官方文档
Sample Code:
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
# minutes=24 * 60:每隔一天重新爬取
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://scrapy.org/', callback=self.index_page)
# age:过期时间
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
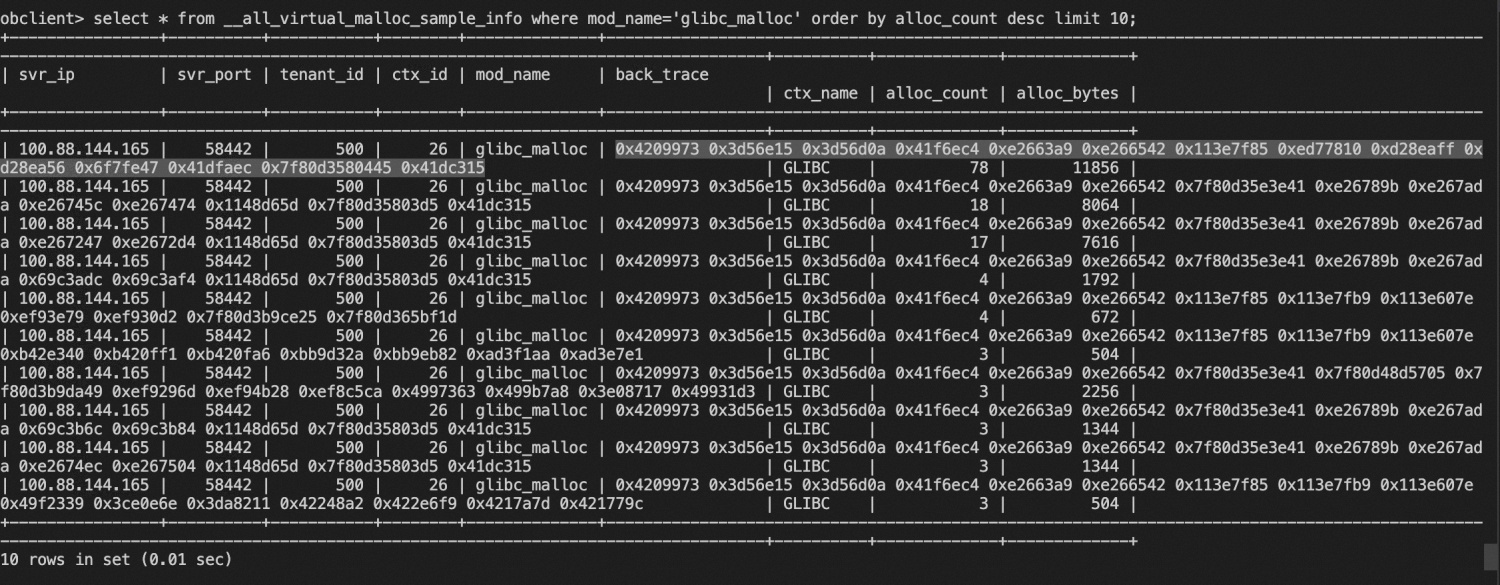
1 架构(Architecture)

scheduler:调度器
feter:请求器,请求网页
processor:用来处理数据,处理的url可以重新调用调度器
monitor&webui:监视器与webUI
scheduler
维护request队列,默认是存储在本地的数据库
feter

可以用两种模式:一种是直接请求,一种是js的请求。
processor
处理数据,将url重新封装起来,可以重新调用调度器。
2 Command Line
Global Config
global options work for all subcommands.
Usage: pyspider [OPTIONS] COMMAND [ARGS]...
A powerful spider system in python.
Options:
-c, --config FILENAME a json file with default values for subcommands.
{“webui”: {“port”:5001}}
--logging-config TEXT logging config file for built-in python logging
module [default: pyspider/pyspider/logging.conf]
--debug debug mode
--queue-maxsize INTEGER maxsize of queue
--taskdb TEXT database url for taskdb, default: sqlite
--projectdb TEXT database url for projectdb, default: sqlite
--resultdb TEXT database url for resultdb, default: sqlite
--message-queue TEXT connection url to message queue, default: builtin
multiprocessing.Queue
--amqp-url TEXT [deprecated] amqp url for rabbitmq. please use
--message-queue instead.
--beanstalk TEXT [deprecated] beanstalk config for beanstalk queue.
please use --message-queue instead.
--phantomjs-proxy TEXT phantomjs proxy ip:port
--data-path TEXT data dir path
--version Show the version and exit.
--help Show this message and exit.
config
pyspider启动的时候的一些配置选项
{
"taskdb": "mysql+taskdb://username:password@host:port/taskdb",
"projectdb": "mysql+projectdb://username:password@host:port/projectdb",
"resultdb": "mysql+resultdb://username:password@host:port/resultdb",
"message_queue": "amqp://username:password@host:port/%2F",
"webui": {
"username": "some_name",
"password": "some_passwd",
"need-auth": true
}
}
项目启动时,会生成上述3个db,在当前项目的data目录下
webui:指定好界面访问的用户名密码

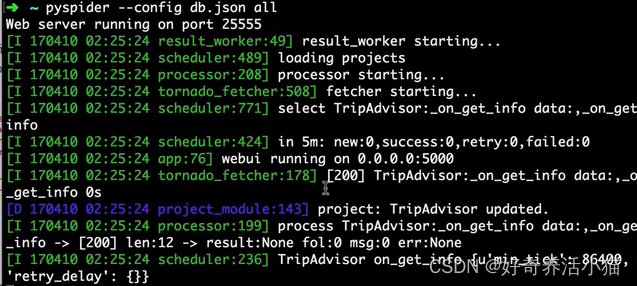
此时弹出:
all
运行所有的组件
Usage: pyspider all [OPTIONS]
Run all the components in subprocess or thread
Options:
--fetcher-num INTEGER instance num of fetcher
--processor-num INTEGER instance num of processor
--result-worker-num INTEGER instance num of result worker
--run-in [subprocess|thread] run each components in thread or subprocess.
always using thread for windows.
--help Show this message and exit.
one
在一个进程下运行所有的组件
Usage: pyspider one [OPTIONS] [SCRIPTS]...
One mode not only means all-in-one, it runs every thing in one process
over tornado.ioloop, for debug purpose
Options:
-i, --interactive enable interactive mode, you can choose crawl url.
--phantomjs enable phantomjs, will spawn a subprocess for phantomjs
--help Show this message and exit.
bench
请求测试
Usage: pyspider bench [OPTIONS]
Run Benchmark test. In bench mode, in-memory sqlite database is used
instead of on-disk sqlite database.
Options:
--fetcher-num INTEGER instance num of fetcher
--processor-num INTEGER instance num of processor
--result-worker-num INTEGER instance num of result worker
--run-in [subprocess|thread] run each components in thread or subprocess.
always using thread for windows.
--total INTEGER total url in test page
--show INTEGER show how many urls in a page
--help Show this message and exit.
已下组件都是单独开启
scheduler
Usage: pyspider scheduler [OPTIONS]
Run Scheduler, only one scheduler is allowed.
Options:
--xmlrpc / --no-xmlrpc
--xmlrpc-host TEXT
--xmlrpc-port INTEGER
--inqueue-limit INTEGER size limit of task queue for each project, tasks
will been ignored when overflow
--delete-time INTEGER delete time before marked as delete
--active-tasks INTEGER active log size
--loop-limit INTEGER maximum number of tasks due with in a loop
--scheduler-cls TEXT scheduler class to be used.
--help Show this message and exit.
phantomjs
Usage: run.py phantomjs [OPTIONS] [ARGS]...
Run phantomjs fetcher if phantomjs is installed.
Options:
--phantomjs-path TEXT phantomjs path
--port INTEGER phantomjs port
--auto-restart TEXT auto restart phantomjs if crashed
--help Show this message and exit.
fetcher
Usage: pyspider fetcher [OPTIONS]
Run Fetcher.
Options:
--xmlrpc / --no-xmlrpc
--xmlrpc-host TEXT
--xmlrpc-port INTEGER
--poolsize INTEGER max simultaneous fetches
--proxy TEXT proxy host:port
--user-agent TEXT user agent
--timeout TEXT default fetch timeout
--fetcher-cls TEXT Fetcher class to be used.
--help Show this message and exit.
processor
Usage: pyspider processor [OPTIONS]
Run Processor.
Options:
--processor-cls TEXT Processor class to be used.
--help Show this message and exit.
result_worker
Usage: pyspider result_worker [OPTIONS]
Run result worker.
Options:
--result-cls TEXT ResultWorker class to be used.
--help Show this message and exit.
webui
Usage: pyspider webui [OPTIONS]
Run WebUI
Options:
--host TEXT webui bind to host
--port INTEGER webui bind to host
--cdn TEXT js/css cdn server
--scheduler-rpc TEXT xmlrpc path of scheduler
--fetcher-rpc TEXT xmlrpc path of fetcher
--max-rate FLOAT max rate for each project
--max-burst FLOAT max burst for each project
--username TEXT username of lock -ed projects
--password TEXT password of lock -ed projects
--need-auth need username and password
--webui-instance TEXT webui Flask Application instance to be used.
--help Show this message and exit.

3 API Reference
self.crawl(url, **kwargs)
self.crawl is the main interface to tell pyspider which url(s) should be crawled.
发起请求的函数
Parameters:
url
the url or url list to be crawled.
请求的网页
callback
the method to parse the response. _default: call _
回调函数
def on_start(self):
self.crawl('http://scrapy.org/', callback=self.index_page)
the following parameters are optional
age
the period of validity of the task. The page would be regarded as not modified during the period. default: -1(never recrawl)
请求的过期时间,单位秒,过期了才重新请求
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
...
Every pages parsed by the callback index_page would be regarded not changed within 10 days. If you submit the task within 10 days since last crawled it would be discarded.
priority
the priority of task to be scheduled, higher the better. default: 0
指定爬取优先级.
def index_page(self):
self.crawl('http://www.example.org/page2.html', callback=self.index_page)
self.crawl('http://www.example.org/233.html', callback=self.detail_page,
priority=1)
The page 233.html would be crawled before page2.html. Use this parameter can do a BFS and reduce the number of tasks in queue(which may cost more memory resources).
exetime
the executed time of task in unix timestamp. default: 0(immediately)
指定执行时间
import time
def on_start(self):
self.crawl('http://www.example.org/', callback=self.callback,
exetime=time.time()+30*60)
The page would be crawled 30 minutes later.
retries
retry times while failed. default: 3
失败之后的重试次数,默认时3,最大10.
itag
a marker from frontier page to reveal the potential modification of the task. It will be compared to its last value, recrawl when it’s changed. default: None
标识符,
def index_page(self, response):
for item in response.doc('.item').items():
self.crawl(item.find('a').attr.url, callback=self.detail_page,
itag=item.find('.update-time').text())
In the sample, .update-time is used as itag. If it’s not changed, the request would be discarded.
如果没有改变,不进行重新爬取
Or you can use itag with Handler.crawl_config to specify the script version if you want to restart all of the tasks.
class Handler(BaseHandler):
crawl_config = {
'itag': 'v223'
}
Change the value of itag after you modified the script and click run button again. It doesn’t matter if not set before.
auto_recrawl
when enabled, task would be recrawled every age time. default: False
自动重爬,如果开启,age过期后自动重爬。
def on_start(self):
self.crawl('http://www.example.org/', callback=self.callback,
age=5*60*60, auto_recrawl=True)
The page would be restarted every age 5 hours.
method
HTTP method to use. default: GET
HTTP的请求方法。
params
dictionary of URL parameters to append to the URL.
get请求的一些参数.
def on_start(self):
self.crawl('http://httpbin.org/get', callback=self.callback,
params={'a': 123, 'b': 'c'})
self.crawl('http://httpbin.org/get?a=123&b=c', callback=self.callback)
The two requests are the same.
data
the body to attach to the request. If a dictionary is provided, form-encoding will take place.
post请求的一些data.
def on_start(self):
self.crawl('http://httpbin.org/post', callback=self.callback,
method='POST', data={'a': 123, 'b': 'c'})
files
dictionary of {field: {filename: ‘content’}} files to multipart upload.
上传的文件.
user_agent
the User-Agent of the request
headers
dictionary of headers to send.
cookies
dictionary of cookies to attach to this request.
connect_timeout
timeout for initial connection in seconds. default: 20
timeout
maximum time in seconds to fetch the page. default: 120
allow_redirects
follow 30x redirect default: True
一些网页的302的跳转是否重定向设置.
validate_cert
For HTTPS requests, validate the server’s certificate? default: True
HTTPS的证书请求忽略.
proxy
proxy server of username:password@hostname:port to use, only http proxy is supported currently.
class Handler(BaseHandler):
crawl_config = {
'proxy': 'localhost:8080'
}
Handler.crawl_config can be used with proxy to set a proxy for whole project.
设置代理.
etag
use HTTP Etag mechanism to pass the process if the content of the page is not changed. default: True
判断页面更新爬取情况.
last_modified
use HTTP Last-Modified header mechanism to pass the process if the content of the page is not changed. default: True
fetch_type
set to js to enable JavaScript fetcher. default: None
设置为js请求.渲染查找后的页面.
js_script
JavaScript run before or after page loaded, should been wrapped by a function like function() { document.write(“binux”); }.
网页爬取后,执行脚本.
def on_start(self):
self.crawl('http://www.example.org/', callback=self.callback,
fetch_type='js', js_script='''
function() {
window.scrollTo(0,document.body.scrollHeight);
return 123;
}
''')
The script would scroll the page to bottom. The value returned in function could be captured via Response.js_script_result.
js_run_at
run JavaScript specified via js_script at document-start or document-end. default: document-end
把脚本加到当我document前面还是后面.
js_viewport_width/js_viewport_height
set the size of the viewport for the JavaScript fetcher of the layout process.
JS视窗的大小.
load_images
load images when JavaScript fetcher enabled. default: False
加载时是否加载图片.
save
a object pass to the callback method, can be visit via response.save.
用来在多个函数直接传递变量的参数
def on_start(self):
self.crawl('http://www.example.org/', callback=self.callback,
save={'a': 123})
def callback(self, response):
return response.save['a']
123 would be returned in callback
taskid
unique id to identify the task, default is the MD5 check code of the URL, can be overridden by method def get_taskid(self, task)
指定task的唯一标识码,ruquest队列的消息去重.
import json
from pyspider.libs.utils import md5string
def get_taskid(self, task):
return md5string(task['url']+json.dumps(task['fetch'].get('data', '')))
Only url is md5 -ed as taskid by default, the code above add data of POST request as part of taskid.
force_update
force update task params even if the task is in ACTIVE status.
强制更新.
cancel
cancel a task, should be used with force_update to cancel a active task. To cancel an auto_recrawl task, you should set auto_recrawl=False as well.
取消任务.
@config(**kwargs)
default parameters of self.crawl when use the decorated method as callback. For example:
config里可以传递参数.
@config(age=15*60)
def index_page(self, response):
self.crawl('http://www.example.org/list-1.html', callback=self.index_page)
self.crawl('http://www.example.org/product-233', callback=self.detail_page)
@config(age=10*24*60*60)
def detail_page(self, response):
return {...}
age of list-1.html is 15min while the age of product-233.html is 10days. Because the callback of product-233.html is detail_page, means it’s a detail_page so it shares the config of detail_page.
Handler.crawl_config = {}
default parameters of self.crawl for the whole project. The parameters in crawl_config for scheduler (priority, retries, exetime, age, itag, force_update, auto_recrawl, cancel) will be joined when the task created, the parameters for fetcher and processor will be joined when executed. You can use this mechanism to change the fetch config (e.g. cookies) afterwards.
将一些配置放入其中,使其全局生效.
class Handler(BaseHandler):
crawl_config = {
'headers': {
'User-Agent': 'GoogleBot',
}
}
...
Response
Response.url
final URL.
Response.text
Content of response, in unicode.
返回网页源代码.
if Response.encoding is None and chardet module is available, encoding of content will be guessed.
Response.content
Content of response, in bytes.
返回网页源代码,二进制.
Response.doc
A PyQuery object of the response’s content. Links have made as absolute by default.
网页解析,调用 PyQuery的解析库.
Refer to the documentation of PyQuery: https://pythonhosted.org/pyquery/
It’s important that I will repeat, refer to the documentation of PyQuery: https://pythonhosted.org/pyquery/
Response.etree
A lxml object of the response’s content.
返回lxml对象
Response.json
The JSON-encoded content of the response, if any.
转换为Json格式.
Response.status_code
状态码:200,300等等.
Response.orig_url
If there is any redirection during the request, here is the url you just submit via self.crawl.
有重定向,就显示最原始的url.
Response.headers
A case insensitive dict holds the headers of response.
Response.cookies
Response.error
Messages when fetch error
Response.time
Time used during fetching.
Response.ok
True if status_code is 200 and no error.
判断请求是否OK.
Response.encoding
Encoding of Response.content.
用来指定编码
If Response.encoding is None, encoding will be guessed by header or content or chardet(if available).
Set encoding of content manually will overwrite the guessed encoding.
Response.save
The object saved by self.crawl API
指定不同函数直接传递参数.
Response.js_script_result
content returned by JS script
接受JS script的结果.
Response.raise_for_status()
Raise HTTPError if status code is not 200 or Response.error exists.
抛出一些错误.
self.send_message
部署过程中,消除队列的配置.
@every(minutes=0, seconds=0)
定时爬取中用的比较多.
method will been called every minutes or seconds
@every(minutes=24 * 60)
def on_start(self):
for url in urllist:
self.crawl(url, callback=self.index_page)
一天执行一次
The urls would be restarted every 24 hours. Note that, if age is also used and the period is longer then @every, the crawl request would be discarded as it’s regarded as not changed:
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://www.example.org/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self):
...
Even though the crawl request triggered every day, but it’s discard and only restarted every 10 days.
4 Frequently Asked Questions
Unreadable Code (乱码) Returned from Phantomjs
Phantomjs doesn’t support gzip, don’t set Accept-Encoding header with gzip.
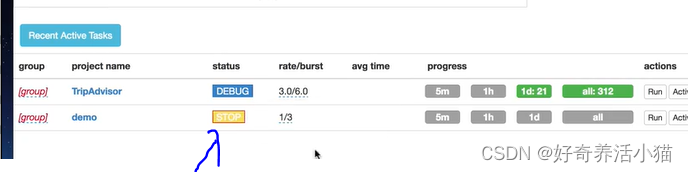
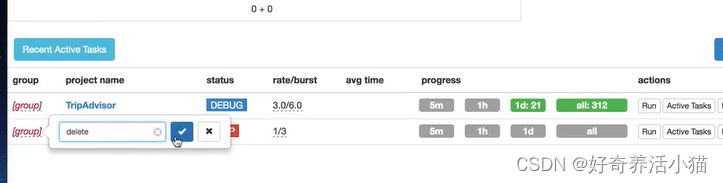
How to Delete a Project?
set group to delete and status to STOP then wait 24 hours. You can change the time before a project deleted via
scheduler.DELETE_TIME.
status to STOP:
group to delete:
How to Restart a Project?
Why
It happens after you modified a script, and wants to crawl everything again with new strategy. But as the age of urls are not expired. Scheduler will discard all of the new requests.
Solution
1.Create a new project.
2.Using a itag within Handler.crawl_config to specify the version of your script.
What does the progress bar mean on the dashboard?
When mouse move onto the progress bar, you can see the explaintions.
For 5m, 1h, 1d the number are the events triggered in 5m, 1h, 1d. For all progress bar, they are the number of total tasks in correspond status.
Only the tasks in DEBUG/RUNNING status will show the progress.