零.前情提要:
没有看上一章的小伙伴,建议先去看上一章,避免有些知识点不连贯
地址:Python爬虫实战第三例【三】【上】-CSDN博客
在上一章,我们经过分析.m3u8文件和.ts文件后,成功爬取到了所有.ts文件的文件名,并且成功下载了.ts文件,但是在上一节中我们只是下载了一个.ts文件,并没有实现批次的.ts文件下载。
接下来,我们就要进行批次爬取.ts文件,并且将它们组合在一起!
准备好了吗?跟随作者一起,走进爬虫的海洋吧!
一.批次爬取.ts文件
由于我们现在爬取.ts文件的函数,一次只能爬去一个.ts文件,那我们是不是可以在函数外面放一个for循环来实现批次爬取.ts文件呢?当然可以了!!
代码如下:
python"> #将ts_list转换为带有序号的列表,方便.ts文件的重命名,用来保持顺序一致!
ts_list = list(enumerate(ts_list))
for ts in ts_list:
down_video(ts)效果图:

但是这样是有一个问题的,那就是爬取完第一个.ts文件后,程序重新构造一大串.get请求并发送,这中间消耗了大量资源,并且可以发现效率很慢!!!如果共有1000个.ts文件,我们需要爬取三十分钟!!这显然不是我们想要看到的!!
学过线程的小伙伴可能想到了,这不是单线程造成的吗?对的,所以改进的话我们只需要改成多线程就可以啦!!
为此,我们先要导入线程池:
python">from multiprocessing.pool import ThreadPool代码如下:
python"> #创建线程池
pool = ThreadPool(100)
#利用map函数给线程分配工作
pool.map(down_video,enumerate(ts_list))效果图:

可以看到效率飞起!!效率大概提升了1000%!!!
(与个人CPU有关,CPU线程数越多效率越高)
二.重新爬取失败的文件
不过在爬取过程中,难免会有一些.ts文件因为网络波动的问题,导致超时,从而报错,这显然不是我们想看到的,为此我们该怎么办呢?
作者的想法是,创建一个检查函数,在执行完爬取.ts文件后,检查是否有文件没有被爬取!
代码如下:
python">#漏下的.ts文件列表
fil_list = []
#检查标志
file_flag = False
def down_video(item):
#全局变量标志,用来表示是第一次爬取.ts文件,还是爬取漏下的.ts文件!
global file_flag
#对item进行解包,提取出ts文件和ts文件索引
index,ts = item[0],item[1]
#拼接文件序号
if 0 <= index <=9:
index = "000" + str(index)
elif 10 <= index <= 99:
index = "00" + str(index)
elif 100 <= index <= 999:
index = "0" + str(index)
else:
index = str(index)
#爬取视频URL
URL = "https://s8.fsvod1.com/20230703/J6BHjLy3/1500kb/hls/"
#请求头
headers = {
"authority":"s8.fsvod1.com",
"method":"GET",
"path":f"/20221207/10692_4308abda/2000k/hls/{ts}",
"scheme":"https",
"Accept":r"*/*",
"Accept-Encoding":"gzip,deflate,br,zstd",
"Accept-Language":"zh-CN,zh;q=0.9",
"Origin":"https://test3.gqyy8.com:4438",
"Sec-Ch-Ua":'"Chromium";v="122","Not(A:Brand";v="24","Google Chrome";v="122"',
"Sec-Ch-Ua-Mobile":"?0",
"Sec-Ch-Ua-Platform":"Windows",
"Sec-Fetch-Dest":"empty",
"Sec-Fetch-Mode":"cors",
"Sec-Fetch-Site":"cross-site",
"User-Agent":"Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/122.0.0.0Safari/537.36"
}
#拼接视频url
URL = URL + "/" + ts
try:
r = requests.get(url=URL,headers=headers,timeout=10)
with open(f"{os.getcwd()}/爬取数据/" + index + ".ts", "wb") as file:
file.write(r.content)
except Exception as e:
if not file_flag:
fil_list.append([int(index),ts])
print(index,"写入失败,原因",e,sep="->")
return
if file_flag:
fil_list.remove(item)
print(index,"写入成功.",sep="->")
def check():
print("开始检查")
global file_flag
file_flag = True
while fil_list:
pool = ThreadPool(100)
results = pool.map(down_video, fil_list)
pool.close()
pool.join()
print("检查完毕")
if __name__ == "__main__":
ts_list = get_ts_txt()
create_filedir()
#创建线程池
pool = ThreadPool(100)
#利用map函数给线程分配工作
pool.map(down_video,enumerate(ts_list))
#检查函数
check()效果图:

也是成功全部爬取啦!!
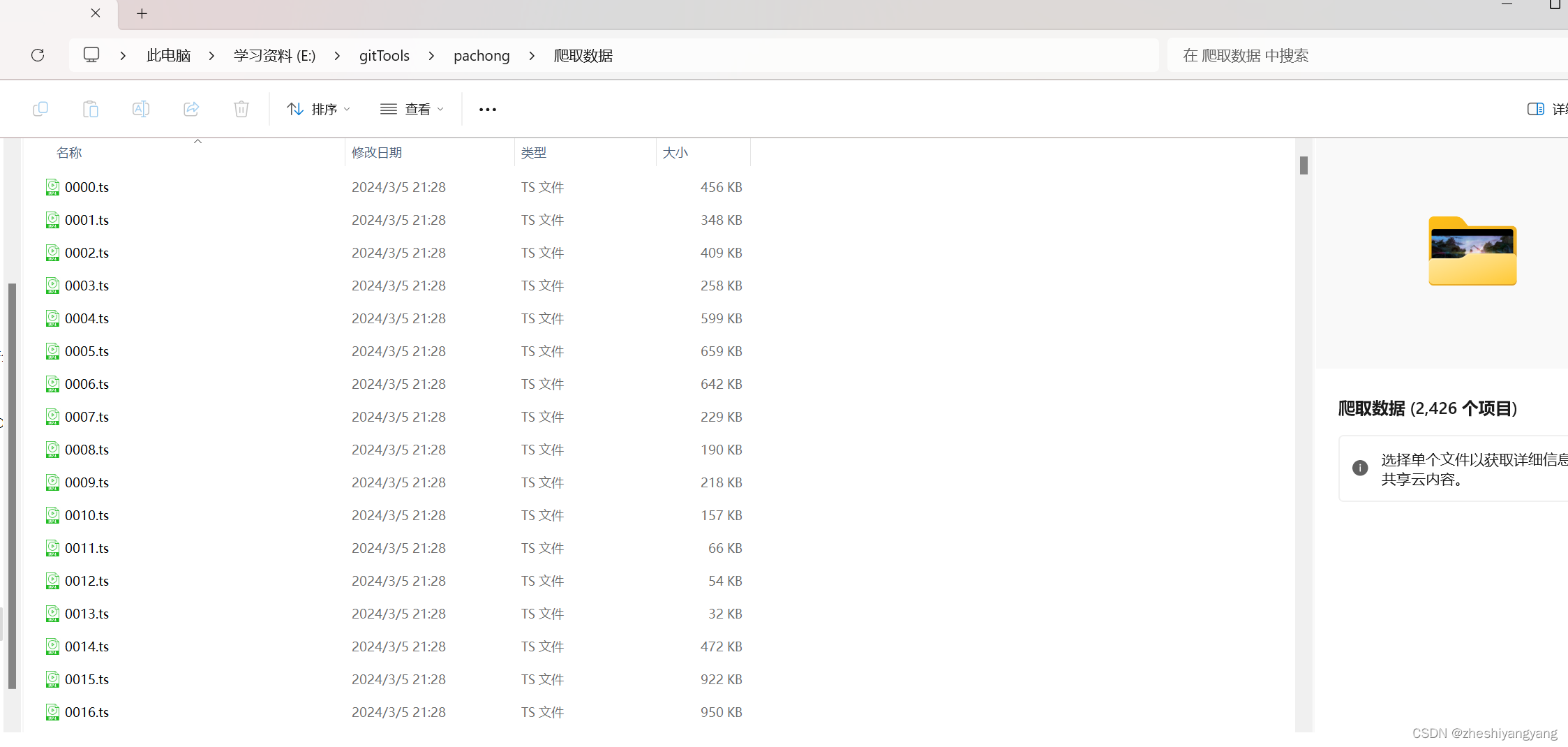
我累个逗啊!居然有2426个.ts文件!!
三.合成.ts文件
其实将所有.ts文件拼凑在一起,有很多方法,在这里作者给出一种相对简单的方法
1.首先进入cmd切换到我们的“爬取数据”路径下,如下图所示:
2.接下来输入指令:
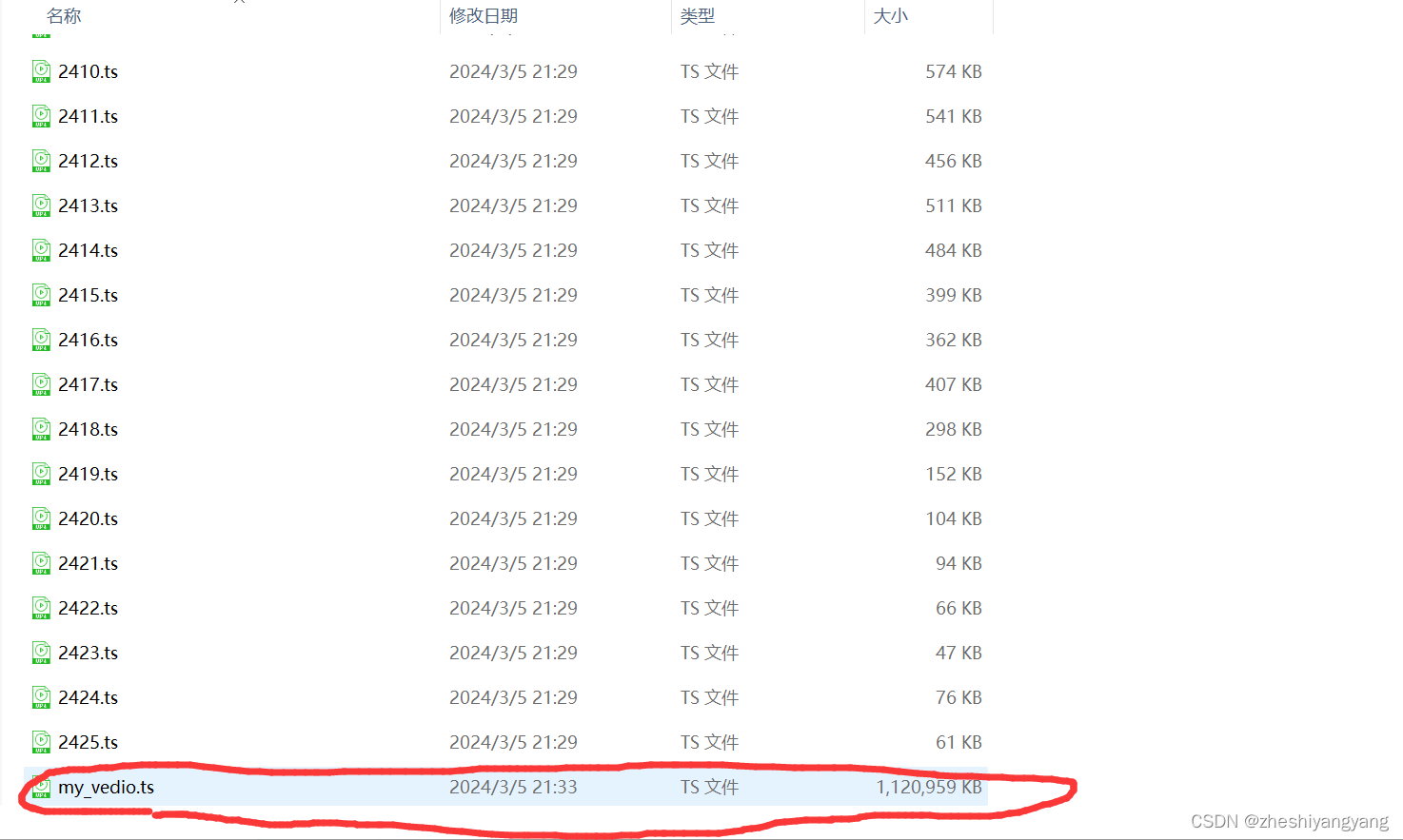
copy /b *.ts my_video.ts
结果如下图所示:

最后,去我们的文件夹里面找“my_video.ts”即可播放啦!!
芜湖,可以看玲芽啦~~
四.全部代码
python">import requests
import os
import re
from multiprocessing.pool import ThreadPool
#漏下的.ts文件列表
fil_list = []
#检查标志
file_flag = False
def get_ts_txt():
#4请求URL
url = "https://s8.fsvod1.com/20230703/J6BHjLy3/1500kb/hls/index.m3u8"
#请求头
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
reponse = requests.get(url=url,headers=headers)
get_txt = reponse.text
#正则匹配出.ts后缀数据
ts_files = re.findall(r"\b\w+\.ts\b",get_txt)
#将.ts数据写入到文件中中
with open("get_ts.txt","w") as file:
for i in ts_files:
i = i + "\n"
file.write(i)
print("获取ts文件成功.")
return ts_files
def create_filedir():
path = os.getcwd() + "/爬取数据"
if os.path.exists(path):
print("\\爬取视频文件夹已存在,本次不创建.")
else:
os.mkdir(path)
print("创建\\爬取文件夹成功.")
def down_video(item):
#全局变量标志,用来表示是第一次爬取.ts文件,还是爬取漏下的.ts文件!
global file_flag
#对item进行解包,提取出ts文件和ts文件索引
index,ts = item[0],item[1]
#拼接文件序号
if 0 <= index <=9:
index = "000" + str(index)
elif 10 <= index <= 99:
index = "00" + str(index)
elif 100 <= index <= 999:
index = "0" + str(index)
else:
index = str(index)
#爬取视频URL
URL = "https://s8.fsvod1.com/20230703/J6BHjLy3/1500kb/hls/"
#请求头
headers = {
"authority":"s8.fsvod1.com",
"method":"GET",
"path":f"/20221207/10692_4308abda/2000k/hls/{ts}",
"scheme":"https",
"Accept":r"*/*",
"Accept-Encoding":"gzip,deflate,br,zstd",
"Accept-Language":"zh-CN,zh;q=0.9",
"Origin":"https://test3.gqyy8.com:4438",
"Sec-Ch-Ua":'"Chromium";v="122","Not(A:Brand";v="24","Google Chrome";v="122"',
"Sec-Ch-Ua-Mobile":"?0",
"Sec-Ch-Ua-Platform":"Windows",
"Sec-Fetch-Dest":"empty",
"Sec-Fetch-Mode":"cors",
"Sec-Fetch-Site":"cross-site",
"User-Agent":"Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/122.0.0.0Safari/537.36"
}
#拼接视频url
URL = URL + "/" + ts
try:
r = requests.get(url=URL,headers=headers,timeout=10)
with open(f"{os.getcwd()}/爬取数据/" + index + ".ts", "wb") as file:
file.write(r.content)
except Exception as e:
if not file_flag:
fil_list.append([int(index),ts])
print(index,"写入失败,原因",e,sep="->")
return
if file_flag:
fil_list.remove(item)
print(index,"写入成功.",sep="->")
def check():
print("开始检查")
global file_flag
file_flag = True
while fil_list:
pool = ThreadPool(100)
results = pool.map(down_video, fil_list)
pool.close()
pool.join()
print("检查完毕")
if __name__ == "__main__":
ts_list = get_ts_txt()
create_filedir()
#创建线程池
pool = ThreadPool(100)
#利用map函数给线程分配工作
pool.map(down_video,enumerate(ts_list))
#检查函数
check()ps:复制上直接就可以爬取哦~