用到的网页--豆瓣电影Top250
需要爬取信息:
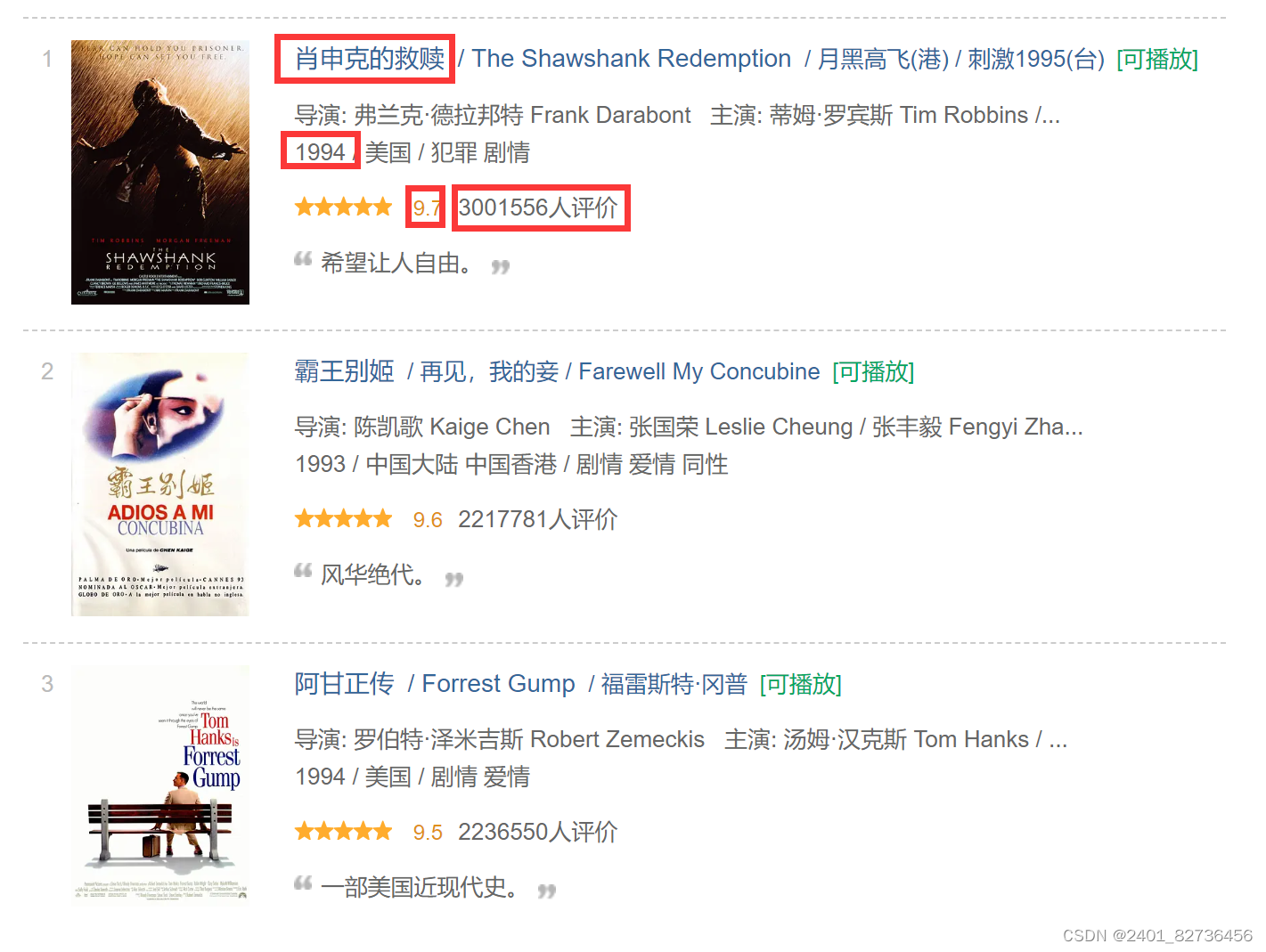
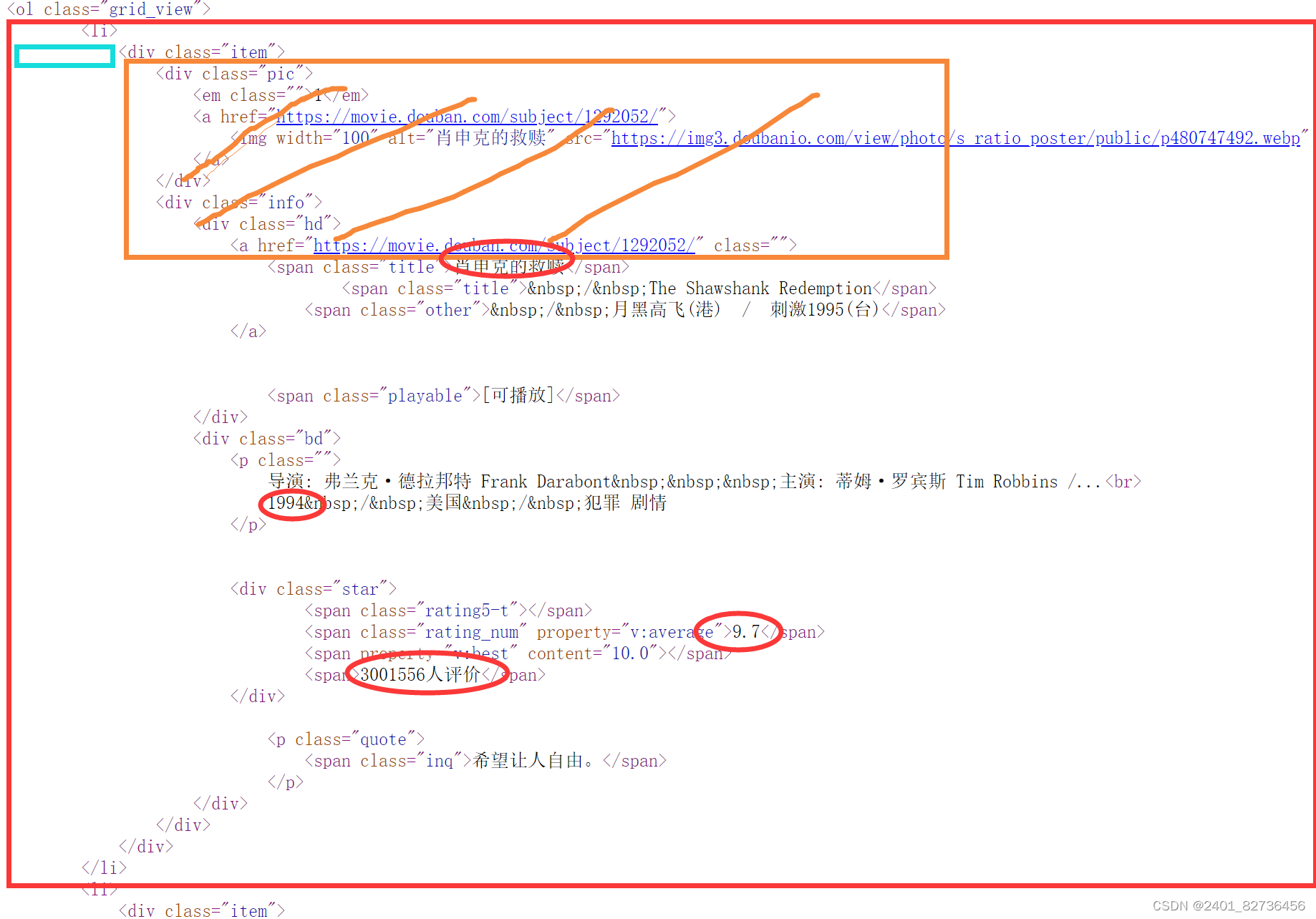
数据保存在网页源代码中,是服务加载方式。先拿到网页源代码--request。再通过re提取想要的信息---re。
新知识:用csv存数据,可以用excel表格展示数据
python">import csv
result = obj.finditer(page_content)
f = open("data.csv",mode="w")
csvwriter = csv.writer(f)
for it in result:
dic = it.groupdict()#把数据全都扔到字典里
dic['year'] = dic['year'].strip()
csvwriter.writerow(dic.values())
f.close()
resp.close()
print("over!")注意:在pycharm里要对文件用utf-8重新编码,如果要用excel显示时要换回ansi编码,两者颠倒会乱码。


代码:
python">import requests
import re
import csv
#将数据存储,存储时以逗号为分割
#肖申克的救赎,1994,9.7,3001556人评价
url = "https://movie.douban.com/top250"
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
resp = requests.get(url,headers = headers)
#拿到网页源代码
#print(resp.text)
page_content = resp.text
#解析数据,写正则表达式
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?'
r'<p class="">.*?<br>(?P<year>.*?) .*?<span class="rating_num" property="v:average">'
r'(?P<grade>.*?)</span>'
r'.*?<span>(?P<conment>.*?)</span>',re.S)
result = obj.finditer(page_content)
f = open("data.csv",mode="w")
csvwriter = csv.writer(f)
for it in result:
# print(it.group("name"),end=" ")
# print(it.group("year").strip(),end=" ")
# print(it.group("grade"),end=" ")
# print(it.group("conment"))
#将数据整理成字典的格式
dic = it.groupdict()#把数据全都扔到字典里
dic['year'] = dic['year'].strip()
csvwriter.writerow(dic.values())
f.close()
resp.close()
print("over!")
可以看到每一页的榜单链接只有一个参数改变,爬取信息时可以只改参数。