最好的学习方法在于实践,学习编程语言Python,也是同样的道理。本文讲解自己开发的一个项目,实现爬取妹子图片,所用的Python知识点以及模块,可以关注参考作者公众号的Python语言合集。
—、前情介绍
1.1 涉及模块
本项目的实现涉及模块有,
requestsBeautifulSoupostimeloggingre
1.2 网站信息以及项目代码地址
爬取图片所在网站地址:https://www.xrmn03.cc/
项目完整代码所在gitee:https://gitee.com/shawn_chen_rtz/meizi_pic.git
欢迎关注,STAR
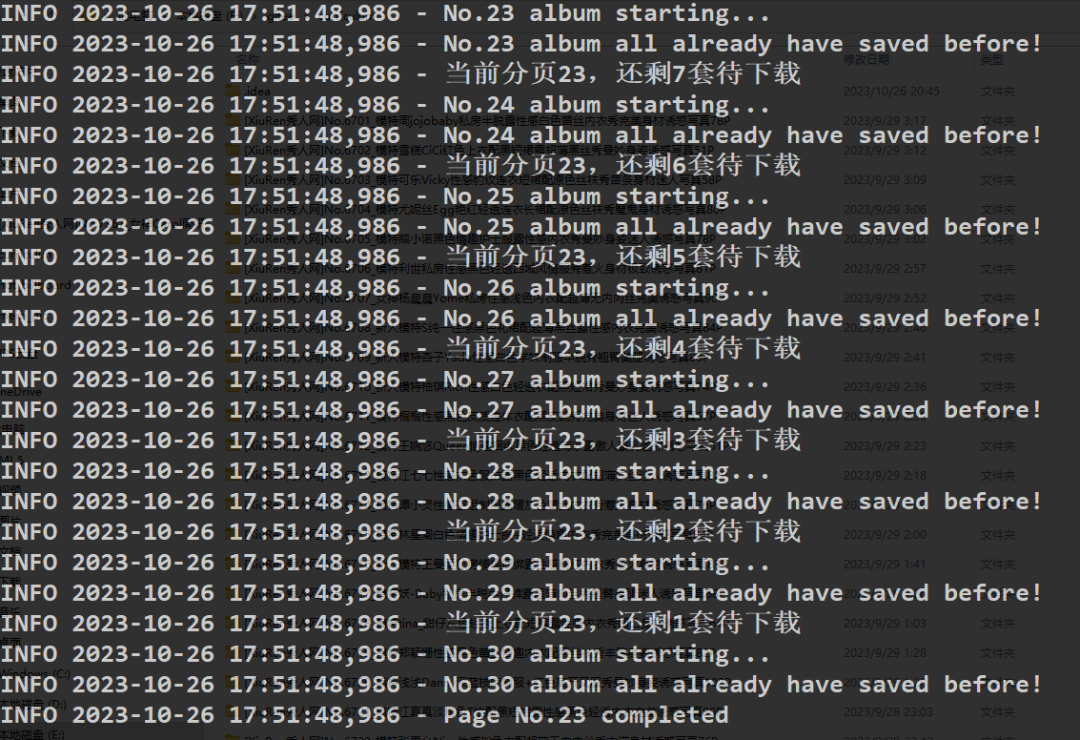
1.3 执行效果
执行后生成的文件夹效果,

日志信息,可以查看当前执行下载情况,
二、单张图片保存方法
2.1 在线图片保存方法
python">def save_pic(direct, pic_src, pic_no):
"""保存单个图片,根据目录direct,图片地址pic_src,图片保存名称pic_no."""
pic_url = "https://www.xrmn03.cc" + pic_src.attrs['src']
if not os.path.exists(direct + "/" + str(pic_no) + ".jpg"):
for _ in range(20):
try:
pic_binary = requests.get(url=pic_url).content
with open(direct + "/" + str(pic_no) + ".jpg", "wb") as img:
img.write(pic_binary)
except Exception:
time.sleep(60)
else:
break以上是保存图片方法save_pic(),它接收三个参数direct, pic_src, pic_no,分别表示欲存储的目录、图片链接和图片编号(用作命名图片文件)。
首先拼接成图片完整链接pic_url,再判断图片是否已存在路径中,如果不存在,开始执行保存操作,通过requests模块发出请求,读取图片数据pic_binary = requests.get(url=pic_url).content,通过文件写操作写入到本地路径下,文件操作可以参考个人公众号(欢迎关注)文章Python:文本文件的读、写处理。在请求过程中,可能基于网络等原因,报错异常,所以放在了一个循环体中,并在循环体中用try...except...else异常处理机制handle错误。如果出错,会等待60秒后继续请求,一共20次重试机会,也就是循环次数range(20);如果成功,则会直接跳出后续循环请求。异常处理机制可以参考个人公众号文章Python:异常处理。
三、获取整套图方法
3.1 获取整套图方法
思路:观察该网站的图集展示逻辑,一套图集中是以多个分页组成的。



可以观察到每个分页链接的组成是有一定规律的,根据规律获取单套图集每个分页的链接后,循环请求分页链接,在循环体中增加从每个分页的响应结果中爬取出包含图片的超链接功能,结合第二章的save_pic()方法,把图片保存到本地。
代码实现,
python">def get_full_album(album_address, title):
"""获取整个图集的图片,根据图集地址album_address和图集名称title"""
if not os.path.exists(title):
os.mkdir(title)
# 图集中的第i张图片
i = 1
for album_page in range(100):
album_page_url = (
"https://www.xrmn03.cc/" + album_address) if album_page == 0 else "https://www.xrmn03.cc/" + album_address.rstrip(
".html") + "_" + str(album_page) + ".html"
for _ in range(20):
try:
pics_page = requests.get(url=album_page_url)
except requests.exceptions.ChunkedEncodingError as err:
logger.error(f"occur {err}")
time.sleep(60)
except requests.exceptions.ConnectionError as err:
logger.error(f"{current_time()} occur {err}")
time.sleep(60)
else:
pics_page.encoding = "utf-8"
pics_soup = BeautifulSoup(pics_page.text, 'html.parser')
# 如果页面中不存在class_="content",图集下载完成。
if not pics_soup.findAll(class_="content"):
logger.info("{album} all downloaded".format(album=title))
return
pics = pics_soup.findAll(class_="content")[0]
pics = pics.findAll('img')
if pics:
for pic in pics:
save_pic(title, pic, i)
i = i + 1
break可以看到获取整套图方法get_full_album(album_address, title)接收两个参数,分别表示图集地址album_address和图集名称title。
首先,判断路径下是否已存在与图集名称同名的文件夹,如果不存在,通过os.mkdir(title)进行创建。循环遍历for album_page in range(100),album_page表示图集中的分页,获取每个分页的超链接,
python">album_page_url = (
"https://www.xrmn03.cc/" + album_address) if album_page == 0 else "https://www.xrmn03.cc/" + album_address.rstrip(
".html") + "_" + str(album_page) + ".html"用的格式是if分支语句的缩略写法。比如举个例子,大于0的数字是正数,相反则是非正数。正常写法是,
python">if a > 0:
print("Positive NO.")
else:
print("Not Positive NO.")简写格式则是,两种形式是等效的。
print("Positive NO.") if a > 0 else print("Not Positive NO.")循环请求分页地址,循环体内请求分页链接,根据访问详情结果,用BeautifulSoup提取出所有的图片链接,循环图片数据,调用save_pic(title, pic, i)方法,下载至本地保存。
当然同保存图片方法一样,也使用了异常处理机制,增强代码运行的健壮性与稳定性。如果发生异常错误时,用for循环的方式增加重试/重新请求的机制。
四、遍历获取图集地址/名称
4.1 遍历图集
代码实现,
python">for page in range(1, 24):
url = "https://www.xrmn03.cc/XiuRen/" if page == 1 else "https://www.xrmn03.cc/XiuRen/index" + str(page) + ".html"
resp = requests.get(url=url)
resp.encoding = "utf-8"
html = resp.text
soup = BeautifulSoup(html, 'html.parser')
albums = soup.findAll(class_="i_list list_n2")
logger.info("Page No.{page} starting...".format(page=page))
# 当前分页的第album_no图集
album_no = 1
for album in albums:
album_url = album.find('a').attrs['href']
album_title = album.find('a').attrs['title']
logger.info("No.{no} album starting...".format(no=album_no))
# 以下条件语句判断图集文件中的照片数量和图集名称中提取出的数量是否一致。如果一致则跳过该次循环。
if os.path.exists(album_title):
num_from_title = re.search(r'\d{2,3}P', album_title).group().strip("P")
# print(num_from_title)
if len(os.listdir("./" + album_title)) == int(num_from_title):
logger.info("No.{no} album all already have saved before!".format(no=album_no))
album_left = 30 - album_no
if album_left > 0:
logger.info(f"当前分页{page},还剩{album_left}套待下载")
album_no += 1
continue
get_full_album(album_url, album_title)
logger.info("No.{no} album all saved!".format(no=album_no))
album_left = 30 - album_no
if album_left > 0:
logger.info(f"当前分页{page},还剩{album_left}套图集待下载")
album_no += 1
logger.info("Page No.{page} completed".format(page=page))遍历图集分页,获取图集的链接,
根据图集分页链接组成规律,获取链接,for循环for page in range(1, 24)控制下载的页数范围,当前是下载1到23页的所有图集的图集信息。
获取所有albums,循环albums,处理得到图集链接album_url,图集名称album_title,如果已存在同名文件夹,并且文件夹中的图片数量与图集名称中的图片数量一致时,略过该图集,并写入对应日志信息。如果不存在同名文件夹,或者文件夹中的图片数量与文件夹名称中的数量不一致,则调用第三章中的get_full_album(album_url, album_title)方法。
ok,到这里结束了,有任何问题请留言或关注作者公众号,与我交流~
可以关注作者微信公众号,追踪更多有价值的内容!