从今天开始我会把我学习python爬虫的一些心得体会和代码发布在我现在的博客,好记性不如烂笔头,以便以后的我进行复习。
虽然我现在的爬虫还很幼小,希望有一天她能长得非常非常的强大。
--------------------2018.11.22---------------------------------------------------------------------------------------------------------------------------------
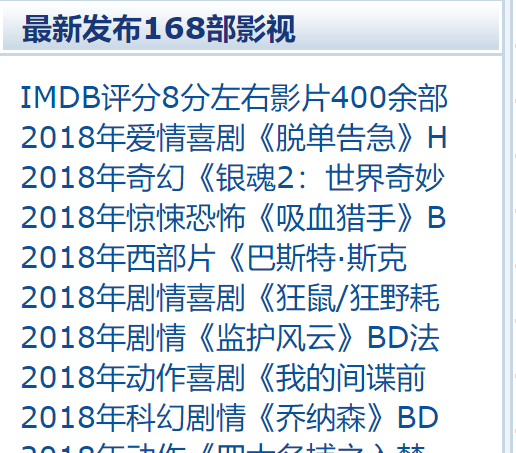
OK,废话少说。今天爬取的是电影天堂网站左边框的一个container。
环境我准备好了,所以我就开始了。
首先,为了我测试时的速度和不影响人家网站的服务器,我决定把电影天堂页面的html下载到本地
代码如下:
1 #下载网页 2 def downloadhtml(): 3 url = 'https://www.dytt8.net' 4 headers = {'User-Agent':'Mozilla/5.0'} 5 r = requests.get(url,headers=headers) 6 with open('C:/Code/newhtml1.html','wb') as f: 7 f.write(r.content) 8 downloadhtml()
这里值得一提的是,抓取下来的HTML格式是二进制的,所以保存文件时要用wb。
保存好HTML文件,我就可以尽情地调戏,不对,调试这个网站了的数据。
第一步:分析数据
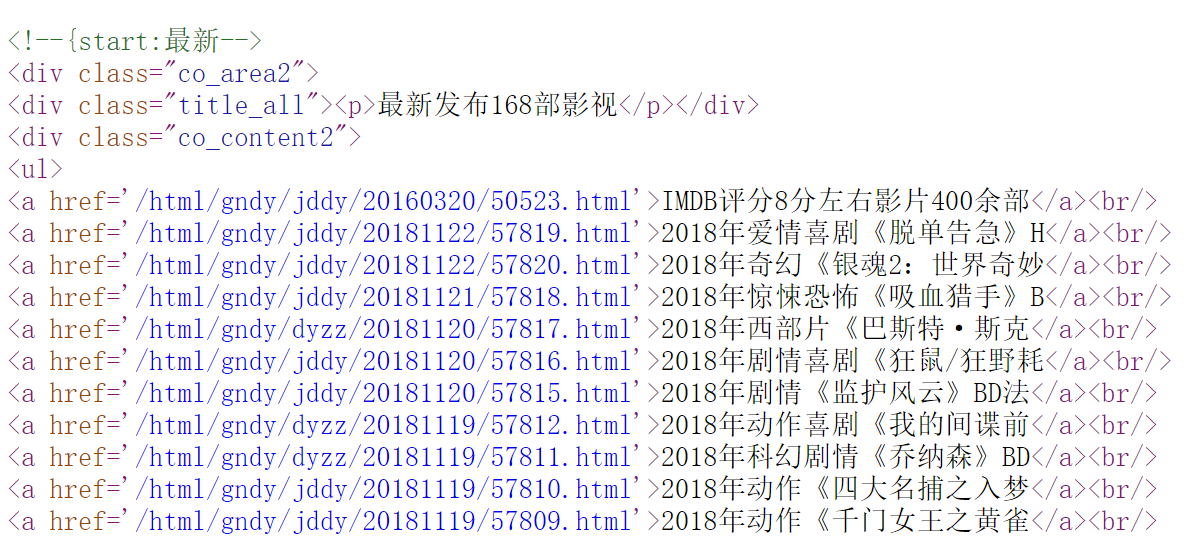
打开网页的源代码,我们发现我们需要的数据被装在一个ul标签里。
Ctrl+F在源代码里查看<ul>标签,发现我们需要的ul标签是第三个标签。
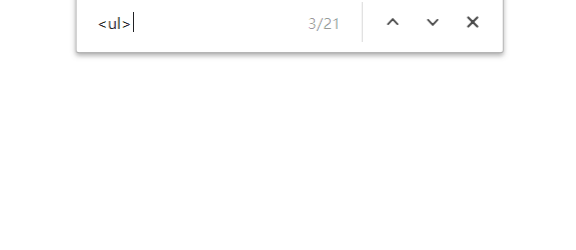
这样我们就知道该爬哪里了。
第二步:解析数据
刚才下载的网页现在可以用上了,定义一个函数让BeautifulSoup能用上这个HTML网页
如:soup = BeautifulSoup(html,'html.parser')里面的html参数就可以用htmlhandle这个变量填上。
1 def send_html(): 2 path = 'C:/Code/newhtml1.html' 3 htmlfile=open(path,'r') 4 htmlhandle = htmlfile.read() 5 return htmlhandle
开始分析数据,
先贴代码吧:
1 def get_pages(html): 2 soup = BeautifulSoup(html,'html.parser') 3 for ul in soup.find_all('ul')[2]: 4 if isinstance(ul,bs4.Tag): 5 Tag_name=ul.get_text() 6 Tag_href=ul.get('href') 7 if Tag_name!= '': 8 print('名称:{},地址:{}'.format(Tag_name,Tag_href))
解释下代码
先用BeautifulSoup的find_all()函数找到所有ul标签,因为后面加了[2],所以找到是第三个ul标签。
在这里我们离我们的目标很近了。
但这里我们能发现find_all()遍历返回的值的类型是不同的,我们利用type(ul)就能发现,它其中参杂两种类型:
<class 'bs4.element.NavigableString'>
<class 'bs4.element.Tag'>
<class 'bs4.element.Tag'>
字符串和Tag,测试一下就能知道字符串类型是空的,我们需要的Tag类型。
所以用isinstance来判断是否是Tag类型,如果不是,就不要了。输出如下:
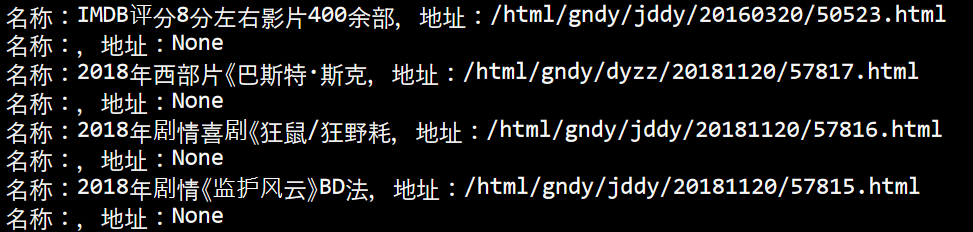
我们发现,中间还参杂了一些无效的条目,仔细看上面就能发现它返回是有两个Tag类型的,其中一个是什么都没有装的,是导致这个无效条目的原因。
所以把这条无效的条目给过滤掉吧
if Tag_name!= '': print('名称:{},地址:{}'.format(Tag_name,Tag_href))
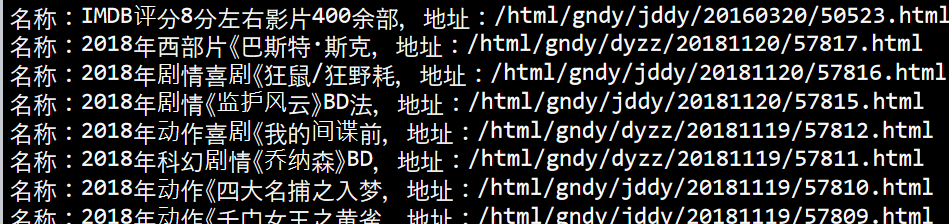
到这里,我们就完成了本次抓取。
下面附上总代码:
1 import requests 2 import re 3 from bs4 import BeautifulSoup 4 import bs4 5 6 def send_html(): 7 path = 'C:/Code/newhtml1.html' 8 htmlfile=open(path,'r') 9 htmlhandle = htmlfile.read() 10 return htmlhandle 11 12 def get_pages(html): 13 soup = BeautifulSoup(html,'html.parser') 14 for ul in soup.find_all('ul')[2]: 15 #print(type(ul)) 16 if isinstance(ul,bs4.Tag): 17 Tag_name=ul.get_text() 18 Tag_href=ul.get('href') 19 if Tag_name!= '': 20 print('名称:{},地址:{}'.format(Tag_name,Tag_href)) 21 22 get_pages(send_html())



![DWM1000 多个标签定位讨论 --[蓝点无限]](https://img2018.cnblogs.com/blog/149290/201811/149290-20181122223436281-1723664052.png)
