vue3前端项目开发,具备纯天然的防止爬虫采集的特征!众所周知,网络爬虫可以在网上爬取到一些数据,很多公司,为了自己公司的数据安全, 尤其是web端项目,不希望被爬虫采集。那么,您可以使用vue技术开发web前端内容。下面给大家展示的是,黑马程序员的前端项目之一,小兔鲜的前端web项目内容。
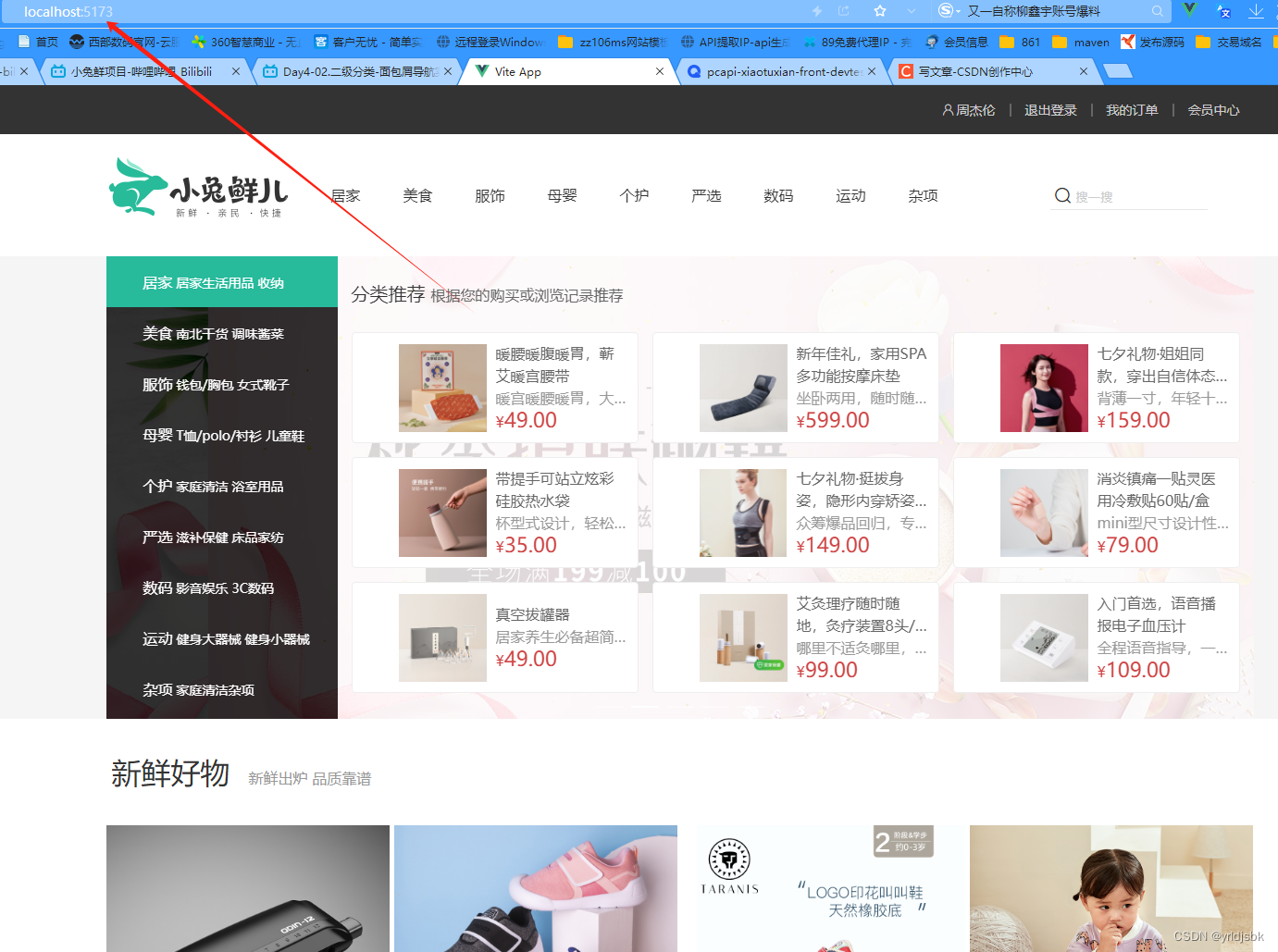
如图,我在自己本地借助于vite插件打开了这个项目,在浏览器内浏览到了前端的页面。这个是默认的首页面截图。
<script setup>
</script>
<template>
<!--一级路由的出口-->
<RouterView />
</template>
<style scoped lang="scss">
</style>
App.vue作为入口文件,里面可以看见就写了一个路由标签。我们使用到了路由插件,router.,在里面配置好了首页的模版路径。
import { createRouter, createWebHistory } from 'vue-router'
//createRouter:创建router的实例对象
//createWebHistory:创建history模式的路由
import Login from '@/views/login/index.vue'
import Layout from '@/views/layout/index.vue'
import Home from '@/views/home/index.vue'
import Categroy from '@/views/category/index.vue'
const router = createRouter({
history: createWebHistory(import.meta.env.BASE_URL),
routes: [
//path和component对应关系
{
path:'/',
component:Layout,
children:[
{
//默认不写内容,就是会跟着一起渲染的
path:'',
component:Home
},
{
path:'category',
component:Categroy
}
]
},
{
path:'/login',
component:Login
}
]
})
export default router
如图,里面可以看见“/”,对应的组件是Layout组件。
这里需要给大家提个醒,里面还有子组件呢,而且,重点来了,子组件里面有一个是没有写内容的,我加了注释,不写内容,默认就会跟着启动渲染出来的。它对应的组件是home。
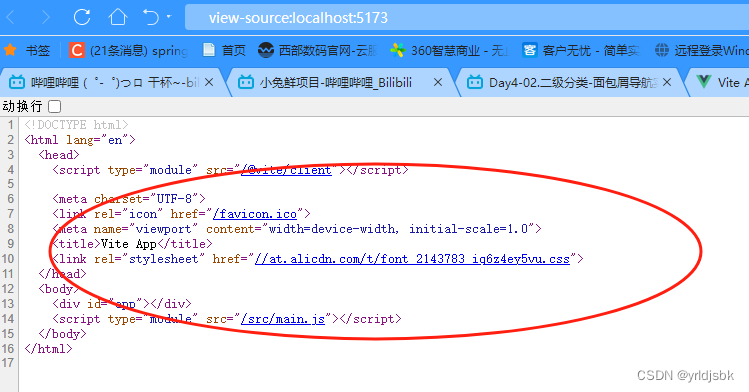
跑题了,回归到数据安全的层面,我们打开查看源代码,可以看见,里面其实看不见具体的业务数据了。因为被vue技术框架封装起来了。
这个就可以避免一些爬虫采集器的数据抓取了。纯天然,vue技术自带反爬虫的特征。
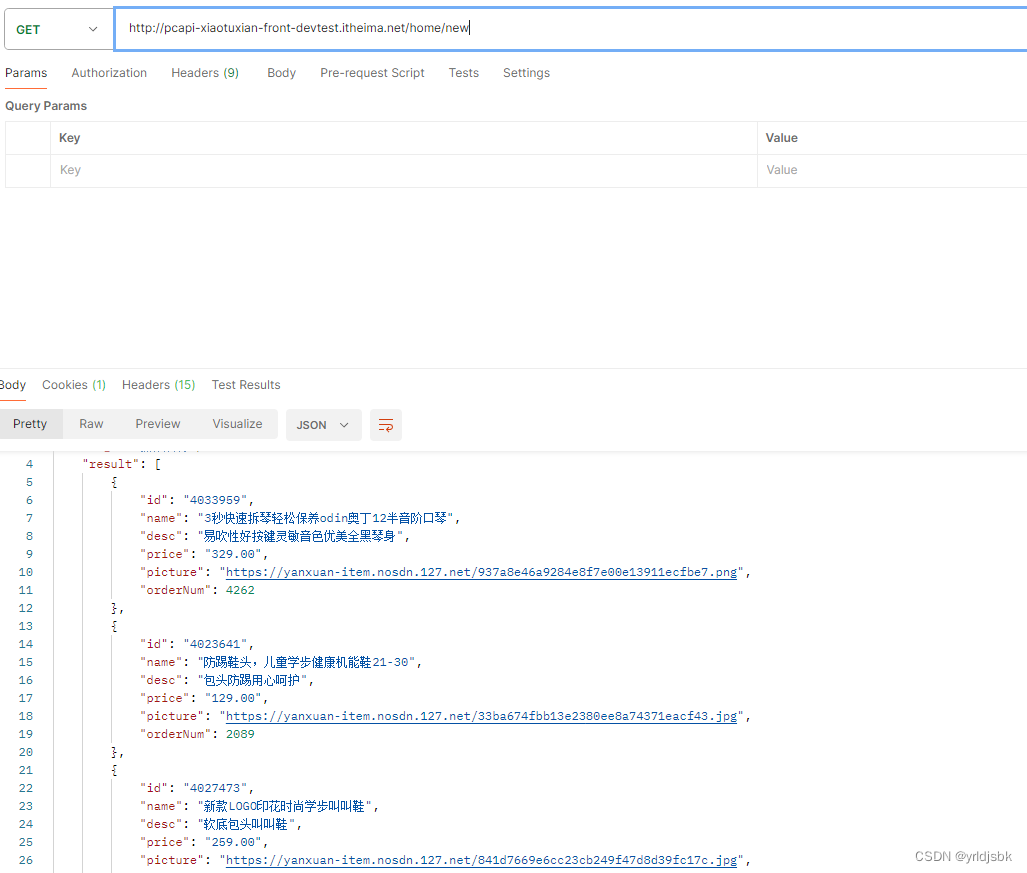
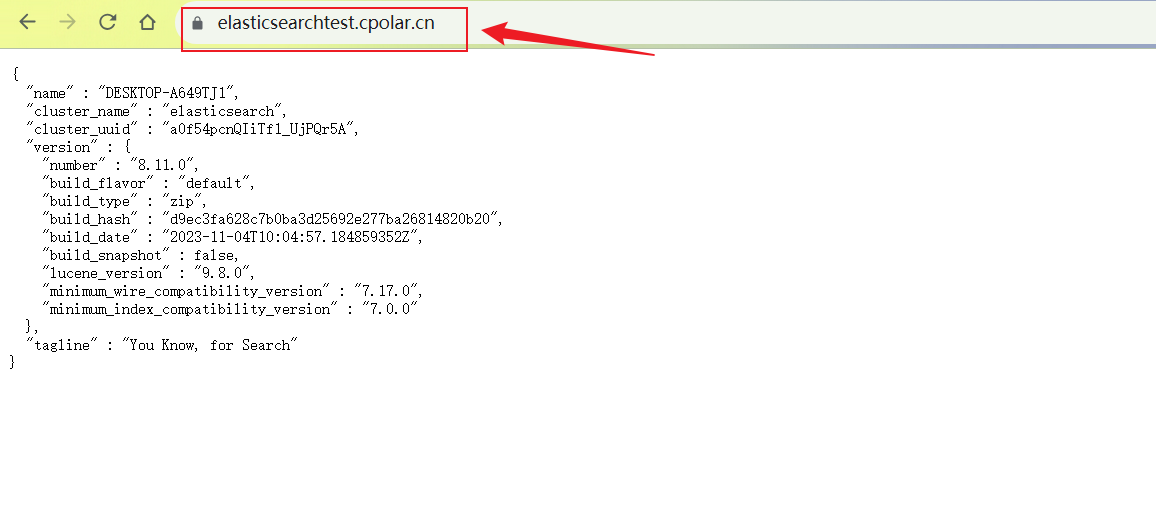
如图,黑马程序员提供了他们的官方业务数据接口调用。我这个是其中一个接口调用。
大家想自学vue项目开发,可以考虑一下黑马程序员的课程,讲的还是比较详细的。适合新手练习项目。入门项目。


![命令执行 [WUSTCTF2020]朴实无华1](https://img-blog.csdnimg.cn/direct/9d086fbe3ecb42f68bd548d6bef3a84e.png)