--首先,感谢黑板客老师做了这个爬虫闯关系列,让大家学习到不少知识。
第一关:将网页提示的数字加在网址后面
解题思路:
1、找到数字对应的html标签,用正则匹配标签内容。
2、将数字提取出来加到第一关网址后面,获取新的数字。
解题过程:
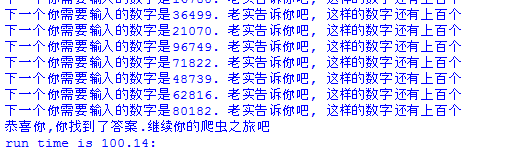
第二关:

解题思路:从0~30依次尝试登录。

第三关:在第二关的基础上加了两层保护
1、访问第三关时会跳转到一个登录页面,必须先登录(测试帐号:username:test;password:test123)。

2、登录时有一个CSRF参数。
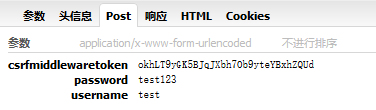
解题思路:
1、先发一个GET请求获取登录页面,将服务器返回的csrftoken保存。
2、尝试用username:test;password:test123;csrftoken登录。登录成功后保存服务器返回的新csrftoken。
3、尝试用username:test;password:(0~30);csrftoken登录。
解题过程:

python">#!/usr/bin/python
# codeing:utf-8
# Be hxs
import re
import time
from threading import Thread
try:
import requests
except ImportError:
print "import requests error"
exit(0)
def print_run_time(func):
"""
装饰器函数,输出运行时间
"""
def wrapper(self, *args, **kw):
local_time = time.time()
# print args),kw
func(self)
print 'run time is {:.2f}:'.format(time.time() - local_time)
return wrapper
class hbk_crawler(object):
"""黑板客爬虫闯关"""
def __init__(self): pass
#super(hbk_exxx, self).__init__()
def login(self, level):
"""登录函数 input:第几关"""
self.url = 'http://www.heibanke.com/lesson/crawler_ex' + level
self.login_url = 'http://www.heibanke.com/accounts/login/?next=/lesson/crawler_ex' + level
self.s = requests.session()
print u"正在登录第{}关....".format(int(level)+1)
try:
self.csrftoken = self.s.get(self.login_url).cookies['csrftoken']
except:
print u"网络连接错误,请重试..."
exit()
self.payload = {'username': 'test', 'password': 'test123',
'csrfmiddlewaretoken': self.csrftoken}
self.payload['csrfmiddlewaretoken'] = self.s.post(
self.login_url, self.payload).cookies['csrftoken']
print u"登录成功...."
return None
@print_run_time
def ex01(self, *args, **kw):
""" 第1关:找密码"""
url = 'http://www.heibanke.com/lesson/crawler_ex00/'
num = ''
while True:
content = requests.get(url + str(num)).text
pattern = r'<h3>(.*)</h3>'
result = re.findall(pattern, content)
try:
num = int(
''.join(map(lambda n: n if n.isdigit() else '', result[0])))
except:
break
print result[0]
print result[0]
@print_run_time
def ex02(self, *args, **kw):
""" 第2关:猜密码 """
url = 'http://www.heibanke.com/lesson/crawler_ex01/'
payload = {'username': 'test', 'password': 0}
for n in range(30):
payload['password'] = n
content = requests.post(url, payload).text
pattern = r'<h3>(.*)</h3>'
result = re.findall(pattern, content)
print "try enter {} ...".format(n), result[0]
if u"错误" not in result[0]:
break
@print_run_time
def ex03(self, *args, **kw):
""" 第3关:猜密码,加入了登录验证,CSRF保护 """
self.login('02')
for n in range(30):
self.payload['password'] = n
content = self.s.post(self.url, self.payload).text
pattern = r'<h3>(.*)</h3>'
result = re.findall(pattern, content)
print "try enter {} ...".format(n), result[0]
if u"错误" not in result[0]:
break
def parseurl(self, url):
"""分析网页,查找密码位置和值"""
while self.count < 100:
response = self.s.get(url)
if response.ok:
content = response.text
pos_pattern = r'_pos.>(.*)</td>'
val_pattern = r'_val.>(.*)</td>'
pos_list = re.findall(pos_pattern, content)
val_list = re.findall(val_pattern, content)
for pos, val in zip(pos_list, val_list):
if pos not in self.pw_dict:
self.pw_dict[pos] = val
self.count = self.count + 1
print str(self.count) + '%' + self.count // 2 * '*'
@print_run_time
def ex04(self, *args, **kw):
""" 第4关:找密码,加入了登录验证,CSRF保护,密码长度100位,响应时间增加 """
self.count = 0
self.login('03')
self.pw_dict = {}
pw_url = ('http://www.heibanke.com/lesson/crawler_ex03/pw_list',)
# 线程数,黑板客服务器15秒内最多响应2个请求,否则返回404.
n = 2
threads = [Thread(target=self.parseurl, args=(
pw_url)) for i in xrange(n)]
for t in threads:
print t.name, 'start...'
t.start()
for t in threads:
t.join()
self.pw_list = ['' for n in range(101)]
for pos in self.pw_dict.keys():
self.pw_list[int(pos)] = self.pw_dict[pos]
password = int(''.join(self.pw_list))
self.payload['password'] = password
response = self.s.post(self.url, self.payload)
pattern = r'<h3>(.*)</h3>'
result = re.findall(pattern, response.text)
print result[0]
if __name__ == '__main__':
Hbk_crawler = hbk_crawler()
Hbk_crawler.ex01()
Hbk_crawler.ex02()
Hbk_crawler.ex03()
Hbk_crawler.ex04()