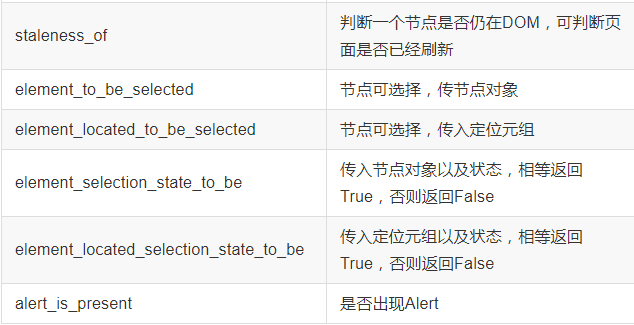
一、文本保存:
1、文件保存方式:

二、保存为json格式:
1、读取json:
.loads() 方法 :读取字符串,然后返回json对象。
但需注意:json数据的字符串需要使用双引号来包含,不能使用单引号。
2、json文件读取:
3、json文件保存:
三、保存为csv文件:
1、写入:
1 with open('data.csv', 'w') as csvfile: 2 fieldnames = ['id', 'name', 'age'] 3 writer = csv.DictWriter(csvfile, fieldnames=fieldnames) 4 writer.writeheader() 5 writer.writerow({'id': '10001', 'name': 'Mike', 'age': 20}) 6 writer.writerow({'id': '10002', 'name': 'Bob', 'age': 22}) 7 writer.writerow({'id': '10003', 'name': 'Jordan', 'age': 21})
2、读出:
1 with open('data.csv','r',encoding='utf-8') as file: 2 reader=csv.reader(file) 3 for i in reader: 4 print(i)
四、mongodb学习:
1、连接MongoDB:
1 import pymongo 2 #端口号可以指定,不指定默认为27017 3 mongo=pymongo.MongoClient(host='localhost')
1 #指定数据库 2 db=mongo.test 3 collection=db.students
3、插入数据:
1 student = { 2 'id': '20170101', 3 'name': 'Jordan', 4 'age': 20, 5 'gender': 'male' 6 } 7 #插入一条数据 8 result=collection.insert_one(student) 9 #插入多条数据 10 result=collection.insert_many([student,student]) 11 print(result.inserted_id)
4、数据查询:
插入数据后我们可以利用 find_one() 或 find() 方法进行查询,find_one() 查询得到是单个结果,find() 则返回一个生成器对象。
1 #查询 2 result=collection.find({'name':'Jordan'}) 3 print(result.count())

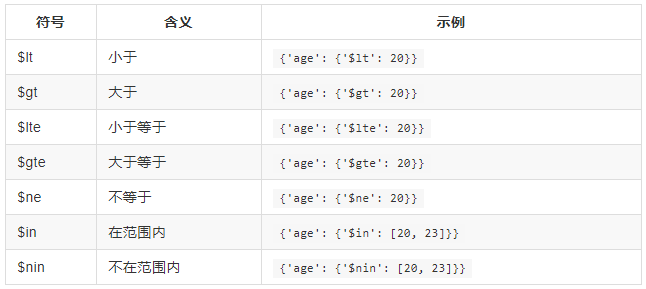

5、计数:
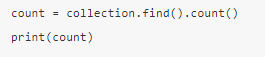
6、排序:
7、偏移:

8、更新:
需要指定更新的条件和更新后的数据:

9、删除:

五、Redis存储:
1、连接:
1 from redis import StrictRedis 2 3 4 redis=StrictRedis(host='localhost',port=6379,db=0) 5 redis.set('name','bog') 6 redis.set('age',20) 7 print(redis.get('name'))
2、key操作:
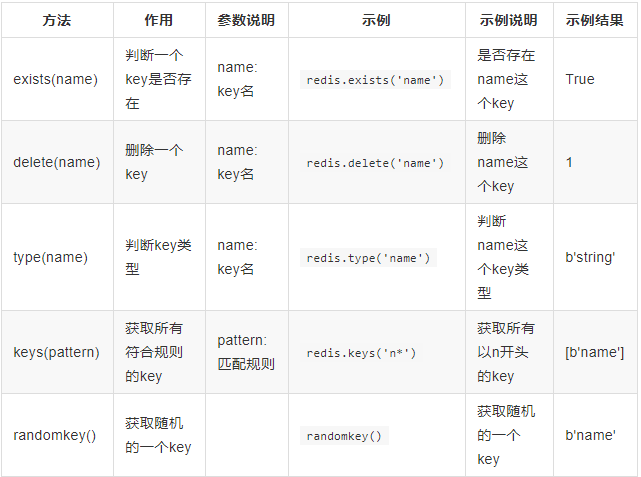
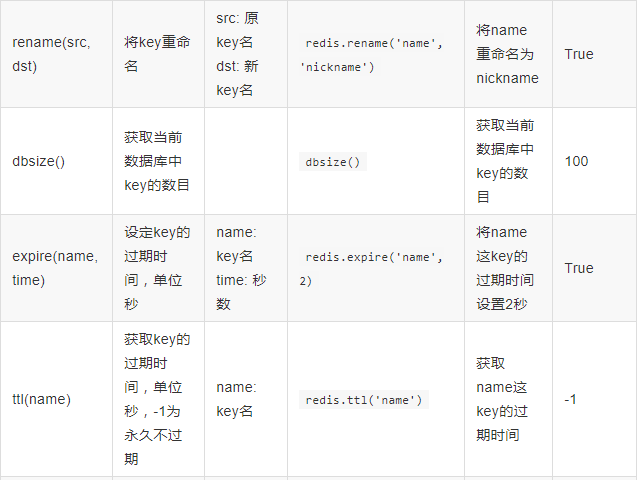

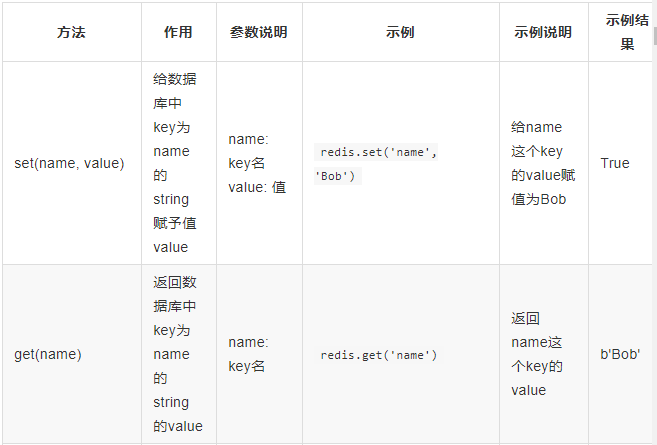
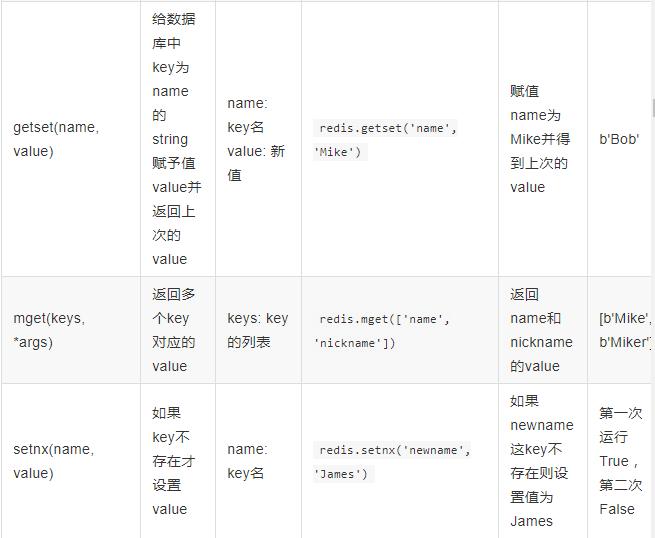
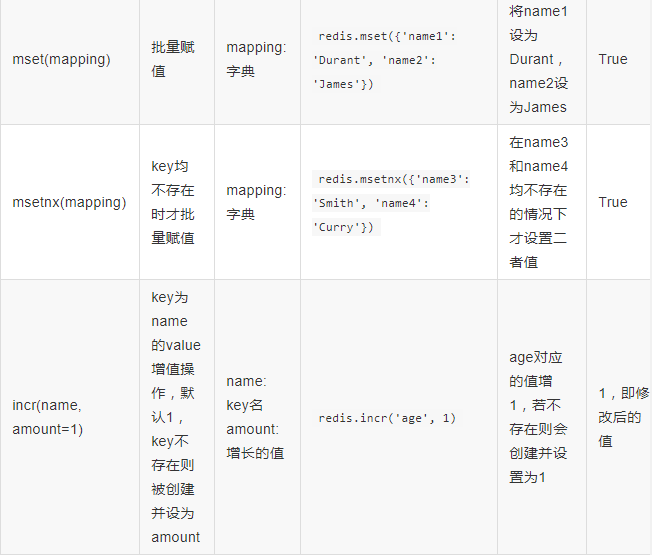
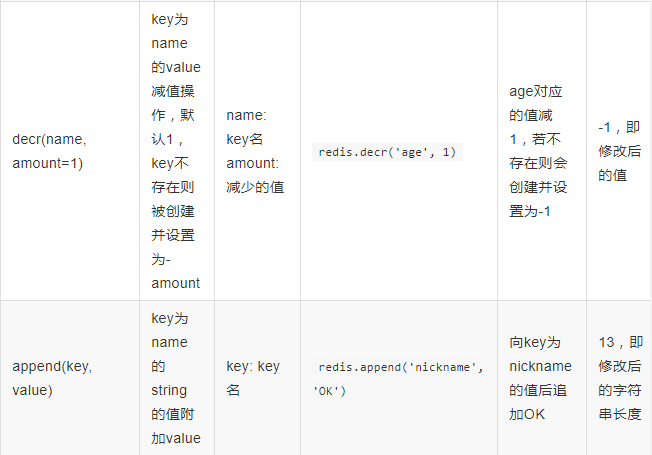
4、string操作: