文章目录
- 一、前言
- 二、导库部分:
- 三、预定义请求参数部分:
- 四、“起点小说”网站
- 发起请求并解析得到的HTML:
- 获取所有章节和链接:
- 保存得到的章节内容:
- 五、“起点小说”网站完整版脚本
- 六、“笔趣阁”网站
- 预定义参数部分:
- 主程序部分:
- 保存得到的章节内容:
- 七、“笔趣阁”网站完整版脚本
一、前言
欢迎阅读本篇博客,在这里,我们将探索如何使用Python进行网站数据抓取。数据抓取,或称为网页爬虫,是一种从网站上自动提取信息的技术。在现代数据驱动的世界中,这一技巧尤其宝贵。不论是为了个人学习,研究目的,还是企业收集行业数据,掌握如何从网络中提取有价值的数据无疑都是一个重要的技能。、
在这篇博客的接下来几个部分中,我将向您展示如何使用Python中的一些库来获取网站数据。我们将以实际案例“起点小说”和“笔趣阁”网站为例,一步步通过代码详细说明这一过程。由于我们必须尊重网站的服务负载,time库能够帮助我们在请求间增加适当的延时,避免因为请求过于频繁而触发网站的防爬措施。
在下文的代码示范中,我们将实践如何使用这些库,并详细讲解每一行代码对应的功能和背后的逻辑。
二、导库部分:
使用了三个Python库,分别是requests,BeautifulSoup和time。其中,requests用于发出http请求,BeautifulSoup用于解析HTML网页,time用于控制请求频率。
#导库
import requests
from bs4 import BeautifulSoup
import time
三、预定义请求参数部分:
定义了目标URL和请求头headers。URL是待抓取的小说目录页面地址,headers中包含了User-Agent等键值对,这些信息用于模拟正常的浏览器行为,防止服务端识别到此次请求是爬虫程序发出的。
#请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',
'Accept-Encoding': 'gzip, deflate, br',
'DNT': "1",
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Cookie':'_csrfToken=VNpSGeOeI4x9OxUNY7BeYEbL12i4sRAy0H3BYg15; newstatisticUUID=1710636870_1641355660; fu=191679000; traffic_utm_referer=https%3A//cn.bing.com/; supportwebp=true; w_tsfp=ltvgWVEE2utBvS0Q6Krvl02mETg7Z2R7xFw0D+M9Os09AKUiWpaE04F8utfldCyCt5Mxutrd9MVxYnGBUNUtdRAXQsmZb5tH1VPHx8NlntdKRQJtA5LUW1FKduhwuDBPKmxbcUDk32coIdZJyb1n2wgFunYn37ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgW2DugDuLi11A7lK1EOW1i8cG3pV8w2pJbsDal7wcpK9Uv8wrTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZUqukO18Lv3wdaN4qzsLVP1NGFhDqVwRs+o5/01LDXvsNn2KA/l7tlIGRPNbrcq+NA=='}
其中除’Cookie‘标签请求头以外的请求头较为常见不做过多讲述,直接用就好。Cookie请求头每个网站页面的都不同,出处如下:
1.找到想要爬取的网站,按F2打开开发者模式,以下用有较为复杂发爬取措施的“起点小说网站”作为示范,如果掌握了那么其他网站的操作也不再话下。
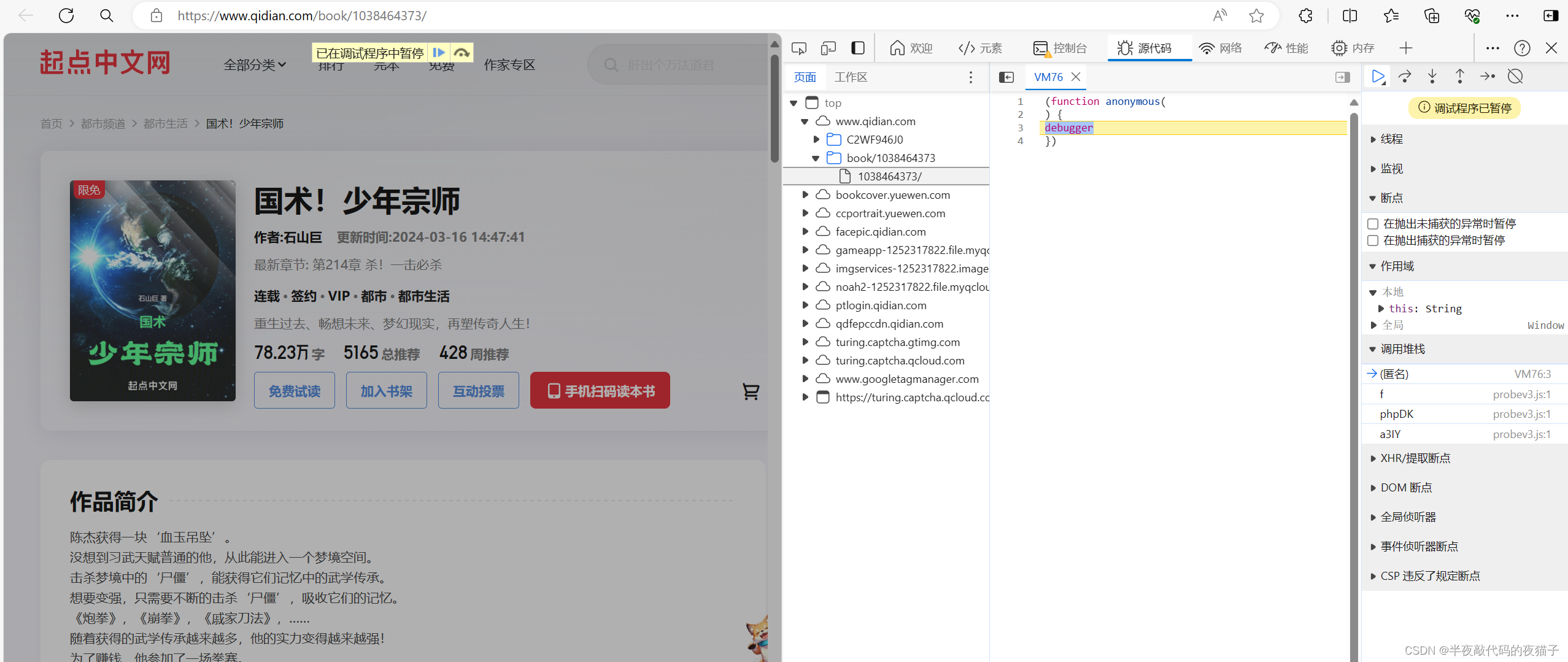
2.可以看到,因为反爬取措施,我们的开发者模式会一直卡在调试阶段无法获取资源。下面我们将利用断点操作导出正常界面。(按照如图操作,打开源代码,点击断电停用,点击恢复脚本执行)

3.操作完成后就可以开启开发者模式,接下来(按照如图操作,打开网络,点击清除网络日志,刷新,点击js文件)

4.就可以看到文件下的’Cookie‘标签拿到后复制#请求代码中就可以拥有访问权限

四、“起点小说”网站
发起请求并解析得到的HTML:
调用requests库的get方法发出GET请求,然后用BeautifulSoup解析接收到的HTML页面。
res = requests.get(url,headers=headers)
获取所有章节和链接:
从解析得到的HTML中找出所有class为’chapter-name’的a标签元素,因为这些a标签包含了章节的名称和链接。
对找出的每个a标签,使用[‘href’]获取其href属性值,即章节的相对链接。分割链接得到章节的id,然后构造新的URL作为具体章节页面的链接。
再次发起GET请求,获取具体章节的HTML页面,然后用BeautifulSoup进行解析。
在解析得到的HTML中找出所有p标签元素,这些p标签包含了这个章节的文本内容。
#处理数据
bs = BeautifulSoup(res.text,'html.parser')
#获取所有章节
bs_a = bs.find_all('a',class_='chapter-name')
# for i in range(len(bs_a)):
# print(bs_a[i].text)
#获取所有章节链接
for i in bs_a:
id = i['href'].split('/')[-2]
url2 = f"https://www.qidian.com/chapter/1038464373/{id}"+"/"
res2 = requests.get(url2, headers=headers)
bs2 = BeautifulSoup(res2.text, 'html.parser')
bs2_p = bs2.find_all('p')
time.sleep(1)
保存得到的章节内容:
用with语句打开一个新的txt文件,文件名等于章节的名字。然后遍历所有的p标签,将其中的文本内容写入到文件中,每个p标签的文本后都添加一个换行符。这一步完成后,就成功地把小说的一章保存到本地文件里了。
with open(f"{i.text}.txt", 'a', encoding='utf-8') as f:
for j in bs2_p:
f.write(j.text)
f.write('\n')
五、“起点小说”网站完整版脚本
整个脚本的基本流程是:先获取目录页,查找出所有章节的链接和名字,然后进入每个具体的章节页面,获取章节的文本内容,最后将内容保存到txt文件中。每处理完一章都暂停1秒,以免访问过快而被服务器封锁。
#起点小说网站
#导库
import requests
from bs4 import BeautifulSoup
import time
#寻址
url = "https://www.qidian.com/book/1038464373/"
#请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',
'Accept-Encoding': 'gzip, deflate, br',
'DNT': "1",
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
'Cookie':'_csrfToken=VNpSGeOeI4x9OxUNY7BeYEbL12i4sRAy0H3BYg15; newstatisticUUID=1710636870_1641355660; fu=191679000; traffic_utm_referer=https%3A//cn.bing.com/; supportwebp=true; w_tsfp=ltvgWVEE2utBvS0Q6Krvl02mETg7Z2R7xFw0D+M9Os09AKUiWpaE04F8utfldCyCt5Mxutrd9MVxYnGBUNUtdRAXQsmZb5tH1VPHx8NlntdKRQJtA5LUW1FKduhwuDBPKmxbcUDk32coIdZJyb1n2wgFunYn37ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgW2DugDuLi11A7lK1EOW1i8cG3pV8w2pJbsDal7wcpK9Uv8wrTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZUqukO18Lv3wdaN4qzsLVP1NGFhDqVwRs+o5/01LDXvsNn2KA/l7tlIGRPNbrcq+NA=='}
res = requests.get(url,headers=headers)
#处理数据
bs = BeautifulSoup(res.text,'html.parser')
#获取所有章节
bs_a = bs.find_all('a',class_='chapter-name')
# for i in range(len(bs_a)):
# print(bs_a[i].text)
#获取所有章节链接
for i in bs_a:
id = i['href'].split('/')[-2]
url2 = f"https://www.qidian.com/chapter/1038464373/{id}"+"/"
res2 = requests.get(url2, headers=headers)
bs2 = BeautifulSoup(res2.text, 'html.parser')
bs2_p = bs2.find_all('p')
time.sleep(1)
with open(f"{i.text}.txt", 'a', encoding='utf-8') as f:
for j in bs2_p:
f.write(j.text)
f.write('\n')
六、“笔趣阁”网站
这个Python脚本是用来抓取“笔趣阁”网站上的小说内容,并将内容保存到本地的txt文件中。以下是对每个部分的解析:
预定义参数部分:
定义了请求的headers和url。headers中的User-Agent字段用于模拟浏览器请求,防止服务器识别出非浏览器的访问并进行拦截。url是待抓取小说的目录页地址。
相比于”起点小说“没有反爬措施直接用
#请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',
'Accept-Encoding': 'gzip, deflate, br',
'DNT': "1",
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-User': '?1',
'Sec-Fetch-Dest': 'document',
}
或者只写第一行也行
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
主程序部分:
发起请求获取小说目录页内容,然后使用BeautifulSoup解析获取到的HTML内容。
使用select方法选取所有章节链接的html元素,并将返回的列表赋值给soup_html。
遍历soup_html,对每个元素,使用[“href”]获取其链接,使用.text获取其文本内容(即章节名)。如果链接包含"/book",说明是有效的章节链接。
定义新的URL为章节的完整链接,然后发起请求获取该章节的页面内容,并使用BeautifulSoup解析。
使用find_all方法获取章节页面中id为"chaptercontent"的元素,这个元素中包含了章节的文本内容。
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,"html.parser")
soup_html = soup.select("div.listmain dl dd a")#子元素选择,select返回的是列表
for html in soup_html:
href = html["href"] #获取href属性
name = html.text #获取文本信息
if "/book" in href:
new_url = f"https://www.bqg70.com{href}"
new_res = requests.get(url=new_url,headers=headers)
new_soup = BeautifulSoup(new_res.text,"html.parser")
div_id = new_soup.find_all("div",id = "chaptercontent")
保存得到的章节内容:
使用with语句打开一个文件,文件名为章节名,并打印正在下载的信息。然后使用write方法将章节内容写入到文件中。
with open(f"txt/{name}.txt",mode="a",encoding="utf-8") as f:
print(f"正在下载:《{name}》,请稍后~~~")
f.write(div_id[0].prettify().replace("<br>","").replace("<br/>","\n").replace('<div class="Readarea ReadAjax_content" id="chaptercontent">',""))#prettify()获取标签内html的代码
time.sleep(1)
#prettify()获取标签里的html信息,比text文本信息更全面
七、“笔趣阁”网站完整版脚本
整个脚本的主要任务是爬取“笔趣阁”网站上的小说内容,并将内容下载到本地的txt文件中。它以章节为单位,对每一个章节都创建一个对应的txt文件。在下载的过程中,还设置了提示信息和延时,使得脚本的运行更加人性化和安全。
#笔趣阁
#导库
import requests
from bs4 import BeautifulSoup
import time
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
url = "https://www.bqg70.com/book/72268/"
res = requests.get(url,headers=headers)
soup = BeautifulSoup(res.text,"html.parser")
soup_html = soup.select("div.listmain dl dd a")#子元素选择,select返回的是列表
for html in soup_html:
href = html["href"] #获取href属性
name = html.text #获取文本信息
if "/book" in href:
new_url = f"https://www.bqg70.com{href}"
new_res = requests.get(url=new_url,headers=headers)
new_soup = BeautifulSoup(new_res.text,"html.parser")
div_id = new_soup.find_all("div",id = "chaptercontent")
with open(f"txt/{name}.txt",mode="a",encoding="utf-8") as f:
print(f"正在下载:《{name}》,请稍后~~~")
f.write(div_id[0].prettify().replace("<br>","").replace("<br/>","\n").replace('<div class="Readarea ReadAjax_content" id="chaptercontent">',""))#prettify()获取标签内html的代码
time.sleep(1)
#prettify()获取标签里的html信息,比text文本信息更全面