基于Python的网络爬虫的微博热点分析是一项技术上具有挑战性的任务。我们使用requests库来获取微博热点数据,并使用pandas对数据进行处理和分析。为了更好地理解微博热点话题,我们采用LDA主题分析方法,结合jieba分词工具将文本分割成有意义的词语。此外,我们还使用snownlp情感分析库来评估微博热点话题的情感倾向。
在实施该分析过程中,我们首先通过网络爬虫技术从微博平台上收集热点数据。然后,使用pandas库对数据进行清洗、去重和预处理,以便更好地理解数据。接下来,我们使用jieba对微博内容进行分词处理,将其转化为有意义的词语。随后,我们运用LDA主题分析算法对微博热点话题进行建模和分类,以揭示话题之间的关联和趋势。最后,我们使用matplotlib库进行数据可视化,将分析结果以图表形式呈现,帮助用户更直观地了解微博热点话题的情况。通过这个基于Python的网络爬虫的微博热点分析流程,我们可以更深入地了解微博用户的关注点和情感倾向。这对于舆情监测、市场调研和品牌管理等领域都具有重要的应用价值。同时,该分析流程也为其他社交媒体平台的热点分析提供了参考和借鉴。
- 网络爬虫的程序架构及整体执行流程
1、网络爬虫程序框架
基于Python的网络爬虫的微博热点分析项目,以下是网络爬虫程序框架:
导入所需的库:导入requests库用于发送HTTP请求,导入BeautifulSoup库用于解析HTML页面。
构造URL:根据微博热点数据的URL结构,构造需要访问的URL。可以通过添加查询参数来获取特定话题、时间范围或其他条件的数据。
发送请求并获取响应:使用requests库发送GET请求,将URL作为参数传递给get()函数,并将响应保存在变量中。
解析HTML页面:利用BeautifulSoup库对响应进行解析,提取出需要的数据,如微博内容、用户信息和评论等。
数据处理和存储:将解析得到的数据进行清洗、去重和格式化处理,然后可以选择将数据保存到文件中或存储在数据库中,以备后续分析使用。
重复步骤2-5:根据需求,可以设置循环或递归,以便获取多个页面的数据或持续监测微博热点。
实际开发中可能需要考虑更多的细节和边界情况,比如处理反爬措施、设置请求头部信息、处理异常情况等。通过这个框架,可以构建一个基本的网络爬虫程序,用于采集微博热点数据供后续分析使用。网络爬虫程序架构如图1所示。

图1网络爬虫程序架构图
2、网络爬虫的整体流程
- 获取初始URL;
- 发送请求并获取响应;
- 解析HTML页面;
- 数据处理和存储;
- 分析是否满足停止条件,并进入下一个循环。
网络爬虫的整体流程图如图2所示。
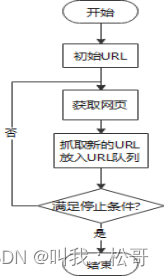
图2 网络爬虫的整体流程图
3、需求分析
数据采集需求:通过使用requests库实现微博热点数据的采集。需要获取最新和最热门的微博热点话题数据,包括话题内容、用户评论和转发数量等信息。
数据清洗和预处理需求:利用pandas库对采集到的数据进行清洗、去重和预处理,以便后续的数据分析和建模。需要处理缺失值、异常值和不一致的数据,并将其转换为适合分析的格式。
文本分析需求:使用jieba分词工具将微博内容进行分词,将文本转化为有意义的词语。这样可以更好地理解微博热点话题的关键词和主题。同时,需要应用LDA主题分析算法,从大量数据中提取潜在的话题模式和关联性。
情感分析需求:利用snownlp情感分析库对微博热点话题的情感倾向进行评估。这可以帮助我们了解用户对话题的情感态度和意见,从而更全面地分析微博热点话题的影响力和用户反馈。
可视化需求:使用matplotlib库进行数据可视化,将分析结果以图表的形式呈现出来。这样可以直观地展示微博热点话题的趋势、情感倾向和关联性,帮助用户更好地理解和解读分析结果。
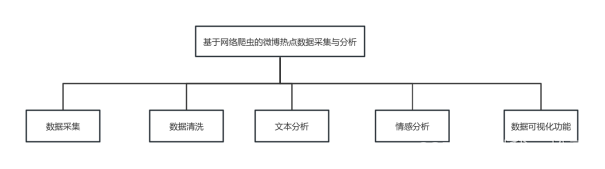
4、网络爬虫系统设计
数据采集模块:使用requests库发送HTTP请求,根据微博热点数据的URL结构构造请求,并获取响应。解析HTML页面,提取所需的数据,如微博内容、用户信息和评论等。
数据清洗和预处理模块:使用pandas库对采集到的数据进行清洗、去重和预处理。处理缺失值、异常值和不一致的数据,将其转换为适合分析的格式。
文本分析模块:使用jieba分词工具将微博内容进行分词处理,将文本转化为有意义的词语。应用LDA主题分析算法,从大量数据中提取潜在的话题模式和关联性。
情感分析模块:利用snownlp情感分析库对微博热点话题的情感倾向进行评估。分析文本的情感色彩,了解用户对话题的情感态度和意见。
可视化模块:使用matplotlib库进行数据可视化,将分析结果以图表的形式呈现出来。生成趋势图、饼图等可视化工具,直观地展示微博热点话题的特征和趋势。。
根据以上设计思路和设计原则得出功能结构图。如图3所示。
5、网页数据的爬取
基于Python的网络爬虫对微博热点数据进行爬取,并将爬取到的数据存储到CSV文件中。具体实现过程如下:
首先,使用requests库发送HTTP请求,模拟用户访问微博热点页面。通过循环遍历不同页数,获取每一页上的微博博文的链接。
然后,使用BeautifulSoup库解析HTML页面,提取出博文的编号和其他相关信息。在解析过程中,还包括一些正则表达式的处理,以获取更精确的数据。
接着,利用requests库再次发送HTTP请求,获取每篇博文的详细内容。根据博文编号构造请求URL,并携带必要的参数,如Cookie和Headers等,以模拟登录状态。
在获取到博文详细内容后,使用json库解析响应结果,提取出博文的正文、发布人ID、点赞数、评论数、转发数等关键信息。
根据需要,对博文的全文进行展开处理,如果有全文内容,则提取全文内容;否则,将正文内容作为全文。
最后,将爬取到的数据以列表形式存储,并使用csv库将数据写入到CSV文件中。
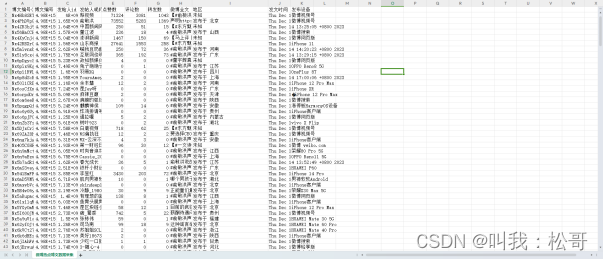
该数据爬取功能的作用是获取微博热点话题下的博文数据,包括博文的文本内容、点赞数、评论数等信息。这些数据可以用于后续的数据分析和可视化,如使用pandas库对数据进行清洗和处理,使用matplotlib库将结果可视化呈现,以便更好地理解微博热点话题的趋势、情感倾向和关联性。
通过这个数据爬取功能,可以实现对微博热点话题的全面分析和洞察,帮助用户了解公众舆论、用户需求和市场趋势,从而支持舆情监测、市场调研、品牌管理等领域的决策和判断。最后抓取数据代码运行结果如图4所示。
- SnowNLP库进行情感分析
通过使用SnowNLP库对微博热点博文的内容进行情感分析,计算每篇博文的情感分数。根据情感分数的大小,将博文划分为积极、中性或消极情感,并将情感分数和情感分析结果添加到数据中。这样可以帮助用户了解微博热点话题下博文的情感倾向和态度,从而更全面地分析和解读微博热点话题的影响力和用户反馈。代码如下所示。

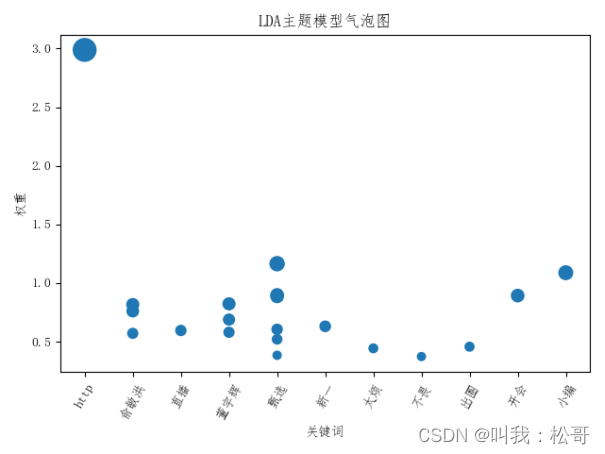
LDA主题分析
通过plt.scatter()函数,可以将两个变量的关系以散点图的形式呈现。在微博热点分析中,可以使用散点图展示关键词和权重之间的关系,例如将关键词作为横坐标,权重作为纵坐标,以点的大小或颜色表示权重的大小,从而观察关键词的分布情况和权重的差异。