本篇文章要做的是:将之前做的使用Scrapy中Crawl模板爬取纵横小说的项目改编为使用Scrapy_redis的项目!!!
目录:
每篇前言:
🏆🏆作者介绍:【孤寒者】—CSDN全栈领域优质创作者、HDZ核心组成员、华为云享专家Python全栈领域博主、CSDN原力计划作者
- 🔥🔥本文已收录于Scrapy框架从入门到实战专栏:《Scrapy框架从入门到实战》
- 🔥🔥热门专栏推荐:《Python全栈系列教程》、《爬虫从入门到精通系列教程》、《爬虫进阶+实战系列教程》、《Scrapy框架从入门到实战》、《Flask框架从入门到实战》、《Django框架从入门到实战》、《Tornado框架从入门到实战》、《前端系列教程》。
- 📝📝本专栏面向广大程序猿,为的是大家都做到Python全栈技术从入门到精通,穿插有很多实战优化点。
- 🎉🎉订阅专栏后可私聊进一千多人Python全栈交流群(手把手教学,问题解答); 进群可领取Python全栈教程视频 + 多得数不过来的计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!
scrapy_redis_13">1.首先,将之前的项目改为单个的使用scrapy_redis的分布式爬虫项目。
- (如果运行OK,再直接复制一个进行少量更改即可实现分布式!)
第一步:settings.py进行如下配置!
python"># 日志写入.log文件,方便观察终端!
LOG_FILE="zh.log"
LOG_ENABLED=False
# 第一步:加入以下代码:
#设置scrapy-redis
#1.启用调度将请求存储进redis
from scrapy_redis.scheduler import Scheduler
SCHEDULER="scrapy_redis.scheduler.Scheduler"
#2.确保所有spider通过redis共享相同的重复过滤
from scrapy_redis.dupefilter import RFPDupeFilter
DUPEFILTER_CLASS="scrapy_redis.dupefilter.RFPDupeFilter"
#3.指定连接到Redis时要使用的主机和端口 目的是连接上redis数据库
REDIS_HOST="localhost"
REDIS_PORT=6379
# 不清理redis队列,允许暂停/恢复抓取 (可选) 允许暂停,redis数据不丢失 可以实现断点续爬!!!
SCHEDULER_PERSIST = True
# 第二步:开启将数据存储进redis公共区域的管道!
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# 开启保存Mysql数据库的管道
'zongheng.pipelines.ZonghengPipeline': 300,
# 开启保存数据至redis公共区域的数据库
'scrapy_redis.pipelines.RedisPipeline': 100,
}
第二步:爬虫文件中进行如下修改!

最后,运行观察!
-
首先,命令运行项目,发现项目在等待。
-
然后,向redis数据库中放入第一个起始URL,命令为:
lpush zh:start_urls http://book.zongheng.com/store/c0/c0/b0/u1/p1/v0/s1/t0/u0/i1/ALL.html -
项目正常运行!可以通过Redis Desktop Manager工具观察到redis数据库中的URL数据等。

-
运行结束后,通过Navicat工具观察到Mysql数据库中小说信息爬取正常!


小拓展:如何使用Navicat工具清空Mysql数据库中数据表里的数据!
使用truncate命令的原因是:删除速度快;而且如果再次对同一张表中写入数据,自增长key会从初始值开始!

scrapyredis_76">2.然后,将项目改为完整的scrapy-redis分布式爬虫项目
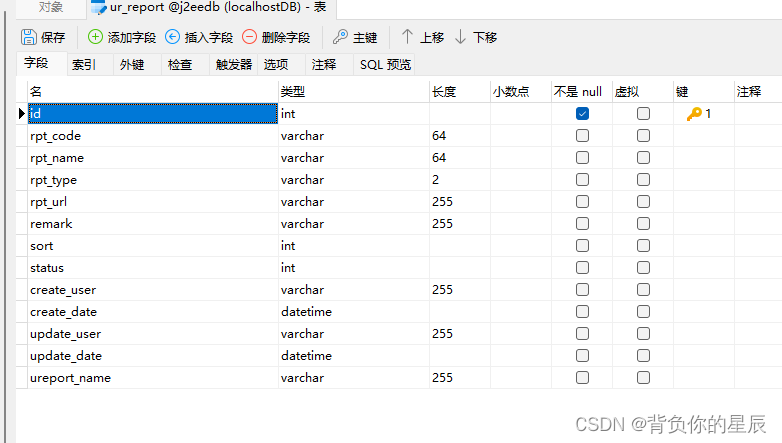
- 将此项目(称为项目一)再复制一个(称为项目二),并且为了便于观察,项目一的数据存入chapter和novel表中;项目二中的数据存入novel_copy和chapter表中。实质上两表结构一模一样!
因为项目二存入的表名更改了,所以要更改pipelines.py文件中的mysql语句中的表名(将所有的表名novel改为novel_copy;所有的chapter改为chapter_copy)!
-
但是,我们运行此分布式项目后,通过Navicat观察Mysql数据库中的数据时会发现——novel和novel_copy表中数据相加刚好为目标本数;但是,chapter和chapter_copy表会出现一个问题,比如:chapter_copy表中小说章节信息都有,然后有四章章节有具体章节内容,但是我们爬虫文件中限制的是六章章节有具体章节内容,理应chapter表中有另外两章章节的具体内容,但是观察会发现chapter表中是空的!!!
-
分析:

-
回想——我们之前向Mysql数据库中存入小说章节信息的思路是:先存入小说所有章节的信息(但不包括章节具体章节内容信息),注意是一次存入所有章节信息;然后:

-
存入章节具体章节信息的思路是:对应小说的章节URL(chapter_url)进行存储。即:先查询到表中有这个chapter_url,才会update其对应的章节具体章节内容!
-
但是小说所有章节信息是一次性插入,即会出现一张表有一张表没有的现象!所以,会出现上述问题!!!(但是实质上,我们实现了分布式,缺具体章节内容的其实被另一个项目处理了,只是没能存储进数据库!)
- 那么,如何获取完整的数据呢?我们可以想到,在settings.py中开启了将所有数据都放入redis数据库中公共区域的管道!但是,redis是个内存数据库,数据不能持久化,这里就想到了将redis数据库中的数据搬运到Mysql数据库中,即可!!!
①首先,从Redsi中取出数据试试可不可以:
创建一个.py脚本文件即可:
python">import redis
import pymysql
import json
#指定redis数据库信息
rediscli=redis.StrictRedis(host="localhost",port=6379,db=0)
#指定mysql数据库
mysqlconn=pymysql.connect(host="localhost",port=3306,user="root",password="123456",db="",charset="utf8")
#取出数据
source, data = rediscli.blpop(["bh3:items"]) # 数据是字节码格式
print(source, data)
item = json.loads(data)
print(item)
打印观察数据:

②从Redsi中取出数据完全OK,接下来就进行存储进Mysql数据库的操作!(注意:Redis这个公共区域空间存储了框架运行过程中爬取的所有数据,所以进行Mysql存储操作时要进行判断,所取出的那一条数据属于什么数据,是小说信息;章节信息还是章节具体内容信息)
python">import datetime
import redis
import pymysql
import json
#指定redis数据库信息
rediscli=redis.StrictRedis(host="localhost",port=6379,db=0)
#指定mysql数据库
mysqlconn=pymysql.connect(host="localhost",port=3306,user="root",password="123456",db="spider39",charset="utf8")
while True:
#取出数据
source, data = rediscli.blpop(["bh3:items"]) # 数据是字节码格式
# print(source, data)
item = json.loads(data)
# print(item)
#写入数据
cursor=mysqlconn.cursor()
if b"book_name" in data:
sql = "select id from novel_from_redis where book_name=%s and author=%s"
cursor.execute(sql, (item["book_name"], item["author"]))
if not cursor.fetchone():
#写入小说数据
sql="insert into novel_from_redis(category,book_name,author,status,book_nums,description,c_time,book_url,catalog_url)" \
"values (%s,%s,%s,%s,%s,%s,%s,%s,%s)"
cursor.execute(sql,(
item["category"],
item["book_name"],
item["author"],
item["status"],
item["book_nums"],
item["description"],
item["c_time"],
item["book_url"],
item["catalog_url"],
))
mysqlconn.commit()
cursor.close()
elif b"chapter_list" in data:
sql = "insert into chapter_from_redis(title,ordernum,c_time,chapter_url,catalog_url) values(%s,%s,%s,%s,%s)"
data_list = [] # [(%s,%s,%s,%s,%s),(%s,%s,%s,%s,%s),(%s,%s,%s,%s,%s)]
for index, chapter in enumerate(item["chapter_list"]):
title = chapter[0]
ordernum = index + 1
c_time = chapter[2]
chapter_url = chapter[3]
catalog_url = chapter[4]
data_list.append((title, ordernum, c_time, chapter_url, catalog_url))
cursor.executemany(sql, data_list)
mysqlconn.commit()
cursor.close()
elif b"content" in data:
sql = "update chapter_from_redis set content=%s where chapter_url=%s"
content = item["content"]
chapter_url = item["chapter_url"]
cursor.execute(sql, (content, chapter_url))
mysqlconn.commit()
cursor.close()
运行此.py脚本文件即可发现Mysql数据库中数据完整!!!
项目完整代码:
链接:https://pan.baidu.com/s/16-Zx5PGERxg2SgRGKStxvA
提取码:j5qh