Crawlab 是一个基于 Go 语言的分布式网络爬虫管理平台,它支持 Python、Node.js、Jar、EXE 等多种类型的爬虫。
Crawlab 提供了一个可视化的界面,并且可以通过简单的配置来管理和监控爬虫程序。
以下是 Crawlab 的一些主要优点:
-
集中管理:Crawlab 允许用户在单一的界面中管理所有的爬虫任务,这使得任务的监控和管理变得更加容易。
-
支持多种编程语言:Crawlab 不局限于特定的编程语言,支持 Python、Node.js、Java、Go 等多种语言编写的爬虫。
-
分布式架构:Crawlab 支持分布式架构,可以轻松扩展到多个服务器以应对大规模的爬取任务。
-
可视化操作:Crawlab 提供一个直观的 Web 界面,可以通过界面进行爬虫的部署、执行、监控和调度。用户无需编写复杂的命令行代码。
-
结果持久化:用户可以将爬取的数据直接存储到 MongoDB、MySQL 等数据库中,Crawlab 内置对这些常见数据库的支持。
-
定时任务:Crawlab 提供了定时任务功能,用户可以定时启动爬虫,实现自动化地数据抓取。
-
便捷的部署方式:Crawlab 可以通过 Docker 容器化部署,大大简化了安装和配置的复杂性。
-
插件系统:Crawlab 提供插件系统,用户可以根据需要安装不同的插件来扩展平台的功能。
-
用户权限管理:Crawlab 提供用户权限管理,可以定义不同用户的操作权限,适用于团队协作环境。
-
API接口:Crawlab 提供 RESTful API,便于与其他系统集成和自动化操作。
以下是简要使用说明。
部署很简单,参考: crawlab开源项目
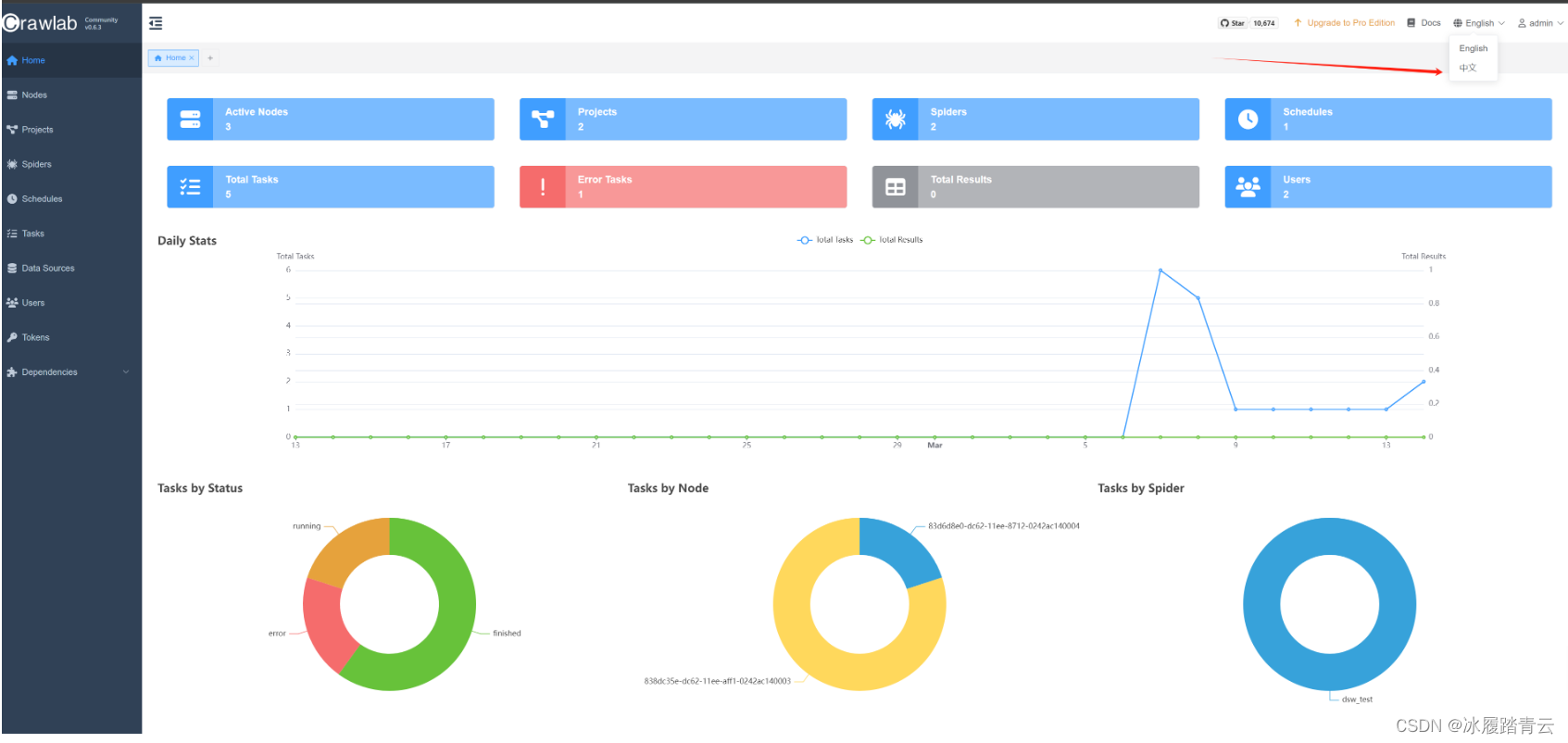
1. 登录
第一次登录进去是英文版的,可以在右上角点击切换为中文:
2. 环境依赖安装
Python 包直接搜索安装即可:
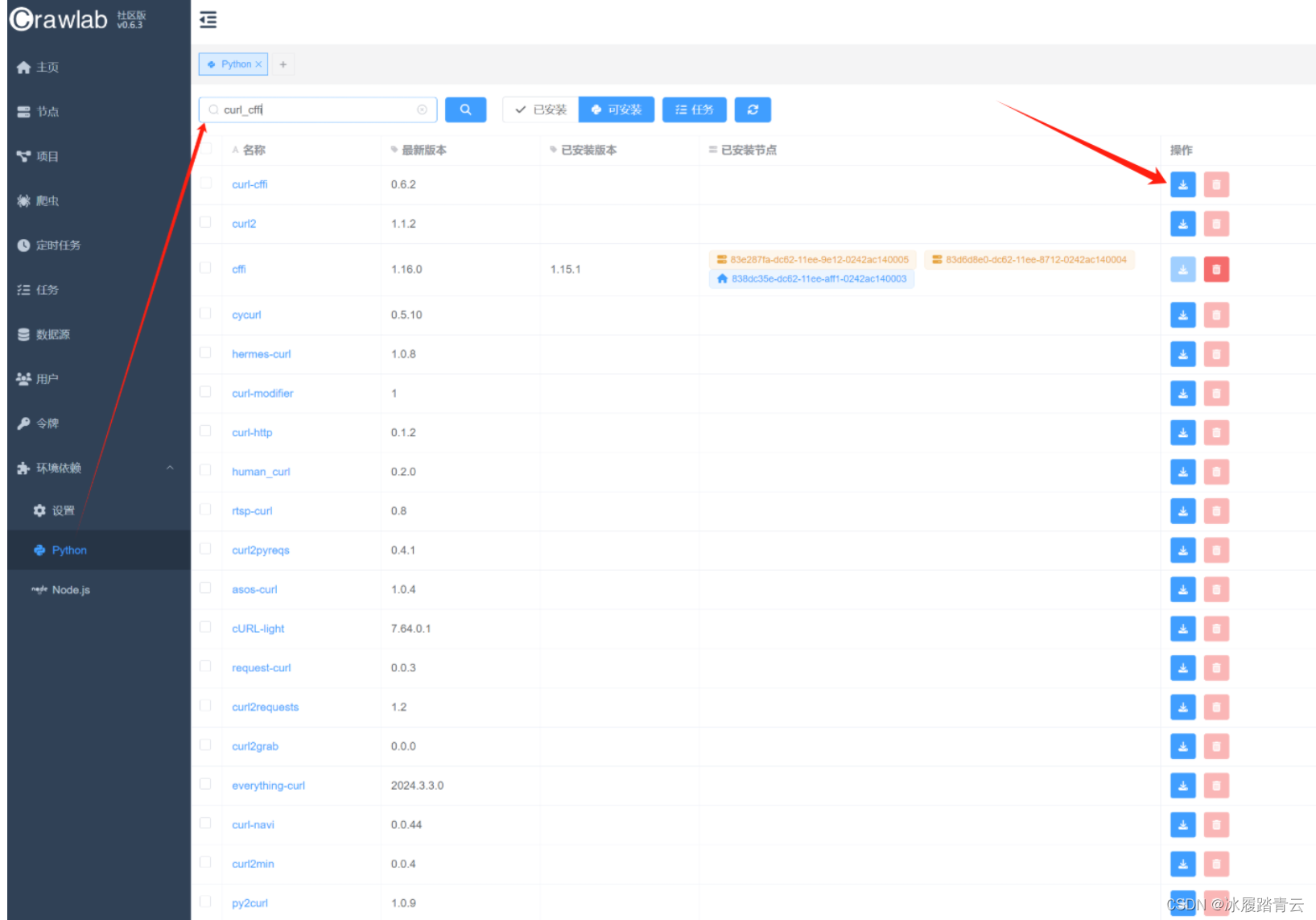
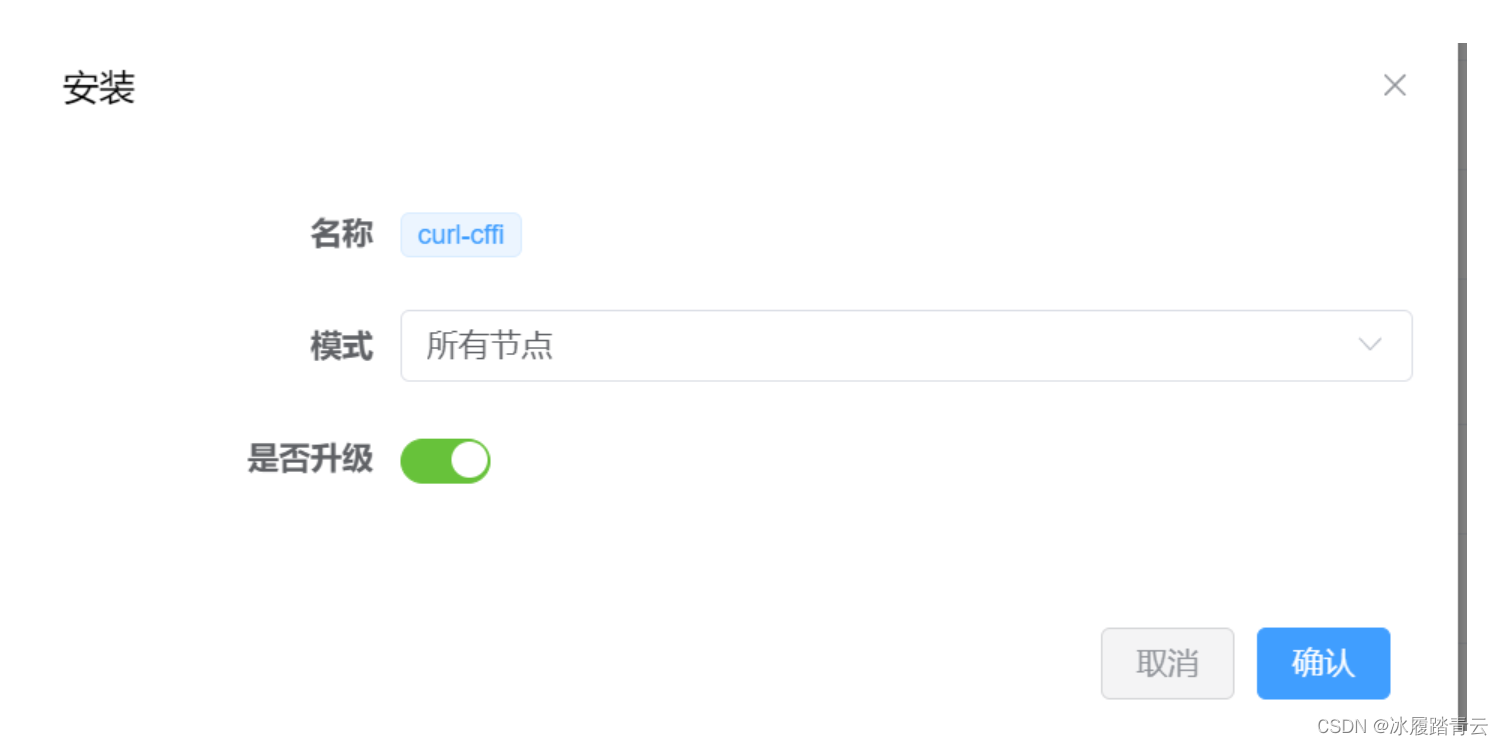
模式选择所有节点,确认即可
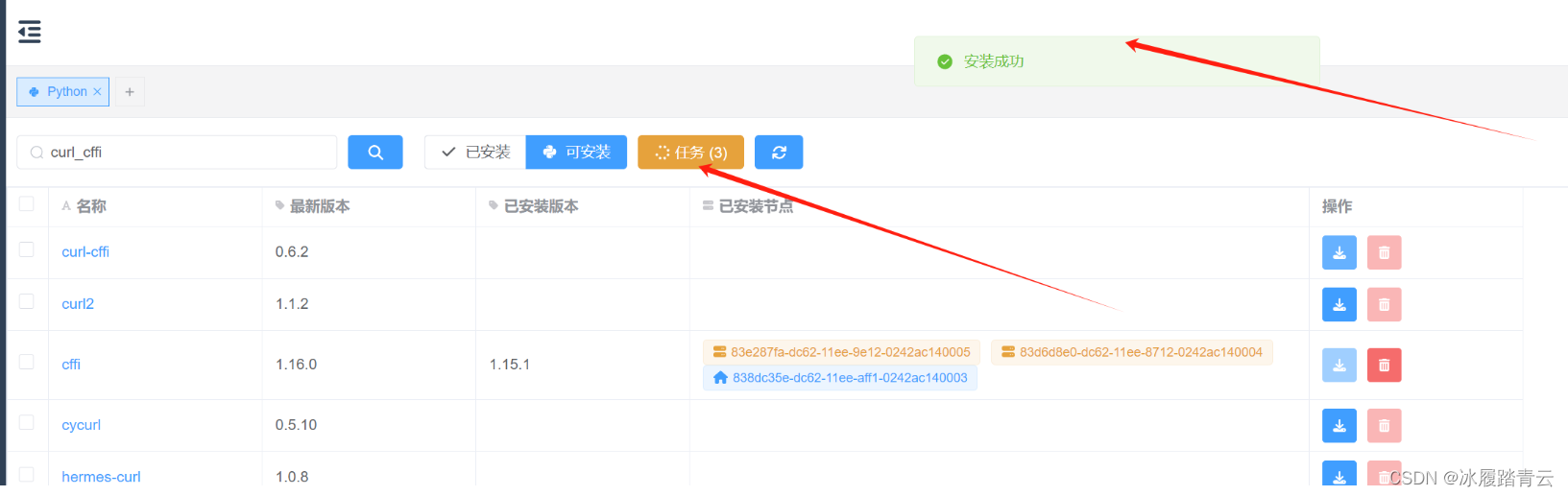
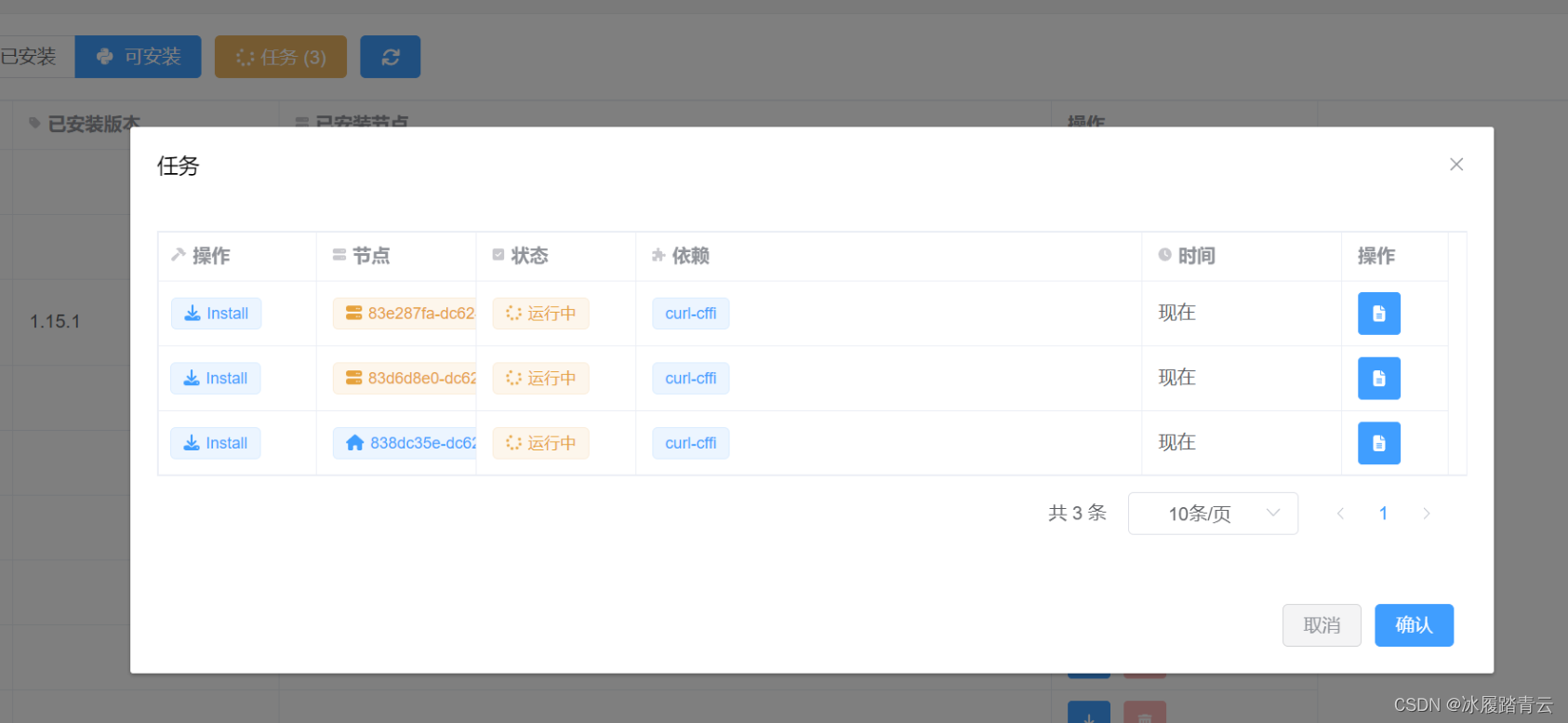
点击任务即可查看安装情况,这里是三个节点都安装:
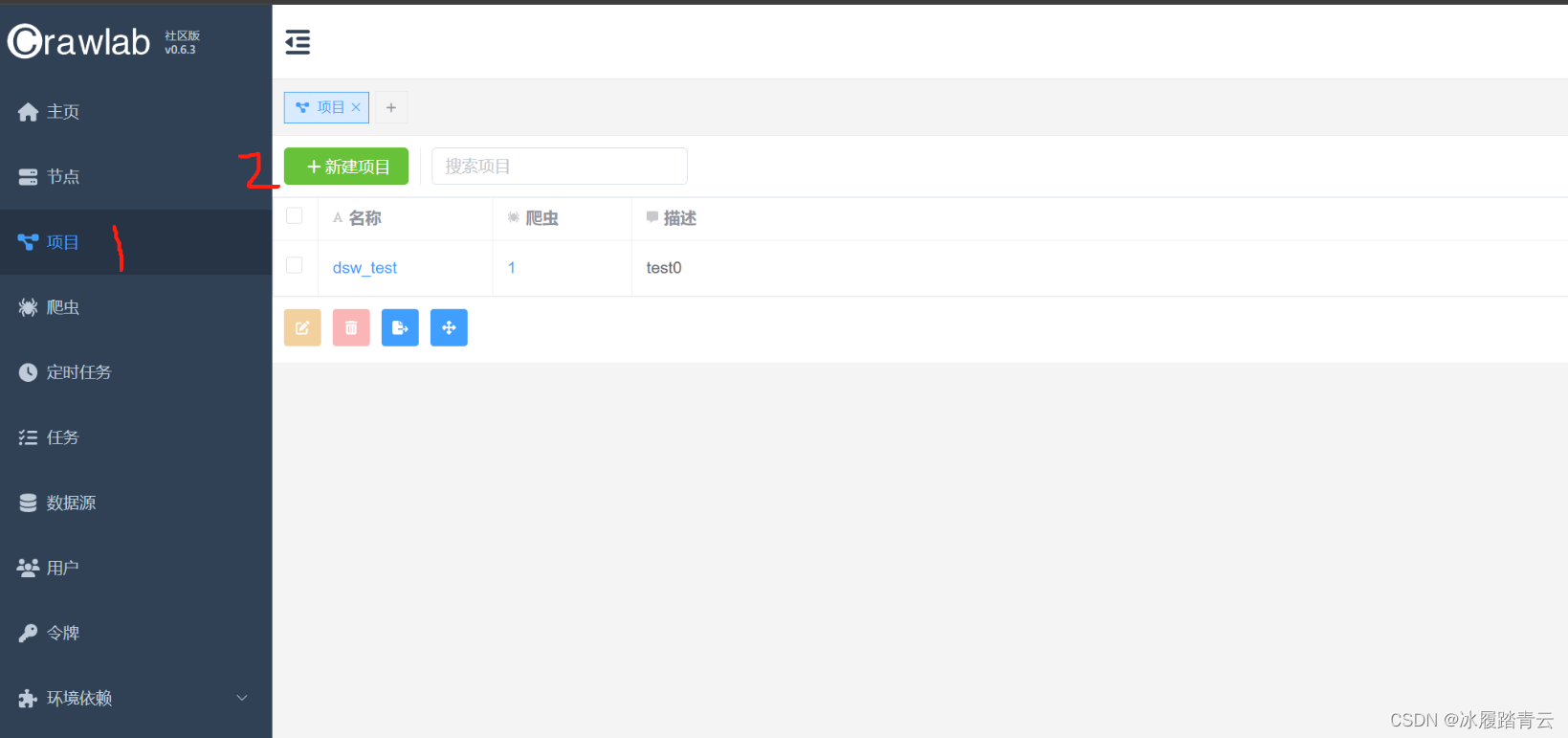
3. 新建项目
点击项目,然后点击新建项目
出现以下界面:

支持单个和批量创建项目,一般来说我们如果的spider都在一个项目下直接建单个的项目就行。
4. 爬虫文件上传与部署
该平台支持文件夹上传,上传爬虫步骤如下,点击爬虫,然后点击新建爬虫
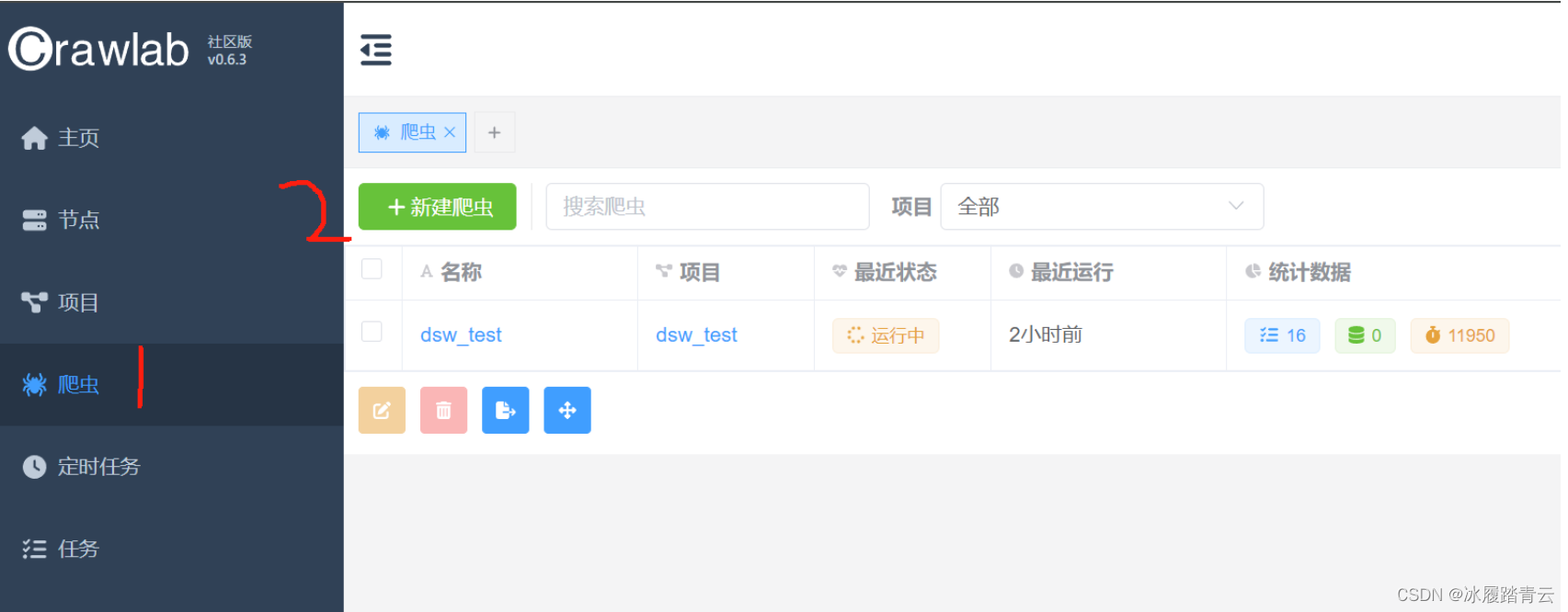
名称随便写,最好写spider名字便于区分;
项目就选择我们之前创建的项目名字;
执行命令就是输入要执行的命令,如果是scrapy项目就直接像上面那样直接写就行,如果是其他python项目就输入类似 python demo.py 的命令;
参数可以不填
增量同步文件最好还是开启一下,主要是用于在更新或编辑爬虫代码时,只同步那些有变化的文件,而不是每次都同步所有文件;
其他的默认就行。
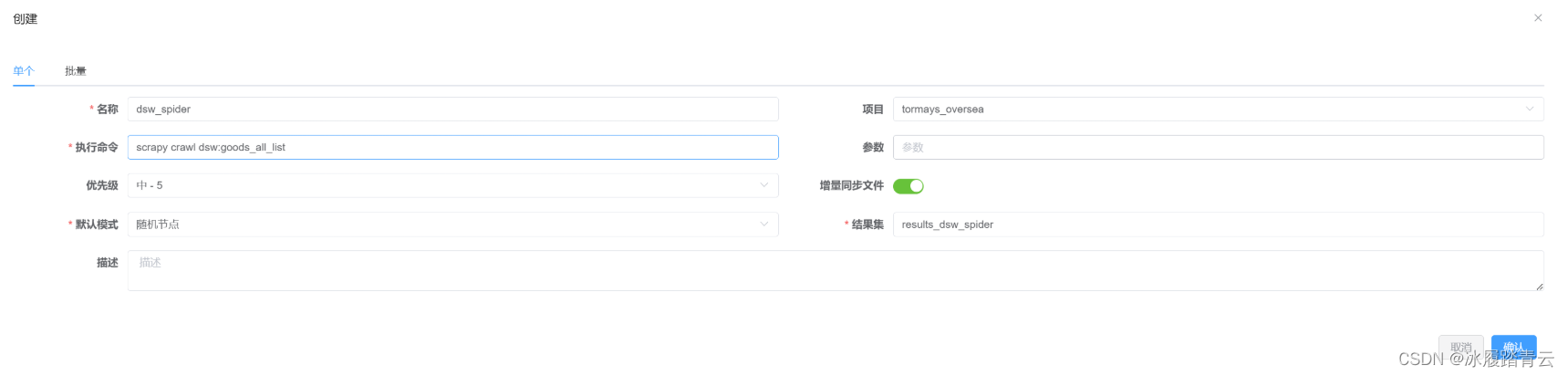
这里也支持批量创建爬虫:
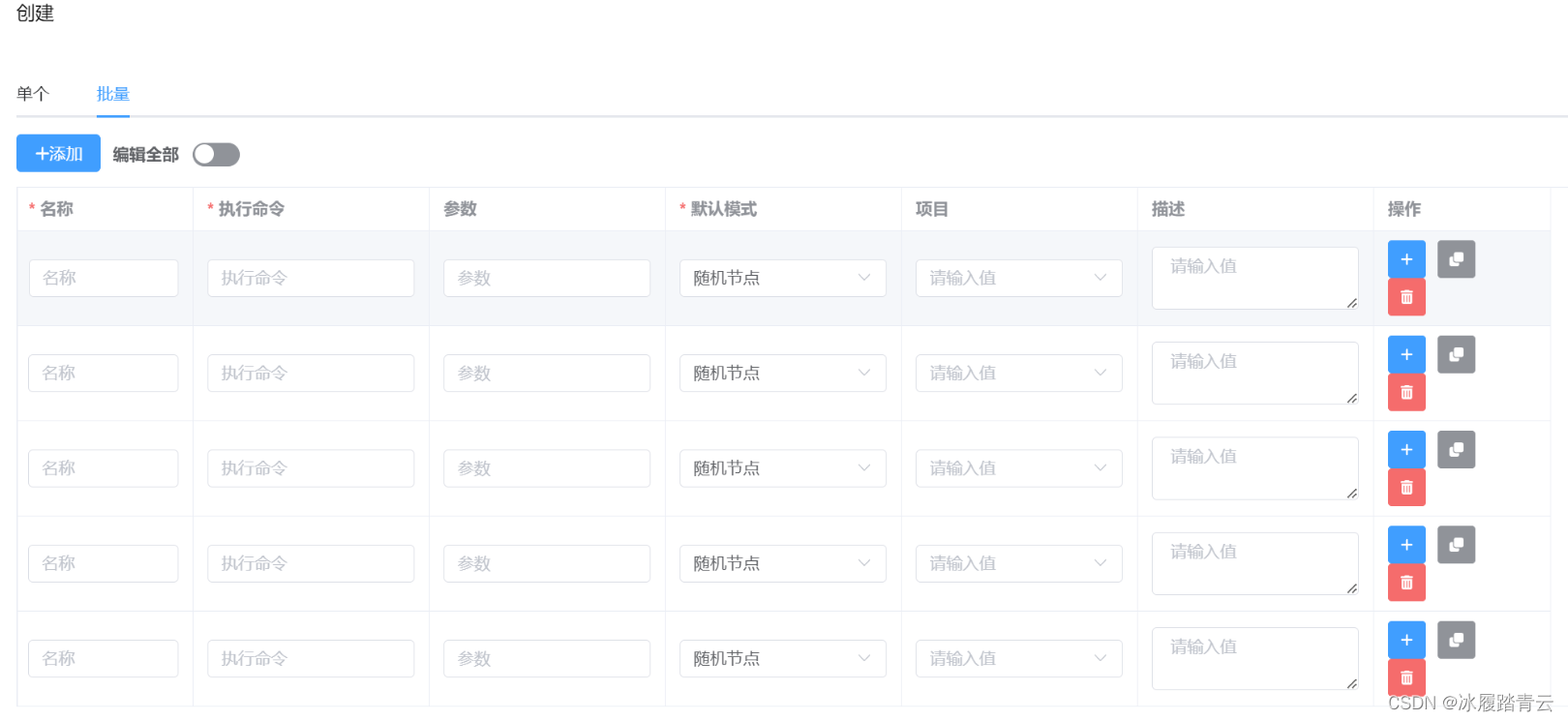
正常情况下我们的scrapy项目下会有多个spider,所以用批量部署更方便。
我这里写测试只放了一个spider,
爬虫参数都填好后再点击确认:

就看到爬虫目录里已经有dsw_spider了。
本地上传文件直接点击上传文件图标即可:

可以直接点击选择目录上传

然后选择项目目录,确认上传就可以了
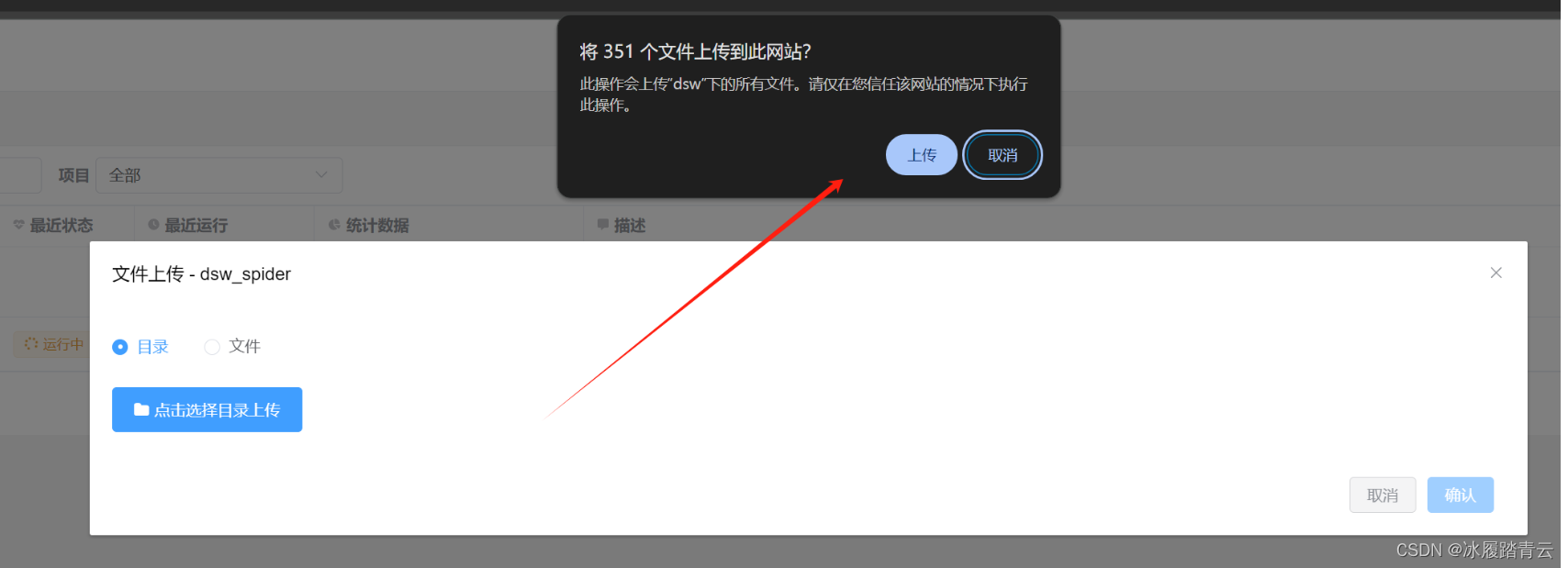

点击确认,会出现上传成功提示

这个时候就算把爬虫上传成功了,要调用可以直接点这个运行
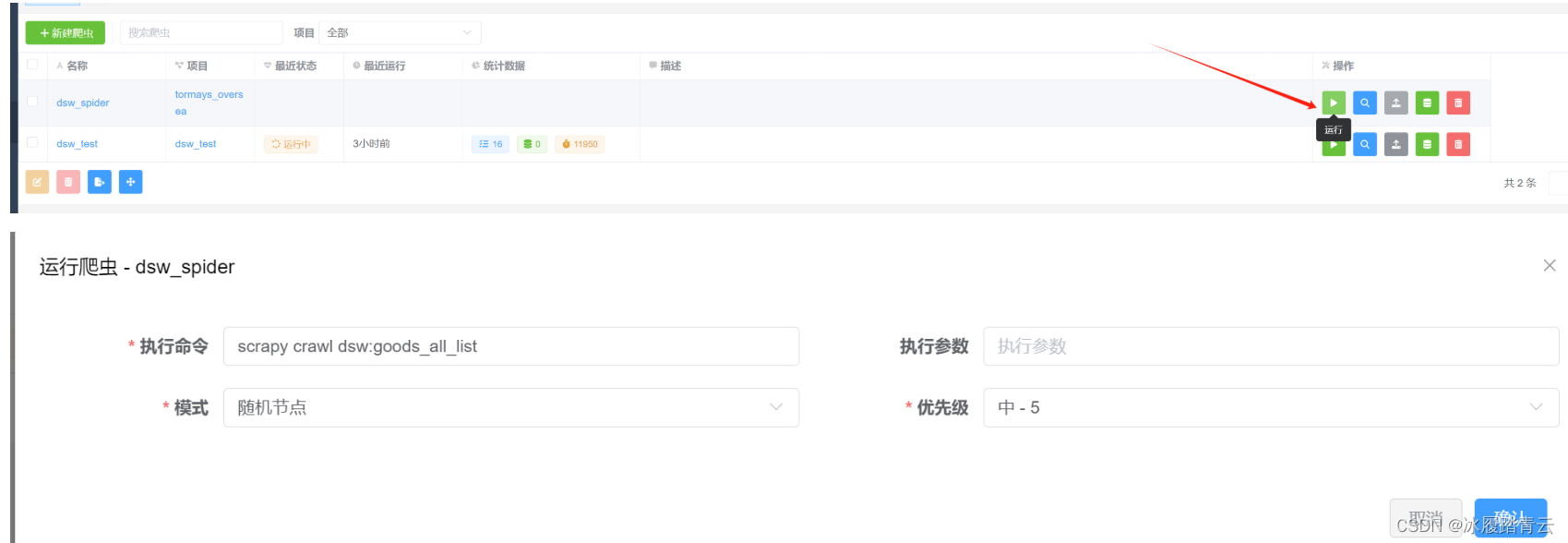
点确认即开始运行,
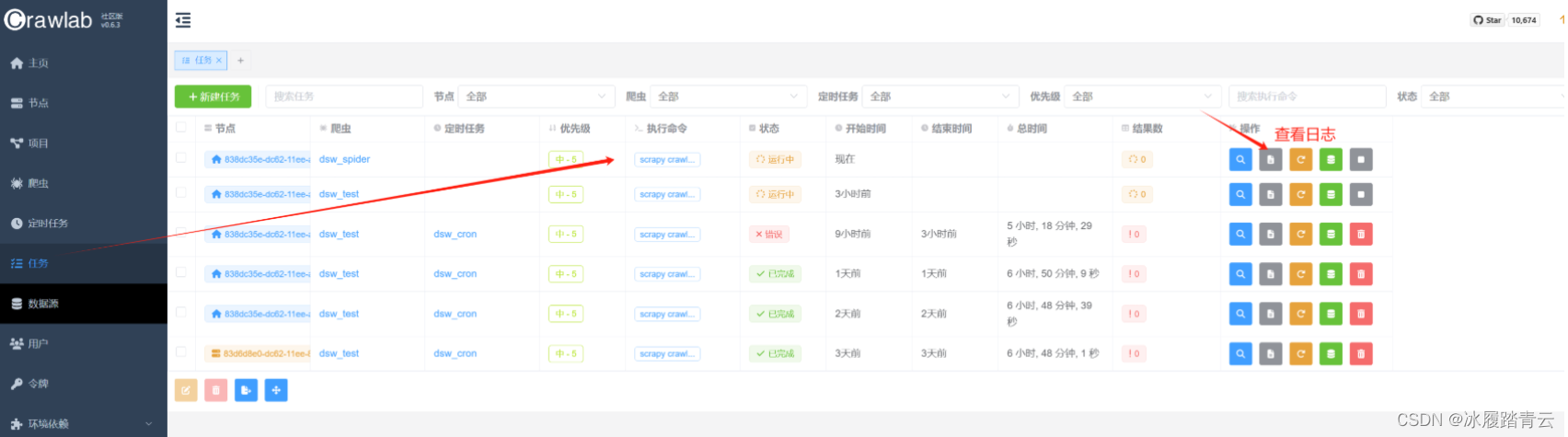
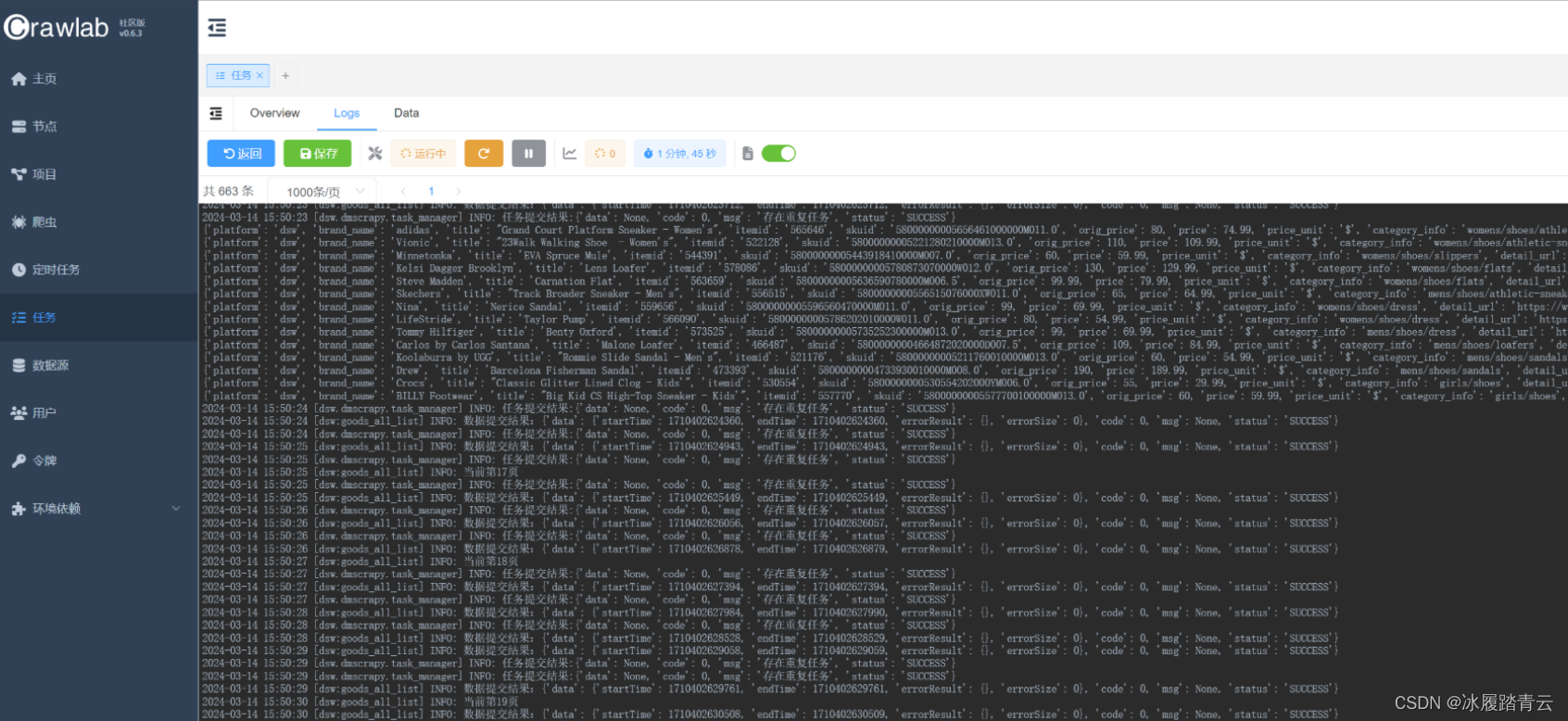
查看爬虫日志:
5. 线上代码修改
在爬虫里点搜索按钮查看 ,即进入以下界面:
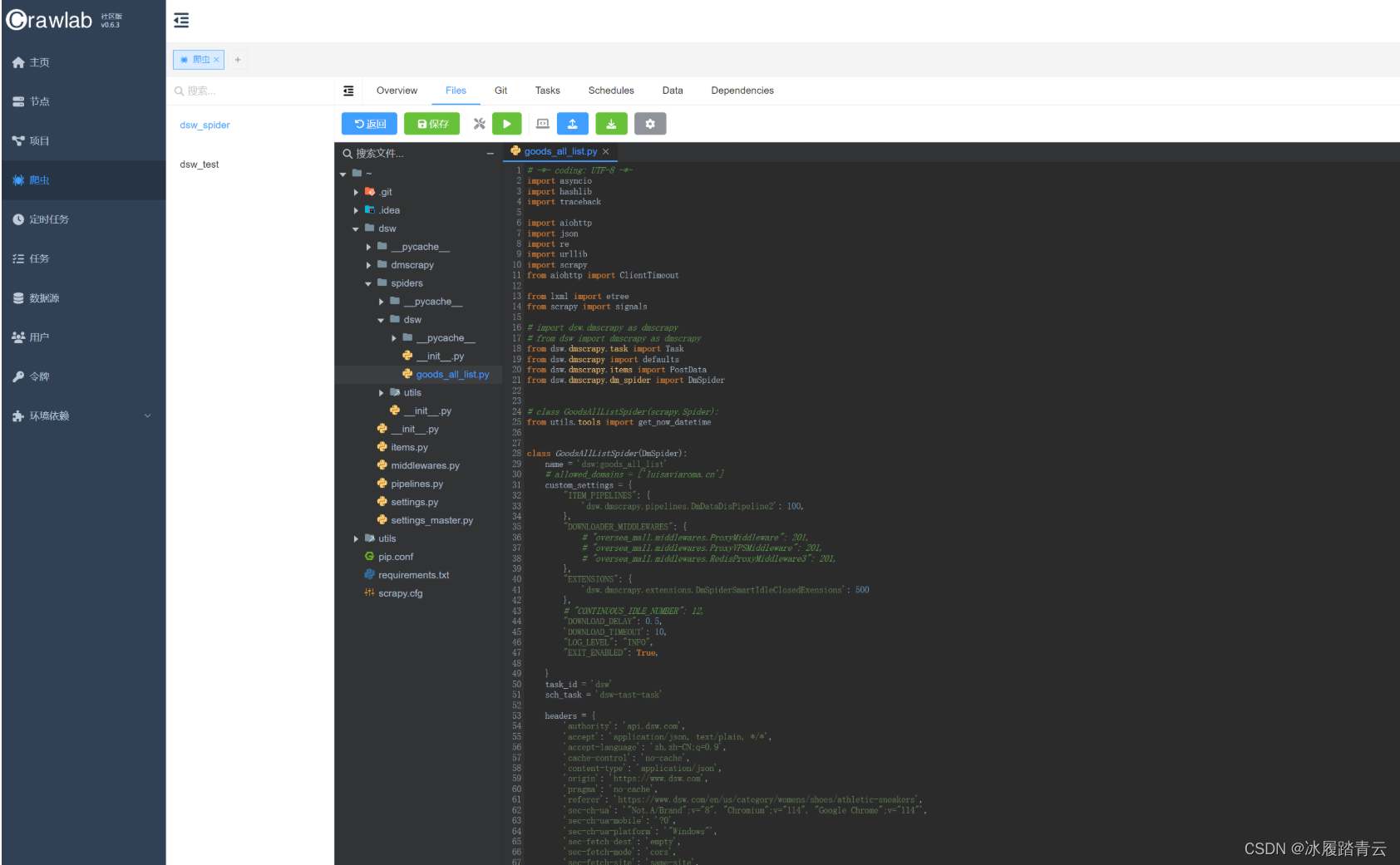
在爬虫的Files里也可以直接修改线上代码,crtl + s保存即生效,然后再重新运行程序即可。
6. 添加定时任务
点击定时任务,然后点击新建定时任务:
进入以下界面:
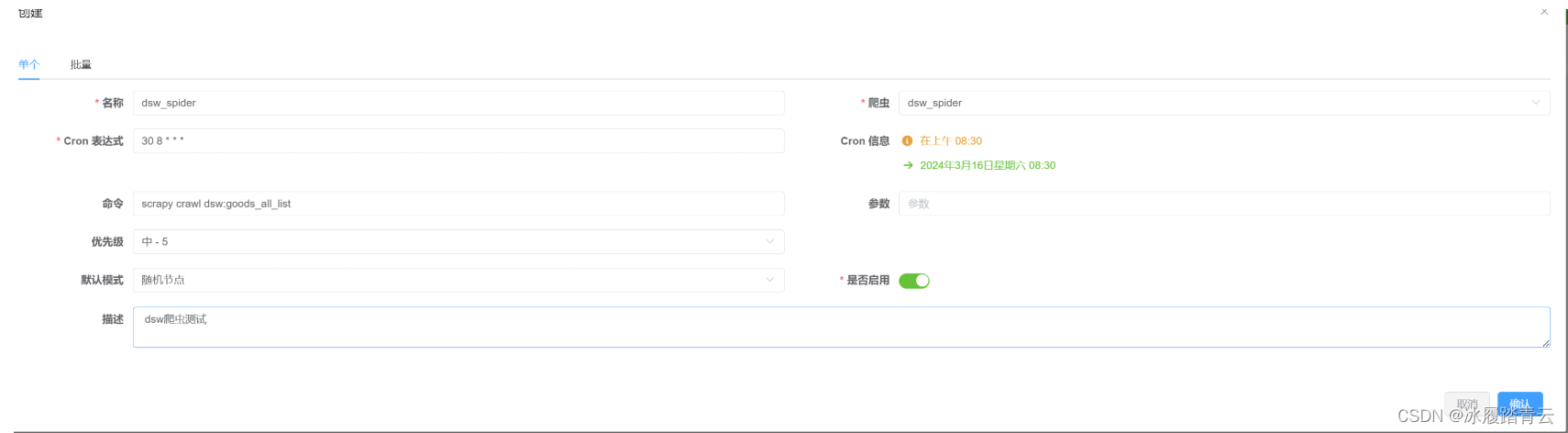
名称自定义,爬虫就点下拉框选择我们已经建好的爬虫,下面的scrapy命令也会自动索引补充,不用自己填;
Cron 表达式使用也简单,比如要创建一个 crontab 任务,要求每天早上 8:30 执行,你需要编辑 crontab 文件并添加以下行:
30 8 * * *
这里是如何解读这个 crontab 表达式的各个部分:
30表示分钟,指定在每小时的第 30 分钟。8表示小时,指定在上午 8 点。- 第三个星号
*表示日期,表示每个月的每一天。 - 第四个星号
*表示月份,表示每个月。 - 第五个星号
*表示星期几,表示每个星期的每一天。
然后点击确认即添加进定时任务。
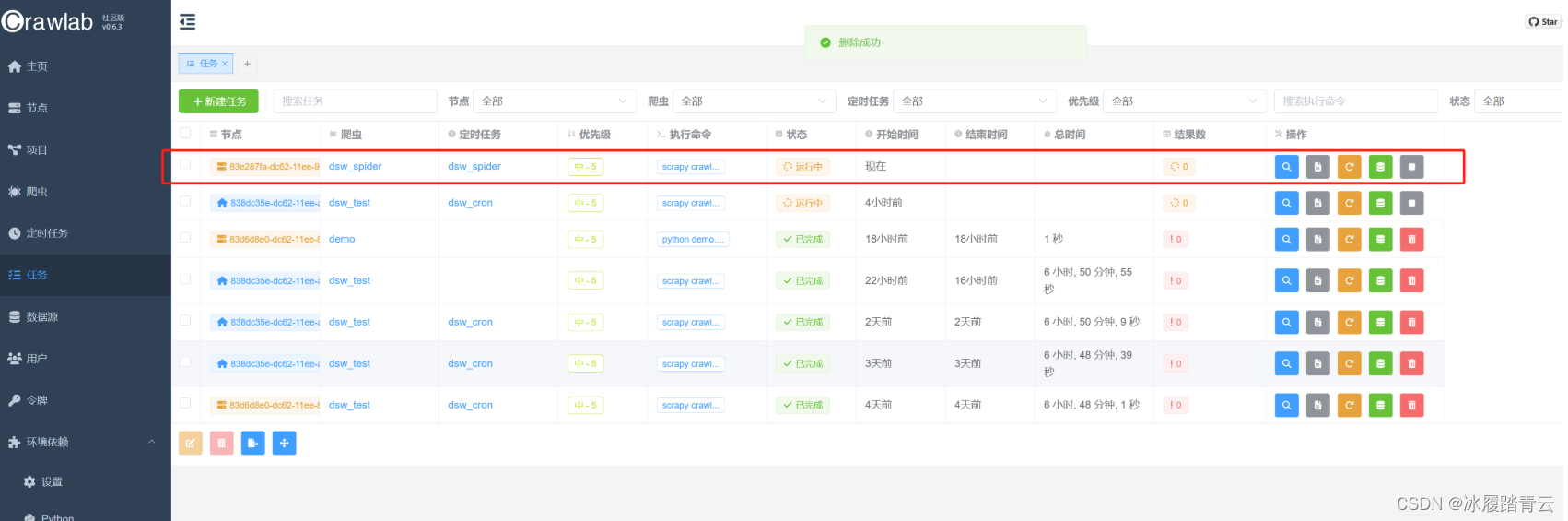
到时间点可以去任务里查看程序是否执行:
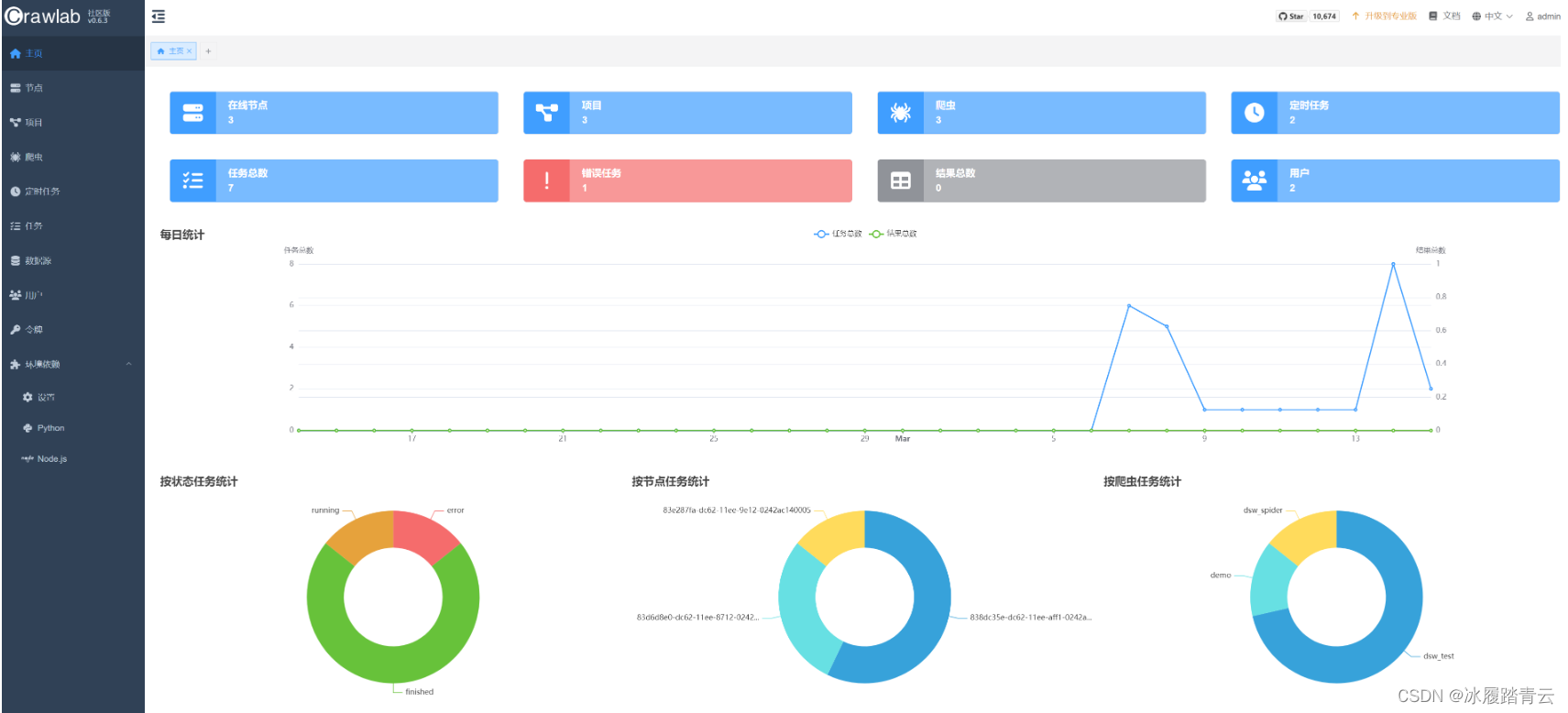
在主页里也可以查看任务执行统计情况:
定时任务取消只需要在定时任务里点击取消 启用按钮就行了: