
print('下载异常:')
print(e)
pass
print ('下载图片:' + name)
6 最后说明
一个简单的图片爬虫就完成了,一个功能复杂的爬虫,还需要解决登陆,分页,或者爬取到结果后入库等操作,这里就不多做解释,以后有空会更新登陆,分页等其他功能,没有空就不更新了。最后还要说明一点,爬取网络内容时请遵守相关法律法规,和网站规则。一般网站的根目录下都有robots.txt文件,请确保遵循了robots.txt的规则。比如烂番茄网的robots.txt规则如下:
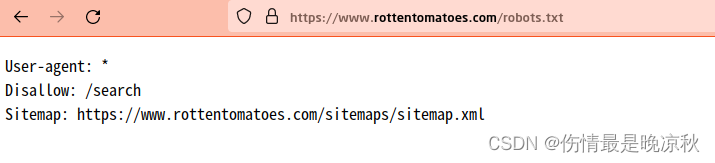
Disallow:/search 表示不允许爬取 /search下的所有网页。
7 2023.01.23更新
7.1 关于分页
7.1.1 第一种是类似烂番茄网这样底部只有一个load more按钮的。每次单击这个按钮,会刷新出新一页的数据。但是每次单击时,地址栏都会携带一个page参数,每次加1.


在抓取时抓取地址添加一个参数并且循环增加这个page参数即可。这种页面在不知道总页数是多少页的情况下,我们可以自由选择要抓取的页数,或者一个很大的数去抓取全部数据。代码示例如下:

异常处理
关于下载图片时的异常如:

是因为这张图片的名字中包含特殊字符<无法识别为路径,创建图片失败所致,在name中去掉标记即可,示例如下:

然后这张图片就正常了:

在你们自己的文件中需要根据异常信息自己处理.
避免重复抓取
对于上面的分页情况,当跳转第二页的时候,事页面上的数据已经包含了前2页的数据,这个时候要处理已经抓取过的数据,重复抓取对结果并无影响,因为上面的图片下载方法如果存在文件则会覆盖.但是会引起不必要的开销.针对上面的情况,事实上只要抓取第三页的数据就可以了.不用循环页码去分别抓取1,2,3页的数据.
另一种方法是判断磁盘上文件是否存在,不存在时下载,存在则提示.如下所示:


7.1.2 第二种分页,页面效果类似下面:
 这种情况可以抓取分页条来获得最大页码,之后同样拼接分页参数,处理同上不再赘述.
这种情况可以抓取分页条来获得最大页码,之后同样拼接分页参数,处理同上不再赘述.
7.1.3 第三种分页,瀑布流,不携带分页参数的情况.
以搜狗图像为例,分析每次滑动鼠标出现xhr请求的地址就会发现,每次从接口请求48张图片,只是开始的位置不一样,即参数中的start:


所以我们只需要抓取这个接口的数据即可,每次抓取更新start参数值.scrapy抓取https://pic.sogou.com/napi/pc/searchList?mode=1&start=0&xml_len=48&query=情侣头像的结果如下:
 从item节点里解析出图片的url地址并下载即可.
从item节点里解析出图片的url地址并下载即可.
7.1.4 第四种分页,可以从下一页按钮获取下一页的链接

如上如所示,只要抓取a标签的href值即可获取下一页地址.这里的地址是相对地址,需要手动拼接http://www.xxx.com部分.当然,不是所有的网站都可以从下一页的链接中获取地址.只适用于部分情况.
7.1.5 第五种分页,模拟点击下一页按钮(2023.02.03更新)
需要借助 selenium 或者 splash 包来实现.这里是splash为例:
-
安装
pip3 install scrapy-splash -
splash需要启动一个服务,这里以docker来启动:
2.1 安装dockersudo dnf install docker不同的发行版命令有差异,自己调整一下。
2.2 启动docker 服务sudo systemctl start docker
2.3 启动一个splash容器:sudo docker run -p 8050:8050 scrapinghub/splash,
如果下载速度太慢,配置一下docker镜像加速,编辑/etc/docker/daemon.json文件,没有就新建这个文件
参考如下配置:{ "registry-mirrors": [ "https://registry.docker-cn.com", "http://hub-mirror.c.163.com", "https://docker.mirrors.ustc.edu.cn" ], "storage-driver": "overlay2", "storage-opts": [ "overlay2.override_kernel_check=true" ] }2.4 控制台出现
[-] Server listening on http://0.0.0.0:8050表明启动成功。
示例代码如下:
python">import scrapy
import ssl
import os
import urllib
from scrapy_splash import SplashRequest
# 定义模拟点击的脚本文件,有个模板可以拷贝,docker启动splash成功后,
# 浏览器输入localhost:8050,页面上会有这个脚本的示例
# 拷贝回来修改即可.
script = """
function main(splash, args)
splash.images_enabled = false
assert(splash:go(args.url))
assert(splash:wait(1))
js = string.format("document.querySelector('div.discovery__actions > button).click();", args.page)
splash:runjs(js)
assert(splash:wait(5))
return splash:html()
end
"""
#类名自定义,参数固定为scrapy.Spider
class GetImage(scrapy.Spider):
name="pic" #蜘蛛名称,必须唯一,一个爬虫项目可以新建多个蜘蛛文件,蜘蛛名不能重复
def start_requests(self):
urls=[
'https://www.rottentomatoes.com/browse/movies_in_theaters/'
]
base_url = urls[0]
for i in range(1,4):
target_url = base_url + "?page="+str(i)
#yield scrapy.Request(url=target_url,callback=self.parse)
yield SplashRequest(target_url, callback=self.parse, endpoint='execute',
args={'lua_source': script, 'page': i, 'wait': 10})
def parse(self,response):
names = response.xpath('//div[@class="discovery-tiles__wrap"]/a/tile-dynamic/img/@alt').getall()
print("-----------------------")
print(len(names))
主要修改两处,第一个地方是定义一个script脚本,用于执行翻页动作的js.第二个地方是:
python">#由原来的scrapy.Request改为SplashRequest,将定义的script作为参数传入.page是页码.wait是等待时间.
yield SplashRequest(target_url, callback=self.parse, endpoint='execute',
args={'lua_source': script, 'page': i, 'wait': 10})
执行结果如下所示:
#这里只输出了目标元素的条数.
#第一页30条记录,第二页60条记录,第三页90条记录,因为这个网页翻页是在页面追加元素,前面解释过了
2023-02-03 22:10:14 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.rottentomatoes.com/browse/movies_in_theaters?page=2> (referer: None)
-----------------------
60
2023-02-03 22:10:15 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.rottentomatoes.com/browse/movies_in_theaters> (referer: None)
-----------------------
30
2023-02-03 22:10:18 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.rottentomatoes.com/browse/movies_in_theaters?page=3> (referer: None)
-----------------------
90
到这里翻页就完了,基本上包含了所有的翻页操作,最后一种用splash点击翻页虽然最复杂,但是却是最通用的一种翻页方式.最后解释一下script脚本:
function main(splash, args)
splash.images_enabled = false # 不加载图片
assert(splash:go(args.url)) #发起请求
assert(splash:wait(1)) #等待时间,单位:秒
#注意引号内的内容就是页面上翻页那个按钮,这个一定要正确.page是页码,
#此处的页码其实是调用发起处循环页码时传回的一个变量
js = string.format("document.querySelector('div.discovery__actions > button).click();", args.page)
splash:runjs(js) #执行js
assert(splash:wait(5)) #等待5s
return splash:html() #返回网页源码
end