多进程VS多线程
GIL锁.
GIL锁: 全局解释器锁. 就是一个加在解释器上的互斥锁,将并发变成串行,同一时刻只能有一个线程使用共享资源,牺牲效率,保证数据安全.
在了解GIL锁之前,我们先来了解一下,代码运行的时候发生了什么?
我们在运行一段代码,不仅需要将代码加载到内存,还需要将解释器加载到内存,我们以Cpython解释器来举例,解释器先将你的py文件翻译成C语言的字节码,然后交由虚拟机,虚拟机再将其翻译成计算机能理解的机器码,再交给CPU去处理
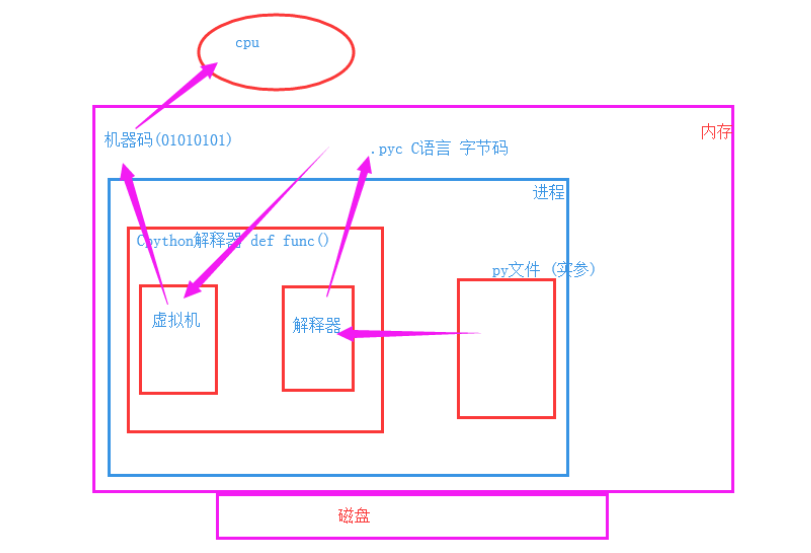
Ipython: 交互式解释器: 可以自动补全代码,其他跟Cpython解释器一样
Jython: 将py文件翻译成 java 字节码剩下的一样.
pypy: 动态编译: 利用JAT技术,弥补了解释型语言速度较慢的缺陷. 但是目前存在技术缺陷,还有bug,大神们正在修复BUG.
理论上来说,如果py文件内没有共享资源,这样运行没有一点问题
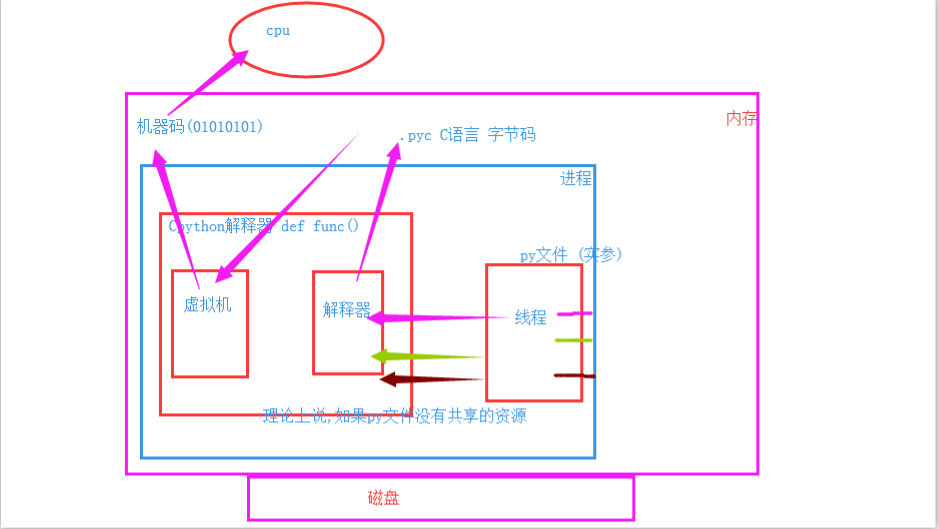
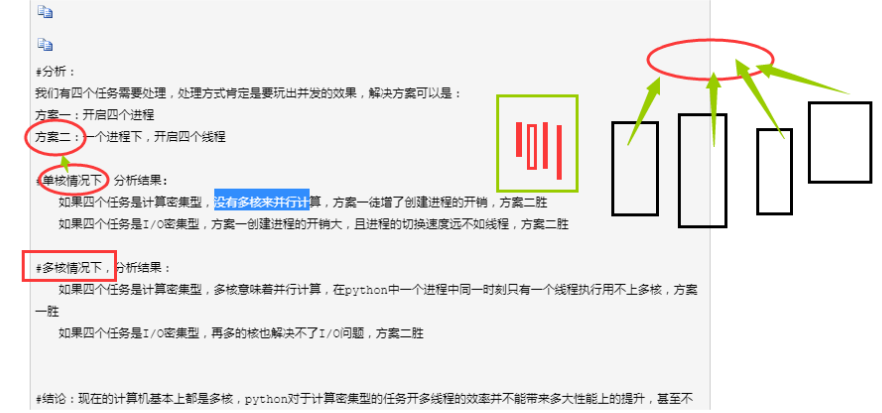
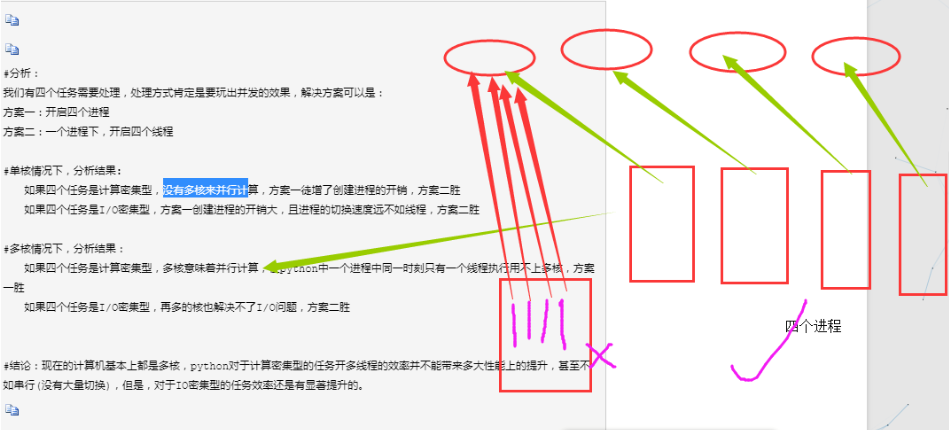
但是,实际上,解释器内是有共享资源的,就是当多个进程同时在一个文件中去抢这个数据,大家都把这个数据改了,但是还没来得及去更新到原来的文件中,就被其他进程也计算了,导致出现数据不安全的问题,所以我们是不是通过加锁可以解决这个问题呢,多线程大家想一下是不是一样的,并发执行就是有这个问题。但是python最早期的时候对于多线程也加锁,但是python比较极端的(在当时电脑CPU确实只有1核)加了一个GIL全局解释锁,是解释器级别的,锁的是整个线程,而不是线程里面的某些数据操作,每次只能有一个线程使用CPU,也就说多线程用不了多核,但是他不是python语言的问题,是CPython解释器的特性,如果用Jpython解释器是没有这个问题的.
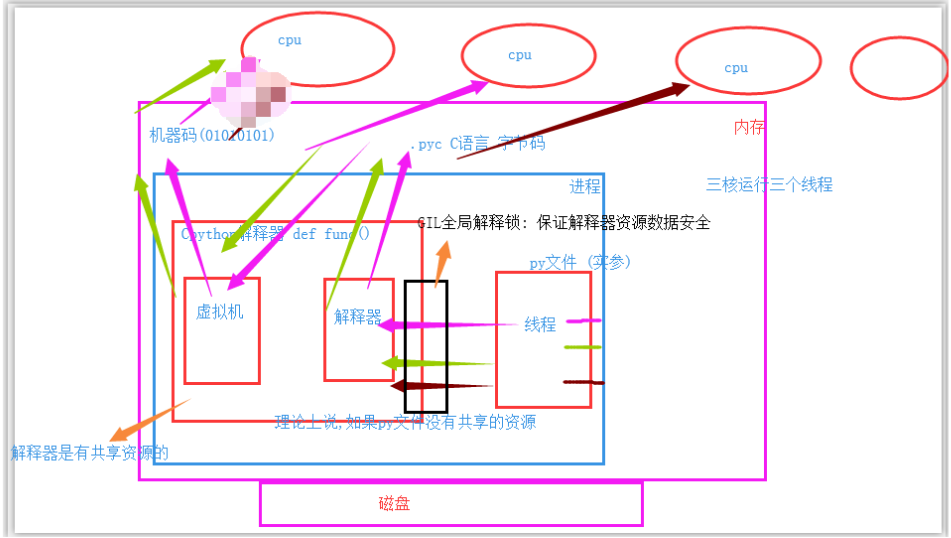
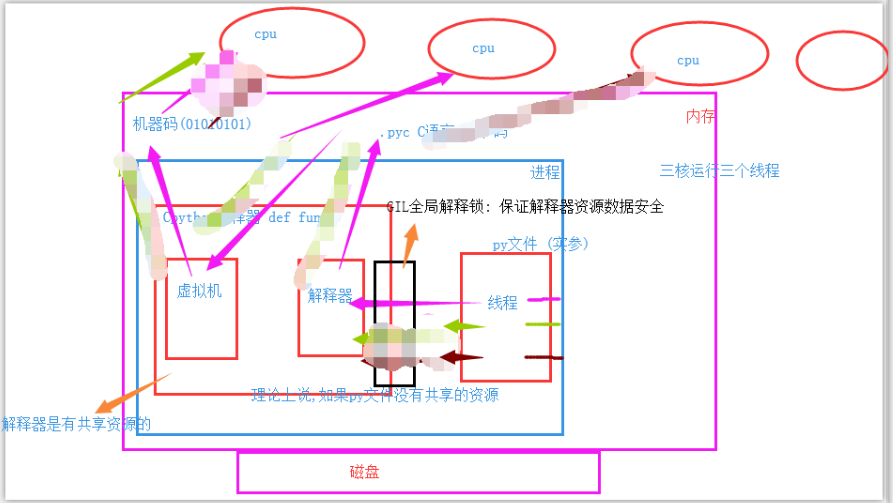
设置全局解释锁(GIL)的原因
- 保证解释器里面的数据安全.
- 强行加锁: 减轻了你开发的人员的负担.
但是GIL锁确实一把双刃剑: 加了这把锁,虽然解决了一些问题,但是也带来新的问题.
带来的问题1:
单进程的多线程不能利用多核. 诟病之一.
但是多进程的多线程可以利用多核.
带来的问题2:
感觉上不能并发的执行问题.???
有人说因为存在这个锁,导致单个进程多线程不能利用多核,为什么不去掉?
这个问题就要问那些开发Cpython解释器的大神了,他们所有的代码都是基于这个GIL锁写的,如果想去掉这个GIL锁,工作量与重新写一个解释器差不多.
所以我们既然没能力去写一个解释器,还是乖乖用大神们写的吧.即使有缺点也要用啊
讨论: 单核处理IO阻塞的多线程,与多核处理IO阻塞的多线程效率差不多.
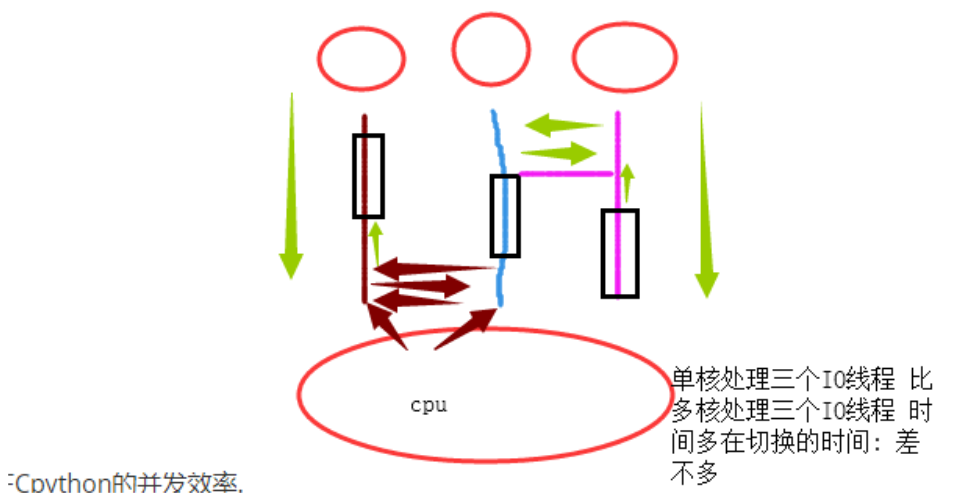
单核处理计算密集型
多核:处理计算密集型
总结:
多核的前提下: 如果任务Io密集型: 多线程并发.
如果任务计算密集型: 多进程并发.
验证Cpython的并发效率.
python"># 计算密集型 # 开启四个进程,开启四个线程 from multiprocessing import Process from threading import Thread import time import os def task1(): res = 1 for i in range(1, 100000000): res += i def task2(): res = 1 for i in range(1, 100000000): res += i def task3(): res = 1 for i in range(1, 100000000): res += i def task4(): res = 1 for i in range(1, 100000000): res += i if __name__ == '__main__': # 四个进程 四个cpu 并行 效率 start_time = time.time() p1 = Process(target=task1) p2 = Process(target=task2) p3 = Process(target=task3) p4 = Process(target=task4) p1.start() p2.start() p3.start() p4.start() p1.join() p2.join() p3.join() p4.join() print(f'主: {time.time()-start_time}') # 7.53943133354187 # 一个进程 四个线程 1 cpu 并发 25.775474071502686 # start_time = time.time() # p1 = Thread(target=task1) # p2 = Thread(target=task2) # p3 = Thread(target=task3) # p4 = Thread(target=task4) # p1.start() # p2.start() # p3.start() # p4.start() # p1.join() # p2.join() # p3.join() # p4.join() # print(f'主: {time.time() - start_time}') # 25.775474071502686 # 计算密集型: 多进程的并行 单进程的多线程的并发执行效率高很多. # 讨论IO密集型: 通过大量的任务去验证. from multiprocessing import Process from threading import Thread import time import os def task1(): res = 1 time.sleep(3) if __name__ == '__main__': # 开启150个进程(开销大,速度慢),执行IO任务, 耗时 9.293531656265259 start_time = time.time() l1 = [] for i in range(150): p = Process(target=task1) l1.append(p) p.start() for i in l1: i.join() print(f'主: {time.time() - start_time}') # 开启150个线程(开销小,速度快),执行IO任务, 耗时 3.0261728763580322 # start_time = time.time() # l1 = [] # for i in range(150): # p = Thread(target=task1) # l1.append(p) # p.start() # for i in l1: # i.join() # print(f'主: {time.time() - start_time}') # 结论:任务是IO密集型并且任务数量很大,用单进程下的多线程效率高.GIL锁与互斥锁的关系.
GIL锁与互斥锁关系图示:
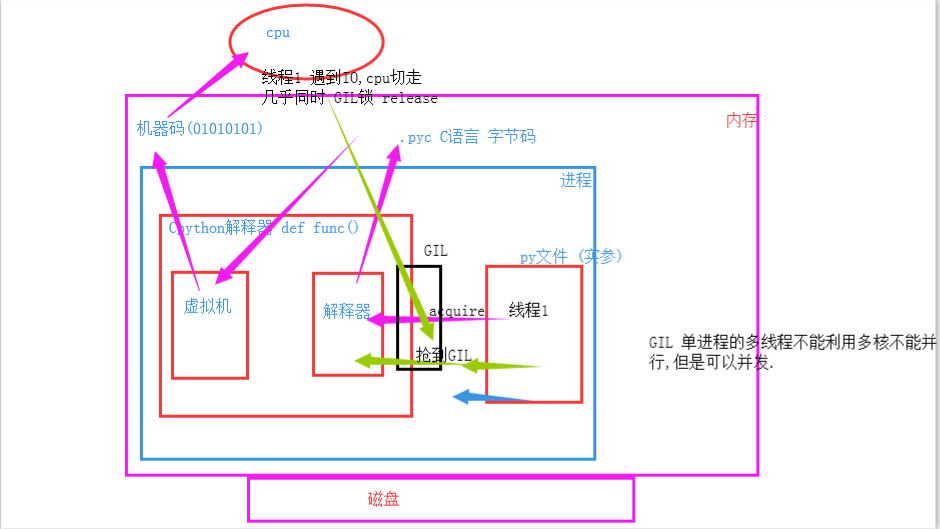

代码验证
python"># 1. GIL 自动上锁解锁, 文件中的互斥锁Lock 手动上锁解锁. # 2. GIL锁 保护解释器的数据安全. 文件的互斥锁Lock 保护的文件数据的安全. from threading import Thread from threading import Lock import time lock = Lock() x = 100 def task(): global x lock.acquire() temp = x temp -= 1 x = temp lock.release() if __name__ == '__main__': t_l = [] for i in range(100): t = Thread(target=task) t_l.append(t) t.start() for i in t_l: i.join() print(f'主线程{x}') # 线程全部是计算密集型:当程序执行,开启100个线程时,第一个线程先要拿到GIL锁,然后拿到lock锁,释放lock锁,最后释放GIL锁. # 加上一个阻塞试试看 from threading import Thread from threading import Lock import time lock = Lock() x = 100 def task(): global x lock.acquire() temp = x time.sleep(1) temp -= 1 x = temp lock.release() if __name__ == '__main__': t_l = [] for i in range(100): t = Thread(target=task) t_l.append(t) t.start() for i in t_l: i.join() print(f'主线程{x}') ''' 线程IO密集型:当程序执行,开启100个线程时,第一个线程先要拿到GIL锁,然后拿到lock锁,运行,遇到阻塞,CPU切换出去,几乎同时,GIL锁被释放,下一个线程抢到GIL锁,CPU来处理这个线程,遇到Lock锁,但Lock锁病没有被释放,所以CPU继续切出去...... 总结: 自己加互斥锁,一定要加在处理共享数据的地方,加的范围不要扩大,不然会降低效率 '''
进程池线程池.
'池': 容器, 进程池: 放置进程的一个容器, 线程池: 放置线程的一个容器.
利用多线程完成一个简单的socket通信,连接循环,可以同时接收多个客户端的数据
python">import socket from threading import Thread def communication(conn): while 1: try: from_client_data = conn.recv(1024) # 阻塞 print(from_client_data.decode('utf-8')) to_client_data = input('>>>').strip() conn.send(to_client_data.encode('utf-8')) except Exception: break conn.close() def customer_service(): server = socket.socket() server.bind(('127.0.0.1', 8080)) server.listen() while 1: conn,addr = server.accept() # 阻塞 print(f'{addr}客户:') t = Thread(target=communication,args=(conn,)) t.start() server.close() if __name__ == '__main__': customer_service()客户端:
python">import socket client = socket.socket() client.connect(('127.0.0.1', 8080)) while 1: to_server_data = input('>>>').strip() client.send(to_server_data.encode('utf-8')) from_server_data = client.recv(1024) print(f'客服回信: {from_server_data.decode("utf-8")}') client.close()线程即使开销小,你的电脑也不可以无限的开线程,我们应该对线程(进程)做数量的限制.在计算机的能满足的最大情况下,更多的创建线程(进程).这时就需要用到线程池(进程池)了
在这里,要给大家介绍一个进程池的概念,定义一个池子,在里面放上固定数量的进程,有需求来了,就拿一个池中的进程来处理任务,等到处理完毕,进程并不关闭,而是将进程再放回进程池中继续等待任务。如果有很多任务需要执行,池中的进程数量不够,任务就要等待之前的进程执行任务完毕归来,拿到空闲进程才能继续执行。也就是说,池中进程的数量是固定的,那么同一时间最多有固定数量的进程在运行。这样不会增加操作系统的调度难度,还节省了开闭进程的时间,也一定程度上能够实现并发效果
python">from concurrent.futures import ProcessPoolExecutor # 进程池 # from concurrent.futures import ThreadPoolExecutor # 线程池 import time import os import random print(os.cpu_count()) # 查看CPU数量 def task(name): print(name) print(f'{os.getpid()} 准备接客') time.sleep(random.randint(1,3)) if __name__ == '__main__': p = ProcessPoolExecutor() # 设置进程数量默认为cpu个数 for i in range(23): p.submit(task,1) # 给进程池放任务,传参 # 线程池 # from concurrent.futures import ProcessPoolExecutor from concurrent.futures import ThreadPoolExecutor import time import os import random def task(name): print(name) print(f'{os.getpid()} 准备接客') time.sleep(random.randint(1,3)) if __name__ == '__main__': p = ThreadPoolExecutor() #设置线程数量,默认是cpu数量*5 for i in range(23): p.submit(task,1) # 给线程池放任务,传参线程池好,进程池好?
就是问多线程,多进程的应用: IO密集: 多线程 计算密集:多进程
阻塞,非阻塞,异步,同步
程序运行中表现的状态: 阻塞, 运行,就绪
阻塞: 程序遇到IO阻塞. 程序遇到IO立马会停止(挂起), CPU马上切换,等到IO结束之后,再继续执行.
非阻塞: 程序没有IO或者 遇到IO通过某种手段让CPU去执行其他的任务,尽可能的占用CPU.
异步,同步:
站在任务发布的角度.
同步: 任务发出去之后,等待,直到这个任务最终结束之后,给我一个返回值,我在发布下一个任务.
异步: 所有的任务同时发出, 我就继续下一行. 任务结果何时接收?
python"># 异步回收任务的方式一: 我将所有的任务的结果统一收回. from concurrent.futures import ProcessPoolExecutor import os import time import random def task(): print(f'{os.getpid()} is running') time.sleep(random.randint(0,2)) return f'{os.getpid()} is finish' if __name__ == '__main__': p = ProcessPoolExecutor(4) obj_l1 = [] for i in range(10): obj = p.submit(task,) # 异步发出. obj_l1.append(obj) p.shutdown(wait=True) # p.shutdown(wait=True)的作用 # 1. 阻止在向进程池投放新任务, # 2. wait = True 十个任务是10,一个任务完成了-1,直至为零.进行下一行. for i in obj_l1: print(i.result()) # 同步发布任务: 我要发布10个任务,先把第一个任务给第一个进程,等到第一个进程完成之后. 我再将第二个任务给下一个进程,...... # 异步发布任务: 我直接将10个任务抛给4个进程, 我就继续执行下一行代码了.等结果. # 异步回收任务的方式二: 完成一个任务收回一个结果 from concurrent.futures import ProcessPoolExecutor import os import time import random def task(): print(f'{os.getpid()} is running') time.sleep(1) return f'{os.getpid()} is finish' if __name__ == '__main__': p = ProcessPoolExecutor(4) for i in range(10): obj = p.submit(task,) # 异步发出. print(obj.result())异步+ 调用机制
当我们用浏览器查看一些信息时,浏览器会对我们的需求进行处理
浏览器做的事情很简单:
浏览器 封装头部 发一个请求 ---> 域名解析,找到服务器位置 ---> 服务器获取到请求信息,分析正确 ----> 给你返回一个文件.---> 浏览器将这个文件的代码渲染,就成了你看到的网页:
文件: 其实你收到的文件就是一堆代码,经过浏览器的渲染才呈现成网页
爬虫: 利用requests模块功能模拟浏览器封装头,给服务器发送一个请求,骗过服务器之后,服务器也给你返回一个文件. 爬虫拿到文件,进行数据清洗获取到你想要的信息.
第一步: 爬取服务端的文件(IO阻塞).
第二步: 拿到文件,进行数据分析,(非IO或IO极少)
python"># 异步处理: 获取结果的第二种方式: 完成一个任务返回一个结果,完成一个任务,返回一个结果 并发的返回. import requests from concurrent.futures import ProcessPoolExecutor from multiprocessing import Process import time import random import os def get(url): response = requests.get(url) print(f'{os.getpid()} 正在爬取:{url}') time.sleep(random.randint(1,3)) if response.status_code == 200: parse(response.text) def parse(text): # 对爬取回来的字符串的分析,简单用len模拟一下. print(f'{os.getpid()} 分析结果:{len(text)}') if __name__ == '__main__': url_list = [ 'http://www.taobao.com', 'http://www.JD.com', 'http://www.JD.com', 'http://www.JD.com', 'http://www.baidu.com', 'https://www.cnblogs.com', 'https://www.cnblogs.com', 'http://www.sina.com.cn', 'https://www.sohu.com', 'https://www.youku.com',] pool = ProcessPoolExecutor(4) for url in url_list: obj = pool.submit(get, url) pool.shutdown(wait=True) print('主') # 上面的版本虽然很不错,但是两个任务有耦合性. 在上一个基础上,对其进程解耦. # 利用回调函数 import requests from concurrent.futures import ProcessPoolExecutor from multiprocessing import Process import time import random import os def get(url): response = requests.get(url) print(f'{os.getpid()} 正在爬取:{url}') time.sleep(random.randint(1,3)) if response.status_code == 200: return response.text def parse(obj): # 对爬取回来的字符串的分析,简单用len模拟一下. time.sleep(1) print(f'{os.getpid()} 分析结果:{len(obj.result())}') if __name__ == '__main__': url_list = [ 'http://www.taobao.com', 'http://www.JD.com', 'http://www.JD.com', 'http://www.JD.com', 'http://www.baidu.com', 'https://www.cnblogs.com', 'https://www.cnblogs.com', 'http://www.sina.com.cn', 'https://www.sohu.com', 'https://www.youku.com',] start_time = time.time() pool = ProcessPoolExecutor(4) for url in url_list: obj = pool.submit(get, url) obj.add_done_callback(parse) # 增加一个回调函数 # 现在的进程完成的还是网络爬取的任务,拿到了返回值之后,结果丢给回调函数add_done_callback, # 回调函数帮助你分析结果 # 进程继续完成下一个任务. pool.shutdown(wait=True) print(f'主: {time.time() - start_time}') # 回调函数是主进程帮助你实现的, 回调函数帮你进行分析任务. 明确了进程的任务: 只有一个网络爬取. # 分析任务: 回调函数执行了.对函数之间解耦. # 极值情况: 如果回调函数是IO任务,那么由于你的回调函数是主进程做的,所以有可能影响效率. # 回调不是万能的,如果回调的任务是IO,那么异步 + 回调机制 不好用.此时如果你要效率只能牺牲开销,再开一个线程进程池. # 如果多个任务,多进程多线程处理的IO任务. # 1. 剩下的任务 非IO阻塞. 异步 + 回调机制 # 2. 剩下的任务 IO << 多个任务的IO 异步 + 回调机制 # 3. 剩下的任务 IO >= 多个任务的IO 第一种解决方式,或者两个进程线程池. # 异步跟回调是两种概念,两者并不相同线程队列
python"># 1 FIFO queue 先进先出 import queue q = queue.Queue(3) q.put(1) q.put(2) q.put('太白') print(q.get()) print(q.get()) print(q.get()) # LIFO 栈. 先进后出 import queue q = queue.LifoQueue() q.put(1) q.put(3) q.put('barry') print(q.get()) print(q.get()) print(q.get()) # 优先级队列 # 需要元组的形式,(int,数据) int 代表优先级,数字越低,优先级越高. import queue q = queue.PriorityQueue(3) q.put((10, '垃圾消息')) q.put((-9, '紧急消息')) q.put((3, '一般消息')) print(q.get()) print(q.get()) print(q.get())事件Event
并发的执行某个任务 .多线程多进程,几乎同时执行.
一个线程执行到中间时通知另一个线程开始执行.
python">import time from threading import Thread from threading import current_thread from threading import Event event = Event() # 默认是False def task(): print(f'{current_thread().name} 检测服务器是否正常开启....') time.sleep(3) event.set() # 改成了True def task1(): print(f'{current_thread().name} 正在尝试连接服务器') # event.wait() # 轮询检测event是否为True,当其为True,继续下一行代码. 阻塞. event.wait(1) # 设置超时时间,如果1s中以内,event改成True,代码继续执行. # 设置超时时间,如果超过1s中,event没做改变,代码继续执行. print(f'{current_thread().name} 连接成功') if __name__ == '__main__': t1 = Thread(target=task1,) t2 = Thread(target=task1,) t3 = Thread(target=task1,) t = Thread(target=task) t.start() t1.start() t2.start() t3.start()


![[视频]Siri已经可以在iPod touch 4上进行对话了](http://img.cnbeta.com/upimg/111030/leoliyuan_1455521152878203.jpg)