用Scrapy爬取百度图片
前段时间用python的requests库和BeautifulSoup库爬取了猫眼电影关于柯南剧场版的6000条评论
这次我们来使用Scrapy框架来实现爬虫任务——百度“唯美图片”的爬取
整个项目的工程源码我已经上传到GitHub上了,感兴趣的同学可以自行下载,能顺便给我的项目一个star那再好不过了
点击该链接跳转至项目地址
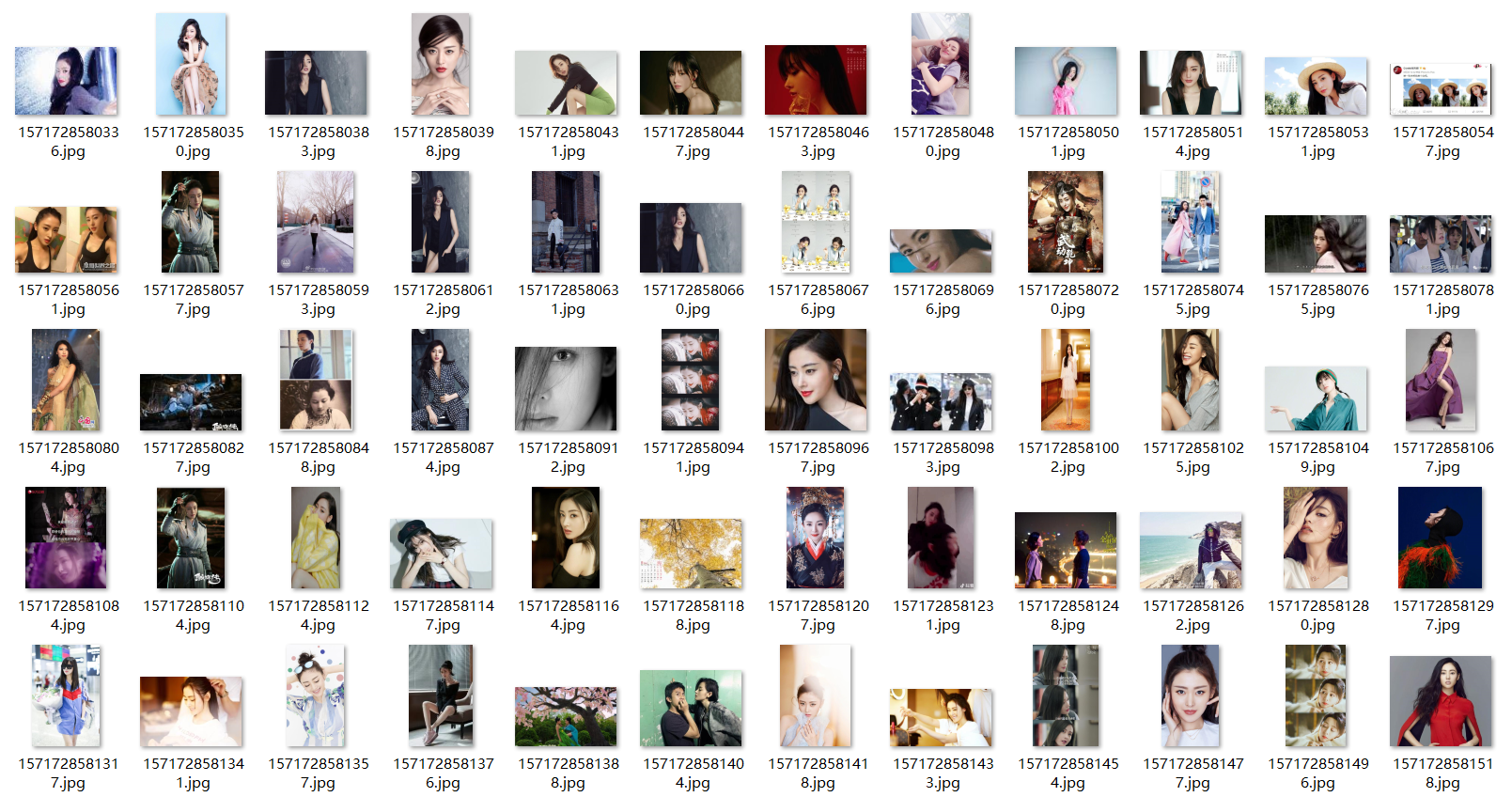
先展示下我们爬取的结果
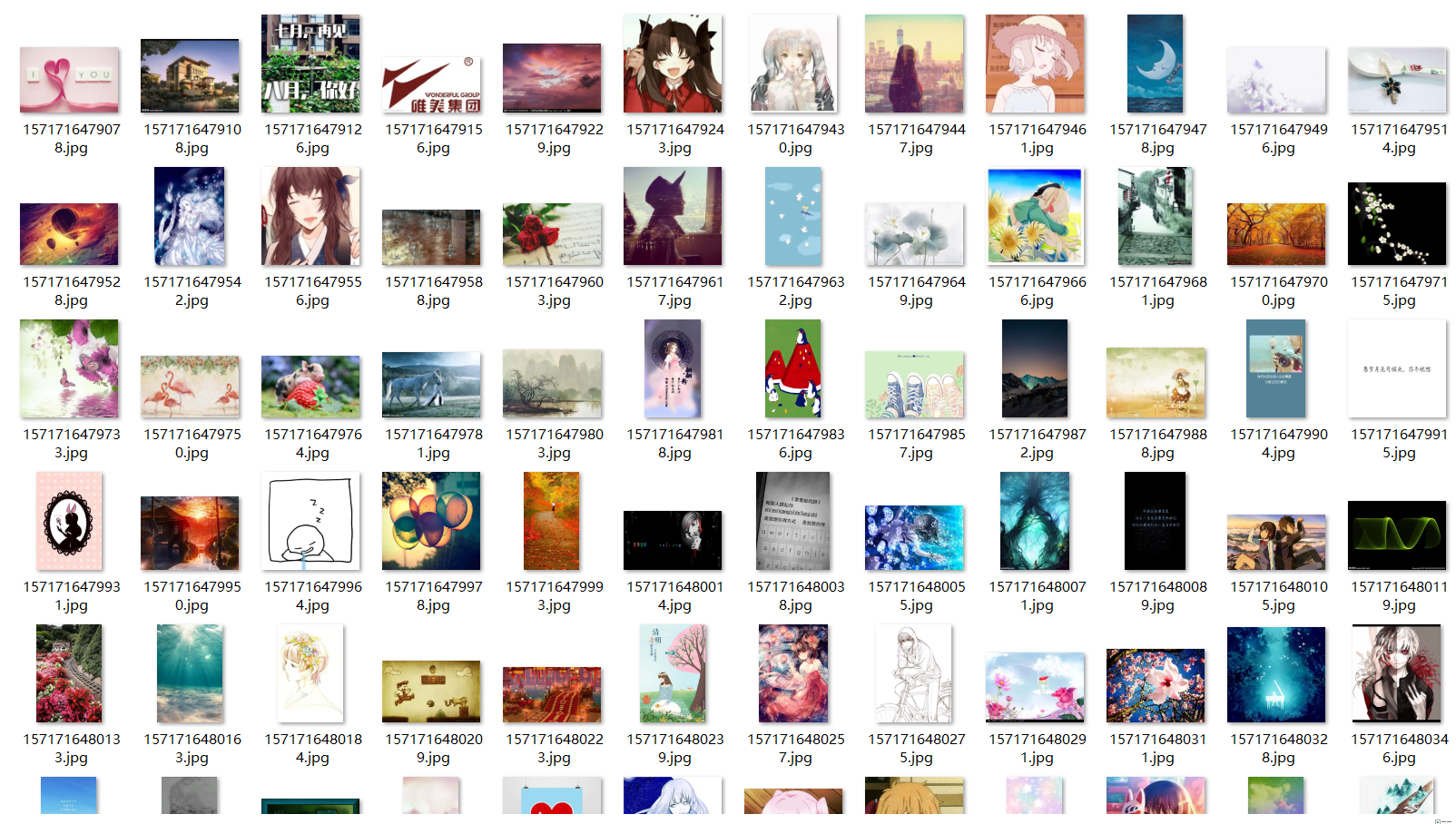
看着爬取下来的这一张一张的图,内心的满满的成就感有没有,哈哈,那接下来就跟着我一起来看看如何去实现图片的爬取吧
一、准备工作
我们此次用到的工具有:
- python3.7.3
- PyCharm5.0.3
- Scrapy1.7.4
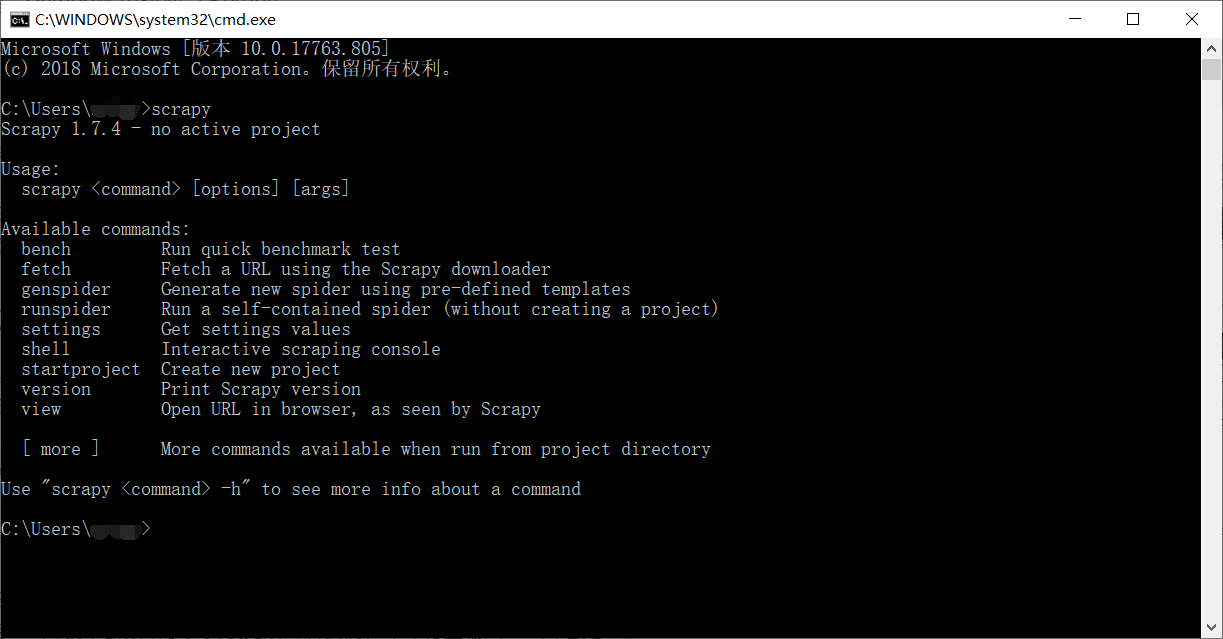
没有安装scrapy的直接在命令行里pip install scrapy安装scrapy框架,在windows环境下安装scrapy开始会报错,这是因为安装scrapy要安装其它的一些依赖库,lxml、pyOpenSSL、Twisted 、pywin32。安装好这些库之后,再去安装scrapy就不会报错了。安装完成之后我们在命令行里输入scrapy看是否安装成功,结果如下:
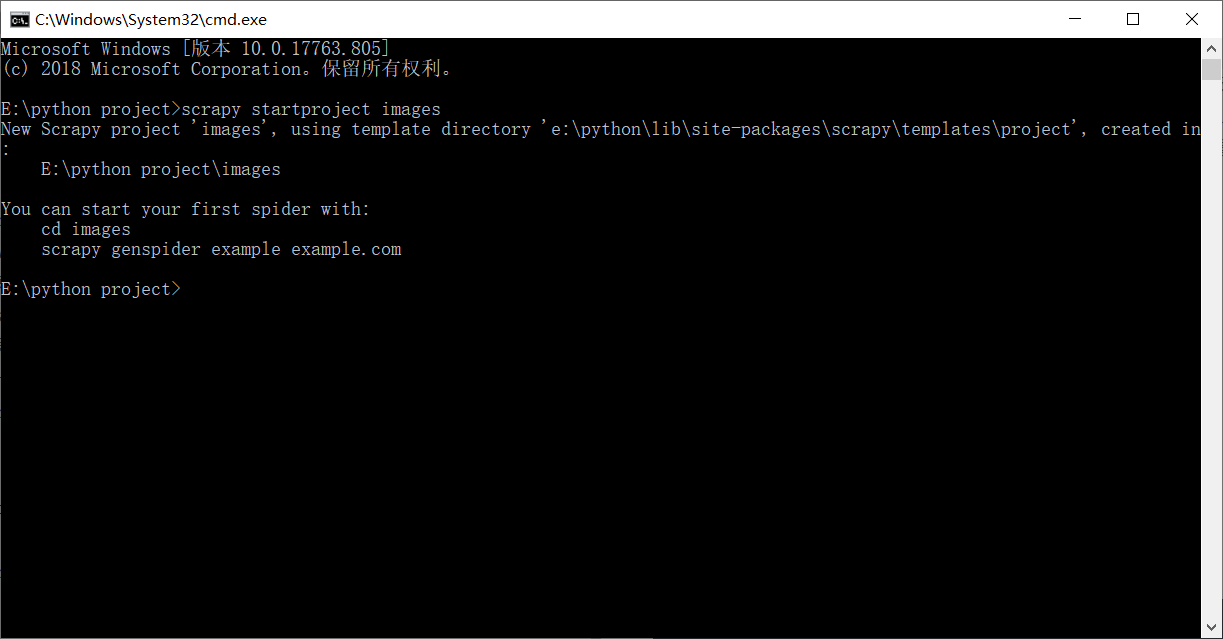
然后我们开始创建Scrapy项目,在命令行输入:
python">scrapy startproject XXX
其中XXX表示的是你的项目名称,在这里我取名为images
然后用PyCharm打开这个项目文件夹,发现其目录结构如下:
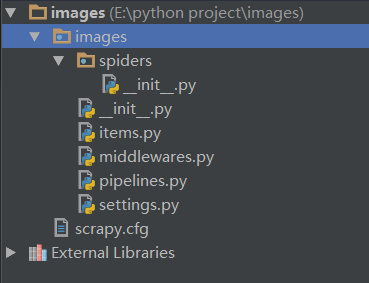
item是爬取之后保存数据的容器,其用法类似于python里的字典。这些文件可以先不用管,等我之后用到的时候会给大家讲解的。
二、网页数据分析
打开百度图片的网页搜索唯美图片

进入搜索结果之后,打开开发者模式,我发现这里面的图片数据全部都是动态加载的,这个时候就不能用平常的获取网页结构的方式来获取我们需要的数据了。这个时候我在过滤栏输入json,看一下是不是有相应的json数据传输。
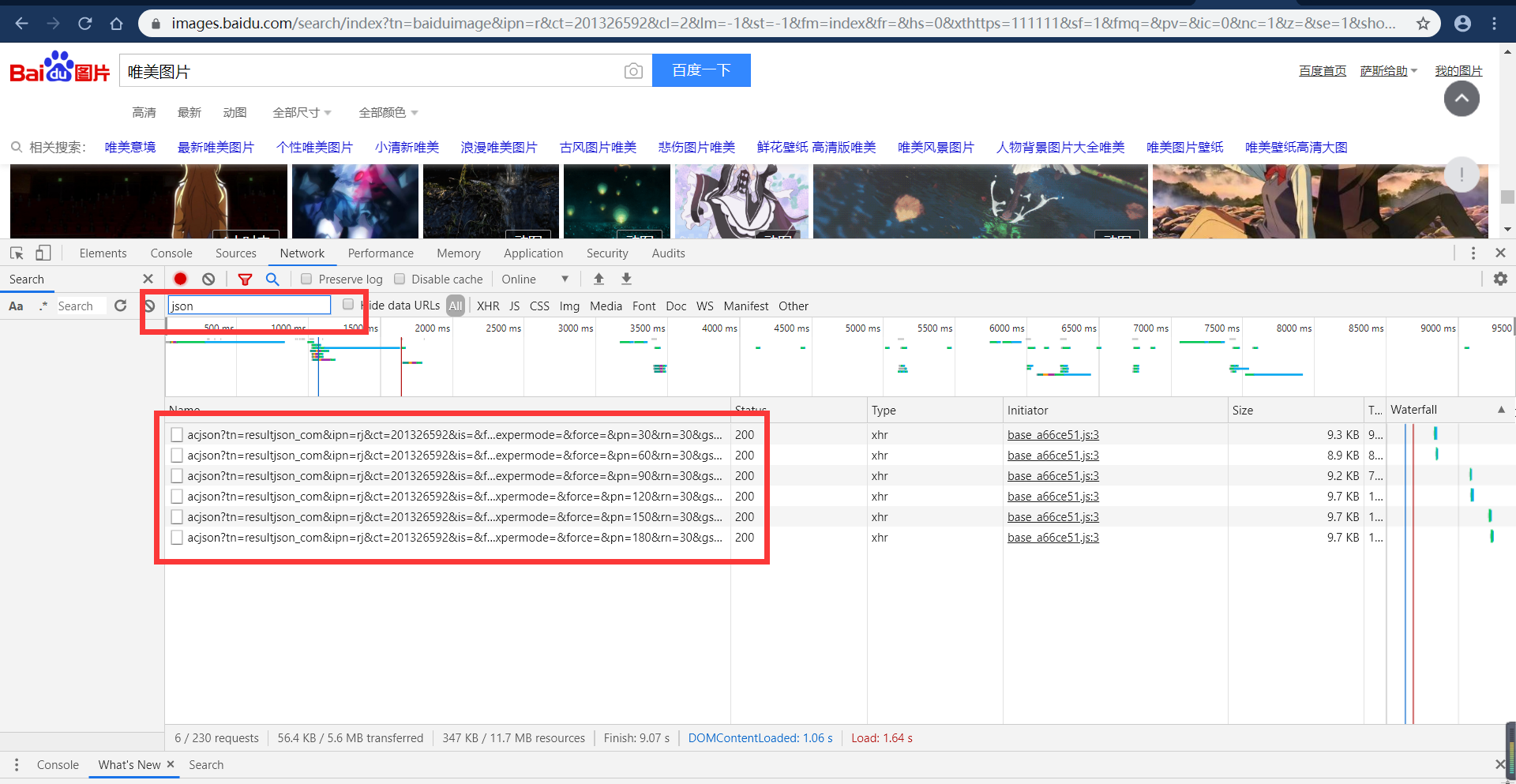
果不其然,让我发现了对应的json数据,我们打开一个json数据来看一下,里面是否有我们想要的图片的url地址,果然找到了
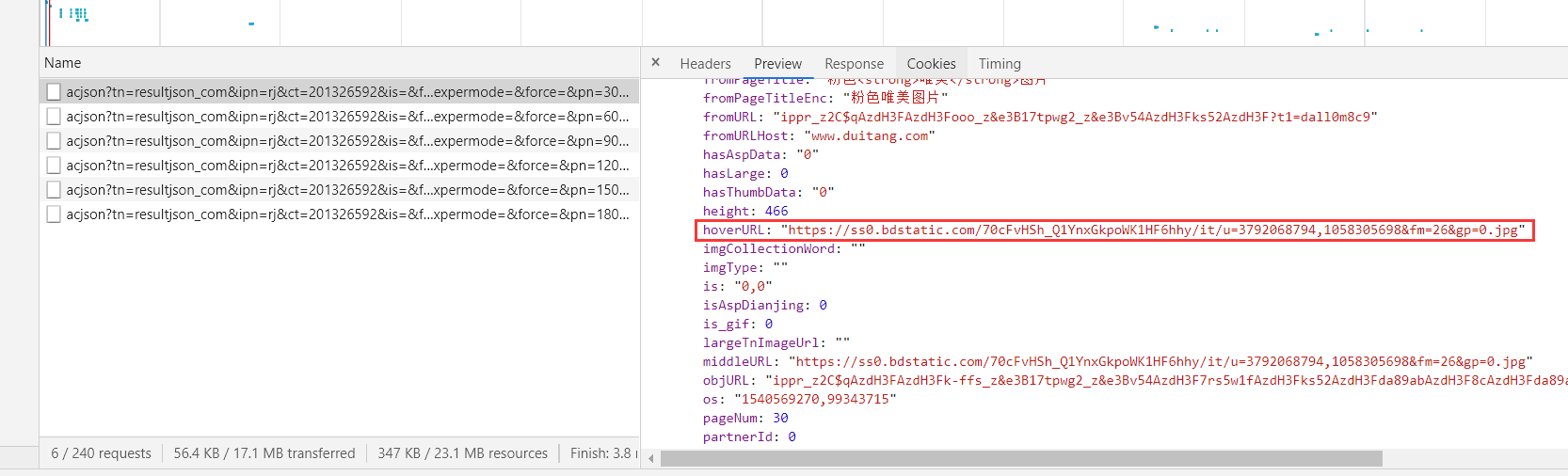
那接下来我们就来分析下这个请求json数据的链接的规律,我选取三个json数据的链接,将他们放在一起比对,我们发现只有几个参数不同,其它的都相同,不同的几个参数是pn和gsm而rn都是30,而且gsm分别是1571723763553、1571723763651、1571723766127,根据爬虫老司机的经验,gsm表示的是当前的时间,只不过这里用了毫秒表示,然后pn表示的是这个json数据里最后一张图片的索引信息,rn表示的是每一个json数据里代有图片信息的条数


做完了以上的工作之后接下来就好办了,我们的思路就是构造请求json数据的url,然后我们通过scrapy框架请求将请求的数据转换成json格式,之后我们通过key,value的形式以及循环来获取图片的url,然后利用我们的框架获取图片将其保存在指定的目录下。
三、编写代码
首先,我们在spiders目录下建立一个叫做images_spider的文件。这个时候得提到我们的scrapy框架了,我们的scrapy框架里有一个爬虫的抽象类,我们要在spiders目录下建立相对应的文件,并在里面实现对这个类的继承,从而实现爬虫。
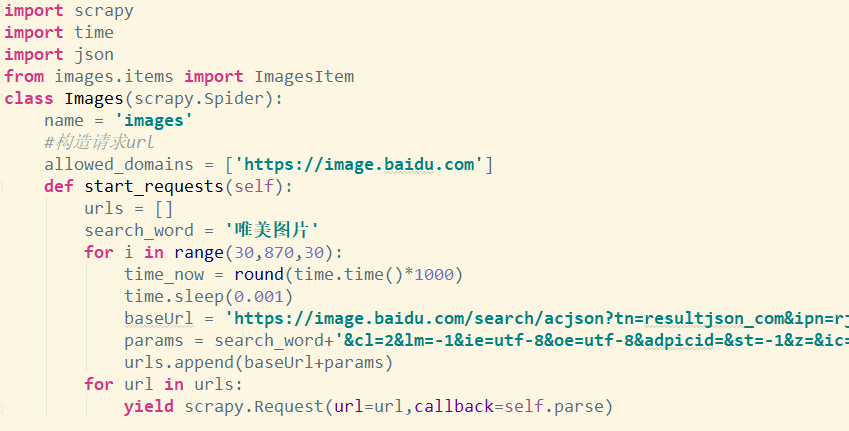
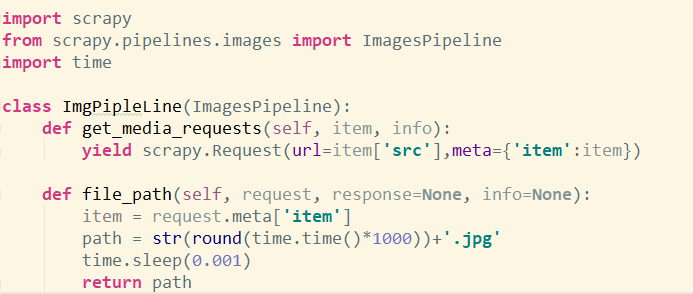
然后我们在这个类里面重写parse方法,这个parse方法在我们这个项目中是用来获取我们的图片链接并将其保存在item里面。然后我们再去重写我们的pipelines.py里面的那个类,那个类是用来处理获取图片链接之后将其保存在我们指定的目录里面。
四、注意事项
在用scrapy框架进行爬虫的时候,一定要更改settings.py的ROBOTSTXT_OBEY,settings.py文件里默认是True的也就是说遵循robots协议,而百度的robots.txt文件里默认是不允许被爬虫的,所以你如果不改这里是无法爬取到百度的数据的。
python">ROBOTSTXT_OBEY = False

五、改进
之前我们是在代码里将要搜索的关键字写在了里面,这样之后我们要爬取另外一种类型的图片的时候又要去代码中修改,这样十分的的不方便,于是我做了一点点修改,当程序运行的时候,读取用户输入的关键字,之后根据用户输入放入关键字来进行图片的爬取。这样我们就能够爬取各种各样的图片了,比如说我输入关键字:张天爱高清壁纸

温馨提示:爬虫要在法律允许的条件下进行
相关文章推荐
- 《用Python爬取猫眼电影里柯南剧场版的6000条评论》
- 《用python爬取笔趣阁小说》
- 《十大经典排序算法之快速排序》
感谢阅读,各位看官点个赞呗



