import re
import requests
url= "http://www.yy8844.cn/ting/numes/sussoc.shtml"
response = requests.get(url)
response.encoding = "gbk"
# print(r.text)
#第一步,访问网页获取MusicID
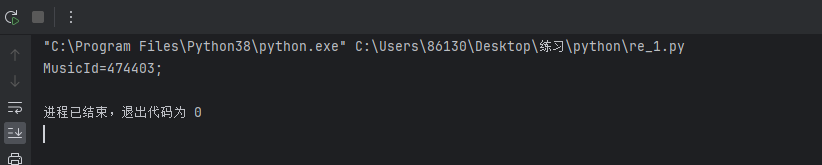
p = re.compile(r"MusicId=(.*?);",re.S)
print(re.search(p,response.text).group())运行得到如下,获取到MusicId
import re
import requests
import execjs
url= "http://www.yy8844.cn/ting/numes/sussoc.shtml"
response = requests.get(url)
response.encoding = "gbk"
# print(r.text)
#第一步,访问网页获取MusicID
p = re.compile(r"MusicId=(.*?);",re.S)
music_id = re.search(p,response.text).group(1)
#第二步 nodejs生成mp3 url
with open('m.js',encoding='utf-8') as f:
ctx = execjs.compile(f.read())
t = ctx.call("info", music_id)
print(t)
#第三步 访问mp3 url,下载MP3并保存function info(MusicId){
var surl = "http://96.ierge.cn/";
nurl = parseInt(MusicId / 30000) + "/" + parseInt(MusicId / 2000) + "/" + MusicId + ".mp3";
fin_url = surl + nurl
return fin_url
}
import re
import execjs
import requests
from bs4 import BeautifulSoup as bs
def download_mp3(url,name):
response = requests.get("http://www.yy8844.cn/"+url)
response.encoding = "gbk"
# print(r.text)
# 第一步,访问网页获取MusicID
p = re.compile(r"MusicId=(.*?);", re.S)
music_id = re.search(p, response.text).group(1)
# 第二步 nodejs生成mp3 url
with open('m.js', encoding='utf-8') as f:
ctx = execjs.compile(f.read())
url = ctx.call("info", music_id)
# 第三步 访问mp3 url,下载MP3并保存
mp3_content = requests.get(url)
with open(name+".mp3", "wb") as w:
w.write(mp3_content.content) # 获取文件(文件是二进制格式)并写入文件里
def get_index():
url = "http://www.yy8844.cn/"
headers = {
"User-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/119.0"
}
r = requests.get(url, headers=headers)
r.encoding = "gbk"
fin_result = re.findall(r'<a href="(.*?)" target=\'musiclisten\'>(.*?)</a>', r.text)
for i in fin_result:
download_mp3(i[0],i[1])
print("正在下载{}".format(i[1]))
print("下载完成")
if __name__ == '__main__':
get_index()
# soup = bs(r.text,'html.parser')
# print(soup.find_all(Class='link2'))