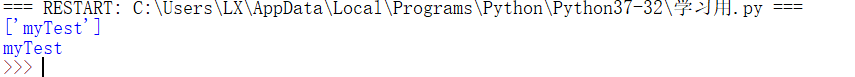python_0">python网络爬虫抓取数个最优链接展示(百度抓取)
前言
一、库声明
我们这次需要用到requests,sys, webbrowser,bs4,os库,如果没有库的小伙伴可以看我这个博文,pip快速安装各种库
二、步骤
1.引入库
代码如下(示例):
python">import requests,sys, webbrowser,bs4,os
2.获取命令行参数
如果有小伙伴问,什么是命令行参数?请看我的一些理解与解释,希望可以帮你梳理一下思路
1、 什么是命令行的参数?
如:我在cmd里面,输入了1.路径文件后,2.加上空格,3.再加上后面输入的参数,这个3,就是命令行参数的主要组成部分(前面还附带了文件名,看不懂没关系,我们上图!!!不啰嗦)

这是代码
代码如下
python">res=requests.get('http://www.baidu.com/s?wd='+''.join(sys.argv[1:]))
print(sys.argv[0])
print(sys.argv[1])
print(sys.argv[2])
print(sys.argv[3])
print(sys.argv[0:])
print(sys.argv[1:])
对应起来看,大家会发现命令行参数就是在你输入的参数前,再加上文件名字作为sys.argv[0],依次按照顺序构成列表,看到这里,相信大家应该可以明白命令行参数的基本构成了,那么我们继续!(因为考虑到可能并不是每个人都喜欢用cmd,来输入命令行进行运行程序,所以,我特地安排了在python IDLE中也同样可以输入命令运行,希望可以方便到大家。)
3.找到查询的结果
python">search=input('请输入你要查找的内容')
res=requests.get('http://www.baidu.com/s?wd='+search)#用requests.get获得
res.encoding='utf-8'
res.raise_for_status()#检验是否已经连接
soup=bs4.BeautifulSoup(res.text,'lxml')#后面记得写这个lxml显式指定语法分析器
linkElems=soup.select('div.result h3.t > a')#百度和谷歌的select输入并不相同
4.打开浏览器
python">numOpen=min(5,len(linkElems))#这里我们只获得5条网页返回
for i in range(numOpen):
webbrowser.open(linkElems[i].get('href'))
三、完整代码
python">#! python3
import requests,sys, webbrowser,bs4,os
if len(sys.argv)>1:
res=requests.get('http://www.baidu.com/s?wd='+''.join(sys.argv[1:]))
else:
search=input('请输入你要查找的内容')
res=requests.get('http://www.baidu.com/s?wd='+search)
res.encoding='utf-8'
res.raise_for_status()
os.chdir(r'C:\Users\LX\Desktop')
soup=bs4.BeautifulSoup(res.text,'lxml')
linkElems=soup.select('div.result h3.t > a')
numOpen=min(5,len(linkElems))
for i in range(numOpen):
webbrowser.open(linkElems[i].get('href'))
最后展示一下显示结果,先方法一,不用命令行参数


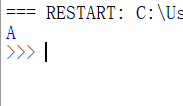
方法二,用命令行参数


可以看到,再次打开5个页面
这次就到这里,谢谢大家