前情提要
今天我们开始更新Python爬虫实战例子,该系列预计会更很多很多期,因为实在有太多了!!
同样作为新人0,作者尽量在自己完全理解的基础上尽可能通俗易懂的讲解给大家,还望大家多多支持!
好了废话不多说,我们开始吧!
PS:对于该系列,你应该具备一定的计算机网络基础知识、Python基础知识、requests库知识、JSON知识。
爬取豆瓣排行榜并提取评分
目标网址:豆瓣电影排行榜
第一步:Google开发者工具
使用Google开发者工具,可以右键页面空白处再点击“检查”即可。

按照图片指示,依次点击两处。

再在排行榜里随便选一个,这里我选择:“喜剧”。

点击后可以看到开发者工具出现了下方两个文件,我们点击最后一个:
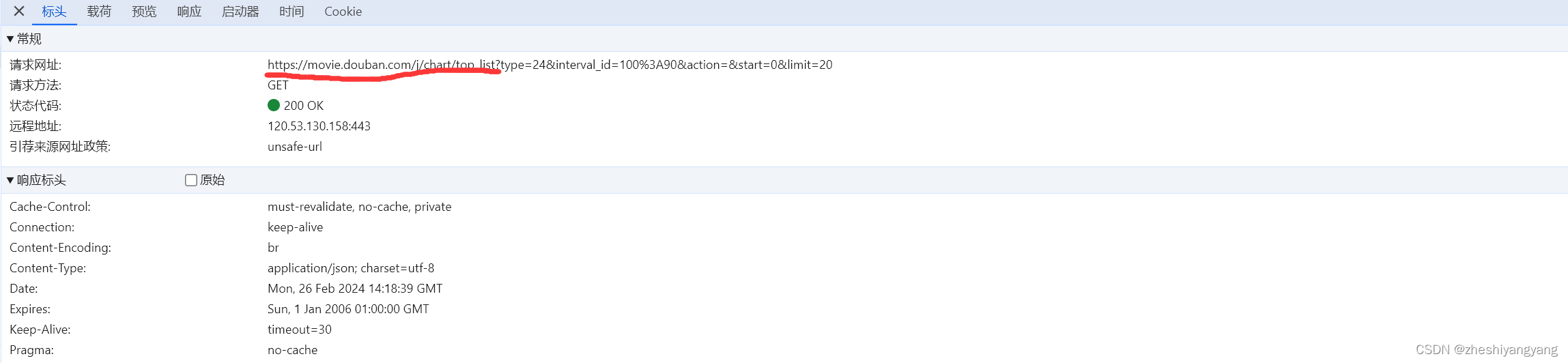
注意我们表头里面画红线的,就是我们后面需要的URL。
我们再往下拉,找到我们的浏览器配置【User-Agent】(反爬虫用的,很重要)

我们再点击载荷,查看我们的params参数:
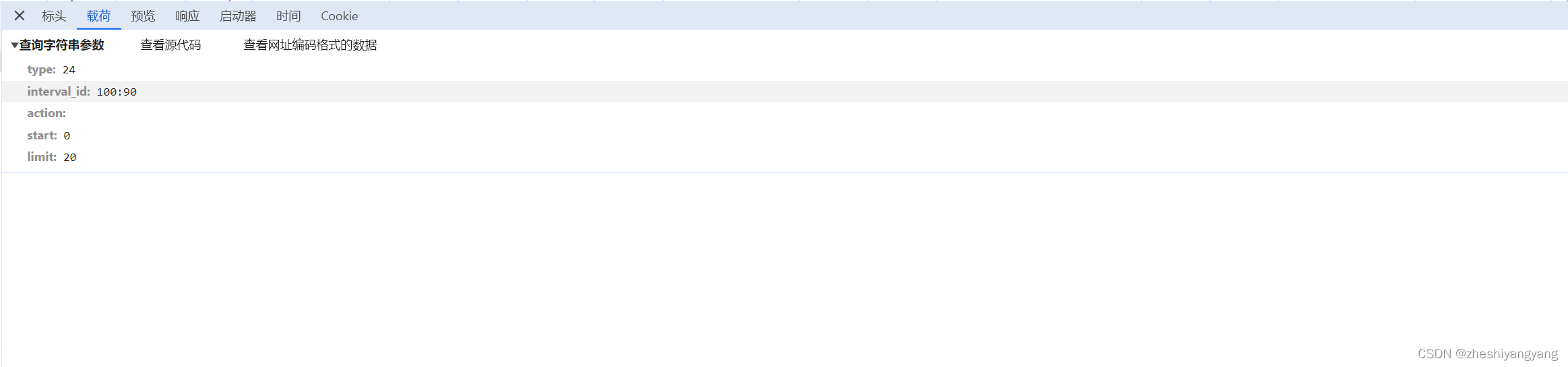
可以看到里面有很多东西,虽然英语我们都懂,但是具体的含义我们不懂,那该怎么办呢?
不用急,这时候我们滑动鼠标滚轮将浏览器页面下滑,可以看到多了很多一摸一样的文件,我们再次随意打开一个:
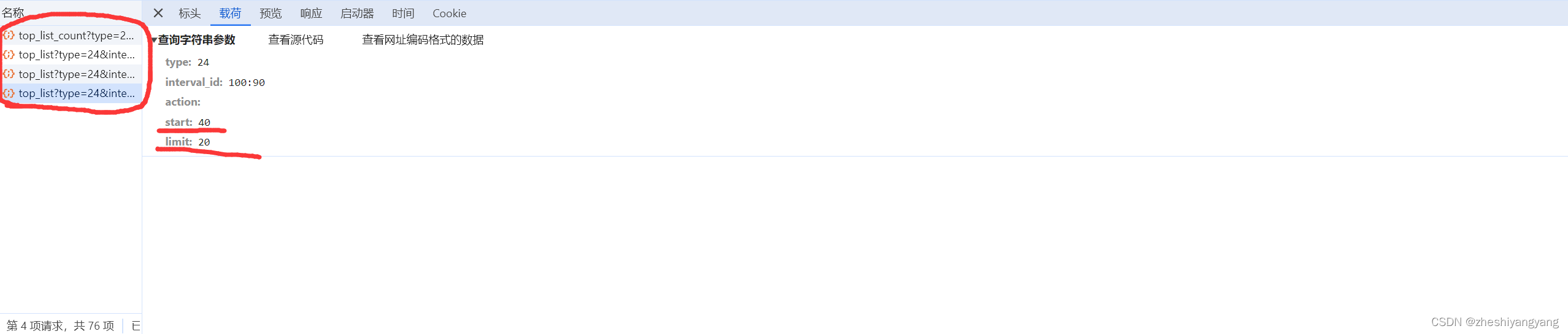
注意到,当我们鼠标下滑大概20个电影后,就会出现一个新的文件,而且文件中的载荷除了“start”这一项不同以外,其它的都相同,由此可以确定,start是“电影开始的序号”,limit是"每一个文件可以承载多少个电影"。
第二步:编写代码
在这里,我先给出一些配置代码:
import requests import json #此处的url就是上面我们找到的url url = "https://movie.douban.com/j/chart/top_list" #这里的parmas参数对应的是我们找到的载荷,这里我设置从0开始,一共爬取200个电影 params = { "type":"24", "interval_id":"100:90", "action":"", "start": "0", "limit":"200" } #这里的headers头我们设置浏览器配置,用来反爬虫 headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36" }
注意到上面的配置代码在我们第一步基本都已经找到了,下面我们来编写爬取代码:
#创建一个get请求 response = requests.get(url=url,params=params,headers=headers) #json方法用来提取get回答中的json格式的内容 content = response.json() print(content)
打印结果为:

可以看到数据非常的多且乱,如果这样看的话会死掉的,为此我们需要开始分析数据,改造成我们人类可以阅读的格式。
#查看content的类型是list【列表】 print(type(content)) #使用json的dumps方法将列表中的第一个元素切换为json格式,并且使用indent等参数变成便于阅读的格式 print(json.dumps(content[0],indent=4,ensure_ascii=False,separators=(",",": ")))
打印结果为:
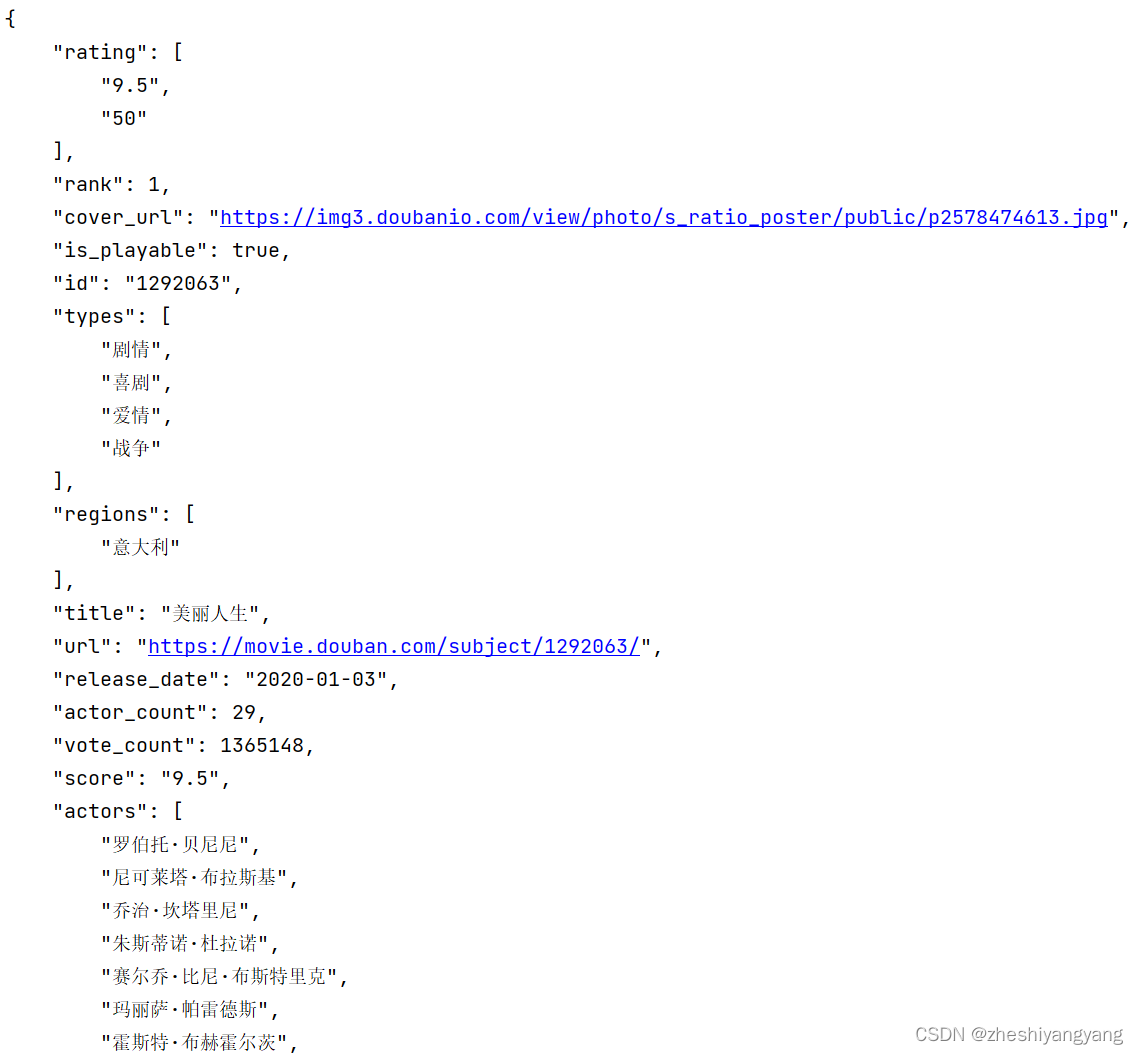
可以看到"title"跟"score"两个键对应的内容正好是电影名字跟得分,我们只需要这两项即可,所以我们要想办法把这两项分离出来:
#使用with语句打开文件 with open("豆瓣排行榜.txt","w",encoding="utf-8") as f: for item in content: #对每个item单独提取出title和score两个键 title = item["title"] score = item["score"] #对文件写入 f.write(title+"\t"+score+"\n") print("成功")
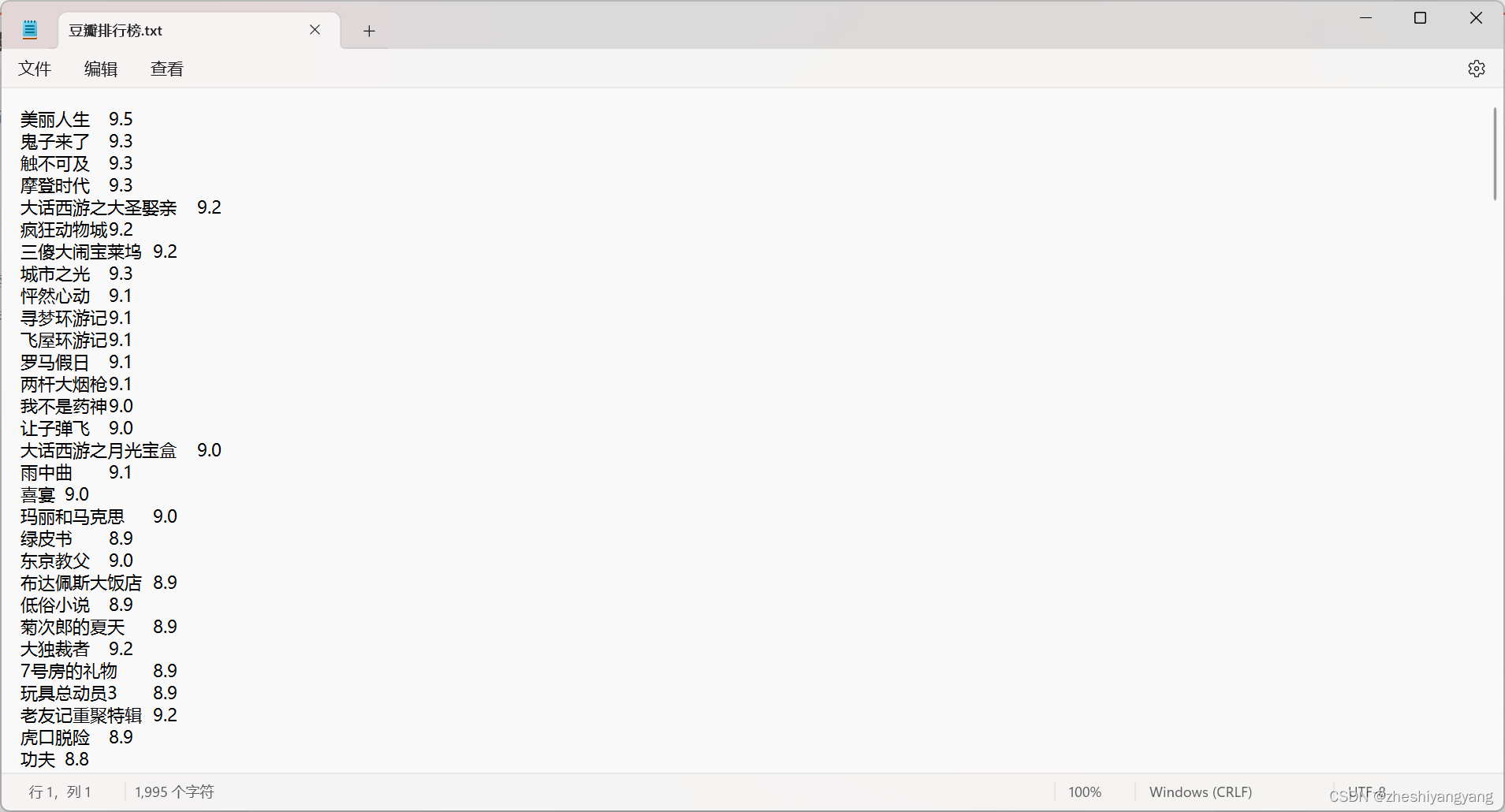
此时我们可以打开“豆瓣排行榜.txt”查看结果了:
总代码
import requests import json #此处的url就是上面我们找到的url url = "https://movie.douban.com/j/chart/top_list" #这里的parmas参数对应的是我们找到的载荷,这里我设置从0开始,一共爬取200个电影 params = { "type":"24", "interval_id":"100:90", "action":"", "start": "0", "limit":"200" } #这里的headers头我们设置浏览器配置,用来反爬虫 headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36" } #创建一个get请求 response = requests.get(url=url,params=params,headers=headers) #json方法用来提取get回答中的json格式的内容 content = response.json() #查看content的类型是list【列表】 print(type(content)) #使用json的dumps方法将列表中的第一个元素切换为json格式,并且使用indent等参数变成便于阅读的格式 print(json.dumps(content[0],indent=4,ensure_ascii=False,separators=(",",": "))) #使用with语句打开文件 with open("豆瓣排行榜.txt","w",encoding="utf-8") as f: for item in content: #对每个item单独提取出title和score两个键 title = item["title"] score = item["score"] #对文件写入 f.write(title+"\t"+score+"\n") print("成功")