参考链接:https://playwright.bootcss.com/python/docs/intro
目标网站:https://spa6.scrape.center/
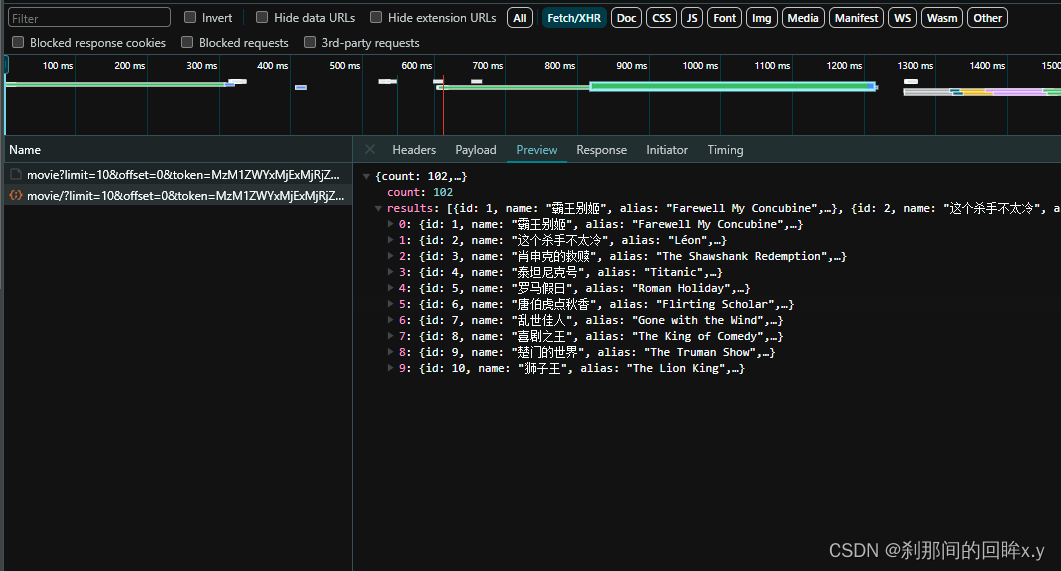
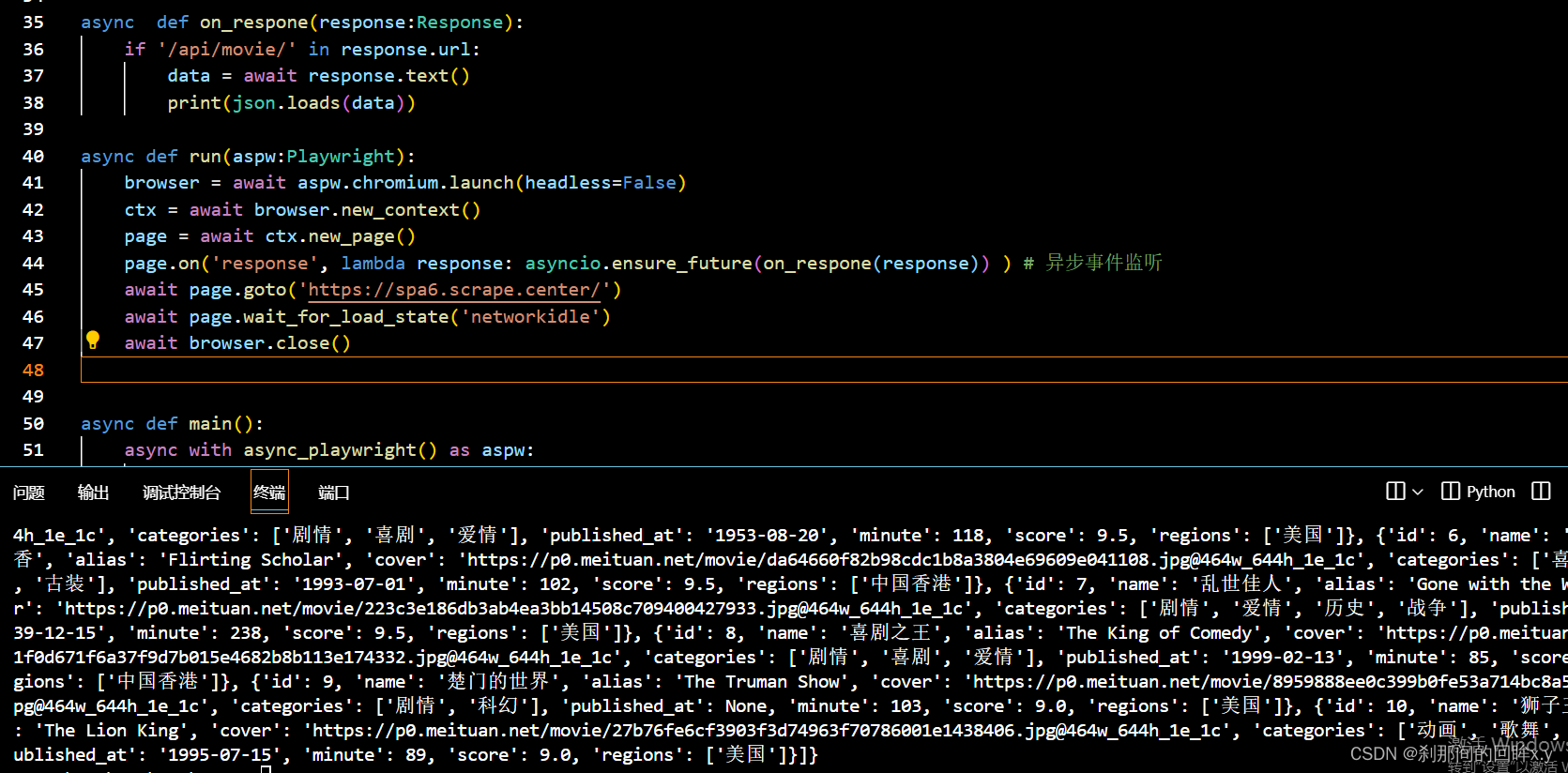
通过观察,页面的信息是通过Ajax请求后返回的信息
下面使用playwright实现绕过token的获取直接拿到返回的数据
import asyncio
import json
from playwright.async_api import async_playwright, Playwright, Response
async def on_respone(response:Response):
if '/api/movie/' in response.url:
data = await response.text()
print(json.loads(data))
async def run(aspw:Playwright):
browser = await aspw.chromium.launch(headless=False)
ctx = await browser.new_context()
page = await ctx.new_page()
page.on('response', lambda response: asyncio.ensure_future(on_respone(response)) )
await page.goto('https://spa6.scrape.center/')
await page.wait_for_load_state('networkidle')
await browser.close()
async def main():
async with async_playwright() as aspw:
await run(aspw)
asyncio.run(main())