2019独角兽企业重金招聘Python工程师标准>>> 
1.Scrapy架构图
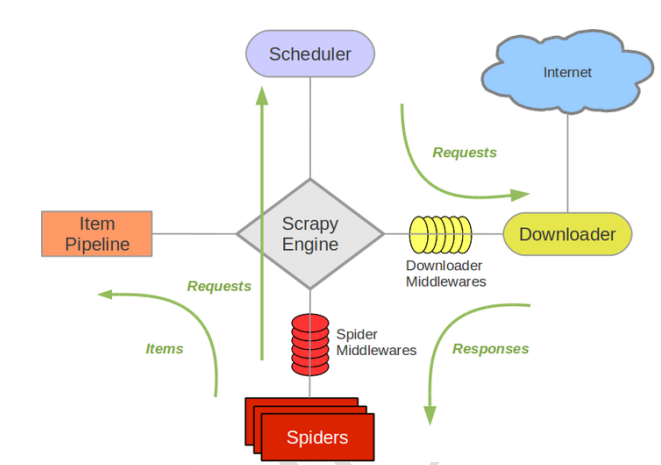
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
2.Scrapy执行流程图
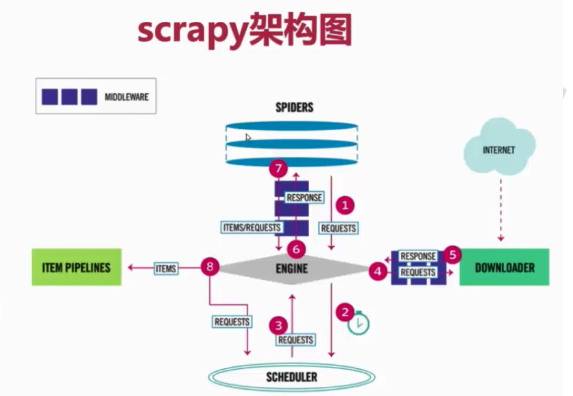
3.执行顺序
(1)SPIDERS的yeild将request发送给ENGIN
(2)ENGINE对request不做任何处理发送给SCHEDULER
(3)SCHEDULER( url调度器),生成request交给ENGIN
(4)ENGINE拿到request,通过MIDDLEWARE进行层层过滤发送给DOWNLOADER
(5)DOWNLOADER在网上获取到response数据之后,又经过MIDDLEWARE进行层层过滤发送给ENGIN
(6)ENGINE获取到response数据之后,返回给SPIDERS,SPIDERS的parse()方法对获取到的response数据进行处理,解析出items或者requests
(7)将解析出来的items或者requests发送给ENGIN
(8)ENGIN获取到items或者requests,将items发送给ITEM PIPELINES,将requests发送给SCHEDULER
4.配置文件(spiders/settings.py)
BOT_NAME = 'mySpider'# 创建项目名称
SPIDER_MODULES = ['mySpider.spiders']#爬虫模块的位置
NEWSPIDER_MODULE = 'mySpider.spiders'#新爬虫模块的位置
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'mySpider (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False# 是否要遵循爬虫协议,咱们不遵循,设置为Fasle或者注释掉即可
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32#爬虫的并发量,默认是16
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3#下载延迟配置,默认是0,以后可以设置2或者1.5都行
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16#每个域的并发请求
#CONCURRENT_REQUESTS_PER_IP = 16#每个IP 16的并发请求
# Disable cookies (enabled by default)
COOKIES_ENABLED = False#是否启用cookie,默认是启用,要设置不起来,防止别人知道我们
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False#禁用telnet控制台(默认启用)
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#爬虫中间件,一般用不着
#SPIDER_MIDDLEWARES = {
# 'mySpider.middlewares.MyspiderSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#下载中间件,以后下载的时候可以用,后面的值是优先级,数字越小优先级越高
#DOWNLOADER_MIDDLEWARES = {
# 'mySpider.middlewares.MyspiderDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#管道文件,以后经常下,作用是下载的数据处理
#ITEM_PIPELINES = {
# 'mySpider.pipelines.MyspiderPipeline': 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5#初始下载延迟
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60#在高延迟情况下要设置的最大下载延迟。
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
5.scrapy常用的命令:
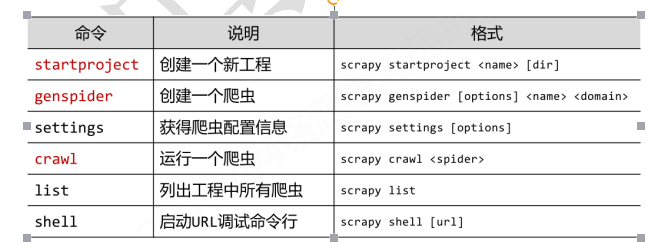
6.创建scrapy的爬虫项目:- ---- scrapy startproject mySpider

下面来简单介绍一下各个主要文件的作用:
scrapy.cfg :项目的配置文件,不能删除
mySpider/ :项目的Python模块,将会从这里引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ :存储爬虫代码目录
7.用命令自动生成爬虫部分代码
scrapy genspider Baidu "baidu.com"
8.运行爬虫----scrapy crawl Baidu