在上一篇文章中,我们了解了爬虫的原理以及要实现爬虫的三个主要步骤:下载网页-分析网页-保存数据。
下面,我们就来看一下:如何使用Python下载网页。
1、网页是什么?
浏览器画网页的流程,是浏览器将用户输入的网址告诉网站的服务器,然后网站的服务器将网址对应的网页返回给浏览器,由浏览器将网页画出来。
这里所说的网页,一般都是一个后缀名为 html 的文件。
网页文件和我们平时打交道的文件没什么不同,平时我们知道 Word 文件,后缀名为 .doc, 通过 Word 可以打开。图片文件后缀名为 .jpg,通过 Photoshop 可以打开;而网页则是后缀名为 .html,通过浏览器可以打开的文件。
网页文件本质也是一种文本文件,为了能够让文字和图片呈现各种各样不同的样式,网页文件通过一种叫作 HTML 语法的标记规则对原始文本进行了标记。
(1)手动下载网页
我们以煎蛋网为例体会一下网页的实质,使用浏览器打开这个链接http://jandan.net/可以看到如下界面。可以看到,第一条新闻的标题前缀是:今日好价。网页内容可能会随时间变化,这里你只需要注意第一条新闻的前几个字(暗号)即可,下同。

在空白区域点击右键,另存为,并在保存类型中选择:仅 HTML。
接下来回到桌面,可以看到网页已经被保存到桌面了,后缀名是 html,这个就是我们所说的网页文件。
(2)网页内容初探
我们右键刚下载的文件,选择用 VS Code 打开,打开后的文件内容如下图所示。
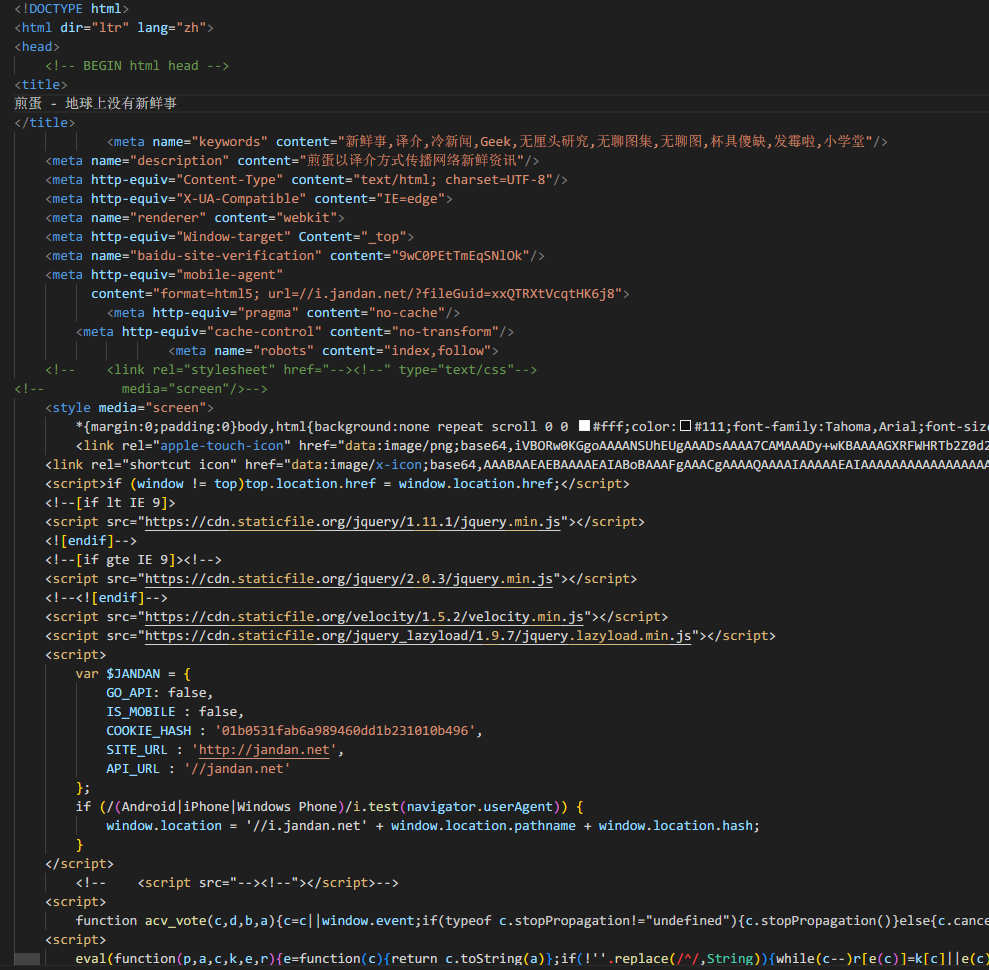
这就是网页文件的实际内容(未被浏览器画出来之前)。现在先不用管看不懂的代码,还记得我们看到的第一条新闻吗?“今日好价………………”。(你的暗号)
我们在 VS Code 中通过 CTRL + F 调出搜索面板,搜索“今日好价”(暗号)。可以看到成功找到了这条新闻,虽然被很多不认识的代码包围,但这也可以确定,我们看到的煎蛋网的主页确实就是这个 html 文件。

2、如何实现下载普通网页?
Python 以系统类的形式提供了下载网页的功能,放在 urllib3 这个模块中。这里面有比较多的类,我们并不需要逐一都用一遍,只需要记住主要的用法即可。
(1)获取网页内容
还是以煎蛋网为例。在我们打开这个网页的时候,排在第一的新闻是:“天文学家首次见证黑洞诞生”。
煎蛋又更新了新的新闻,你记住你当时的第一条新闻题目即可。我们待会儿会在我们下载的网页中搜索这个标题来验证我们下载的正确性。
下面开始,打开vscode,输入如下代码:
# 导入 urllib3 模块的所有类与对象
import urllib3
# 将要下载的网址保存在 url 变量中,英文一般用 url 表示网址的意思
url = "http://jandan.net/p/date/2021/03/23"
# 创建一个 PoolManager 对象,命名为 http
http = urllib3.PoolManager()
# 调用 http 对象的 request 方法,第一个参数传一个字符串 "GET"
# 第二个参数则是要下载的网址,也就是我们的 url 变量
# request 方法会返回一个 HTTPResponse 类的对象,我们命名为 response
response = http.request("GET", url)
# 获取 response 对象的 data 属性,存储在变量 response_data 中
response_data = response.data
# 调用 response_data 对象的 decode 方法,获得网页的内容,存储在 html_content
# 变量中
html_content = response_data.decode()
# 打印 html_content
print(html_content)
上述代码就完成了一个完成的网页下载的功能。其中有几个额外要注意的点:
- 我们创建 PoolManager的时候,写的是 urllib3.PoolManager,这里是因为我们导入了 urllib3 的所有类与函数。所以在调用这个模块的所有函数和类的前面都需要加模块名,并用点符号连接。
- response 对象的 data 属性也是一个对象,是一个 bytes 类型的对象。通过调用 decode 方法,可以转化成我们熟悉的字符串。
执行上述代码,可以看到打印出了非常多的内容,而且很像我们第一部分手动保存的网页,这说明目前 html_content 变量中保存的就是我们要下载的网页内容。
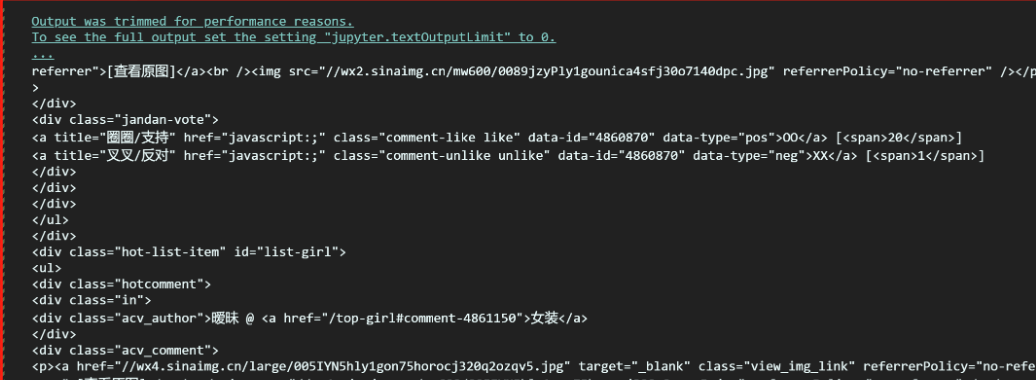
(2)将网页保存到文件
现在 html_content 已经是我们想要的网页内容,对于完成下载只差最后一步,就是将其保存成文件。其实这一步已经和保存网页无关的,而是我们如何把一个字符串保存成一个文件。
Python 中,读取文件和保存文件都是通过文件对象来完成的。接下来,我们通过实际的例子来了解这个技术。
新建 Cell,输入以下代码:
# 调用 open 函数,三个参数都是字符串类型,第一个参数为要操作的文件名
# 第二个参数代表模式,w 表示写入文件,r 表示读取文件
# 第三个参数表示编码格式,一般有中文的认准 utf-8 就好
# open 函数返回一个文件对象,我们存储在 fo 变量中
fo = open("jiandan.html","w", encoding="utf-8")
# 调用文件对象的 write 方法,将我们上面存储着网页内容的字符春变量,html_content
# 作为参数
fo.write(html_content)
# 关闭文件对象
fo.close()
执行完上述代码后,可以在 VS Code 的左侧边栏中看到,文件夹下多了一个 jiandan.html 的文件,这个就是我们用刚才 Python 代码保存的文件。
打开就可以看到熟悉的网页内容了。
(3)让我们的代码更加通用
刚才我们在两个 cell 中分别实现了将网页保存成一个字符串,以及将字符串保存为一个文件。如果我们要抓取新的网页,要么直接修改之前的代码,要么就需要拷贝一份代码出来。
这两种方式都不是很好,基于我们之前了解的内容,对于有一定通用度的代码我们可以将其改写为函数,来方便后续使用。
改写之后的代码如下:
# 第一个函数,用来下载网页,返回网页内容
# 参数 url 代表所要下载的网页网址。
# 整体代码和之前类似
def download_content(url):
http = urllib3.PoolManager()
response = http.request("GET", url)
response_data = response.data
html_content = response_data.decode()
return html_content
# 第二个函数,将字符串内容保存到文件中
# 第一个参数为所要保存的文件名,第二个参数为要保存的字符串内容的变量
def save_to_file(filename, content):
fo = open(filename,"w", encoding="utf-8")
fo.write(content)
fo.close()
url = "http://jandan.net/"
# 调用 download_content 函数,传入 url,并将返回值存储在html_content
# 变量中
html_content = download_content(url)
# 调用 save_to_file 函数,文件名指定为 jiandan.html, 然后将上一步获得的
# html_content 变量作为第二个参数传入
save_to_file("jiandan.html", html_content)
这样改写之后,我们在抓取新的网页的时候就可以使用 download_content 函数和 save_to_file 函数快速完成了,不再需要去写里面复杂的实现。
3、如何实现动态网页下载?
urllib3 很强大,但是却不能一劳永逸地解决网页下载问题。对于煎蛋这类普通网页,urllib3 可以表现更好,但是有一种类型的网页,它的数据是动态加载的,就是先出现网页,然后延迟加载的数据,那 urllib3 可能就有点力不从心了。
我们以豆瓣的电视剧网页为例:
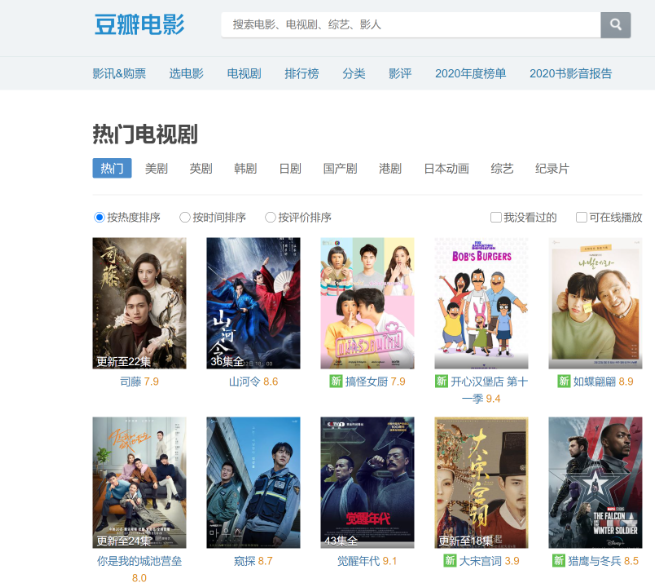
现在,我们来使用刚才定义的两个函数来下载一下这个网页。
url = "https://movie.douban.com/tv"
html_content = download_content(url)
save_to_file("douban_tv.html", html_content)
代码很简单,就是把豆瓣电视剧的网页下载到 douban_tv.html 这个文件中。执行代码,可以在 VS Code 左边的文件夹视图中看到成功生成了douban_tv.html 这个文件,这说明网页已经下载成功。
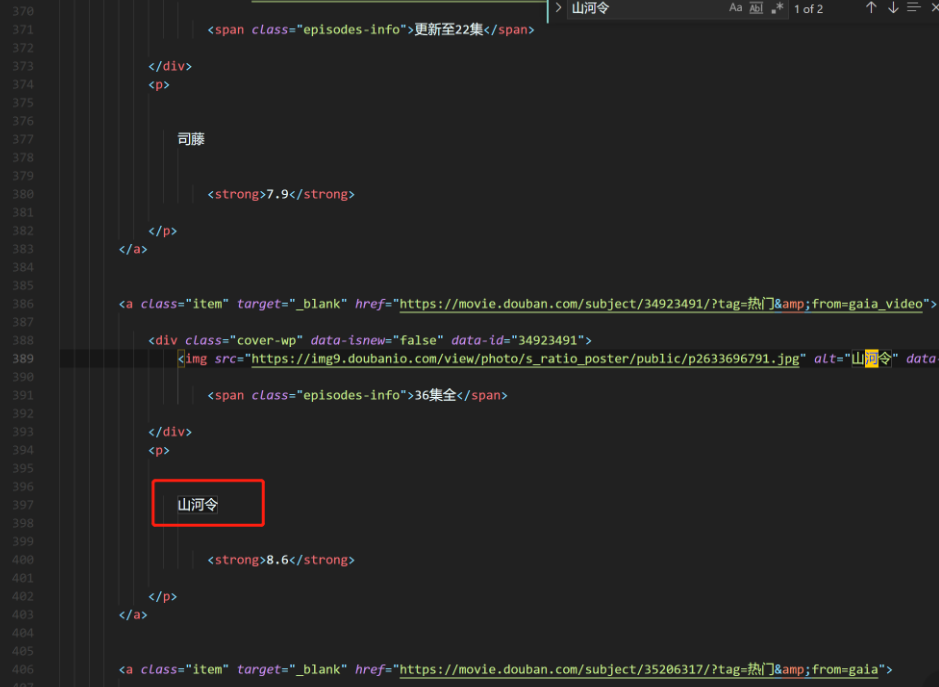
现在我们在 VS Code 中打开这个网页,搜索上图中出现的电视剧:“山河令”。这次却神奇的搜不到了,事实上,你会发现我们在网页看到的电视剧名字都搜不到。
为什么我们明明下载到了网页但是却搜不到电视剧呢?造成这个现象的原因是豆瓣电视剧网页中的电视剧列表的部分是动态加载的,所以我们用 urllib3 去直接下载,只能下载到一个壳网页,没有里面的列表内容。这种网页内部的数据是动态加载的网页,我们统一称之为动态网页。
动态网页应该怎么抓取呢?回过头去想,一个网页不管再怎么动态,最终都是要展示给用户看的,所以浏览器应该是最知道网页内容是什么的角色。如果我们可以使用代码控制浏览器来帮我们下载网页,应该就可以解决动态网页的抓取问题。
接下来我们就介绍使用 Python 来控制浏览器的利器:selenium。
(1)安装selenium
selenium 不属于 Python 的系统库,所以要使用这个库需要先进行安装。
我们安装 Python 的库一般通过 Anaconda 的命令行。既然是模拟浏览器,我们的电脑首先要先有浏览器。这里我们以 Chrome 为例。所以在一切开始之前,你需要确保你电脑上安装了 Chrome。
在准备环节,我们已经安装了 Anaconda 套件,现在我们去开始菜单(或者在桌面状态下按 Win 键)找到 Anaconda 3 文件夹,并点击文件夹中的 Anaconda Prompt 程序。Mac 用终端即可。
打开后会出现一个命令行窗口,在这个命令行,我们可以输入 conda install xxx 来安装 Python 的扩展库。
比如在这个例子中,我们输入 conda install selenium,回车。界面会变得如下所示,询问我们是否要确认安装,输入 y 继续回车就可以。
安装完毕后命令行窗口会回到待输入命令的状态,此时就可以关闭了。
回到 VS Code,新建 Cell,输入以下的测试代码:
# 从 selenium 库中导入 webdriver 类
from selenium import webdriver
# 创建一个 Chrome 浏览器的对象
brow = webdriver.Chrome()
# 使用 Chrome 对象打开 url(就是刚才豆瓣电视剧的 url)
brow.get(url)
运行代码,会自动打开一个 Chrome 浏览器的窗口,并展示 url 对应的网页。同时还会有一个提示,说明这个浏览器窗口是在被程序控制的,如下图所示。
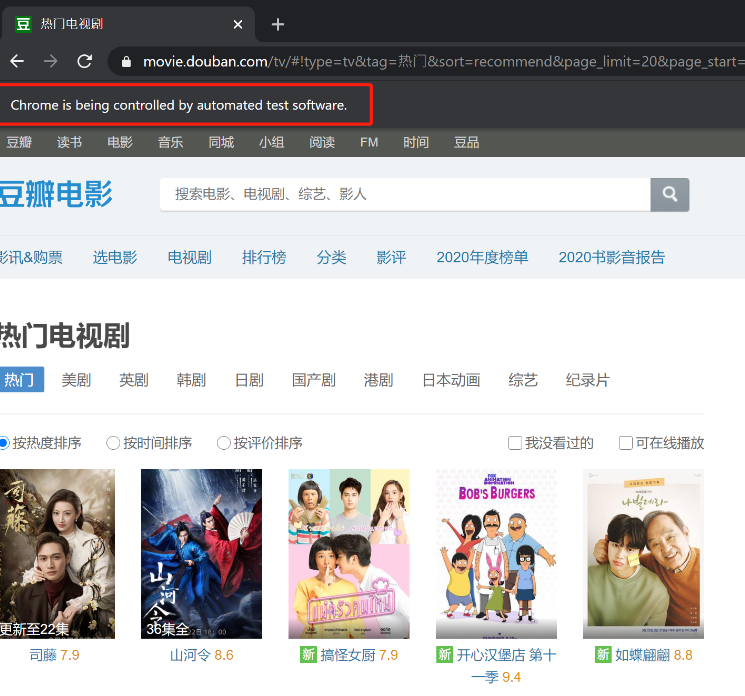
如果代码运行出错,提示找不到 chromedriver。那说明你安装的 selenium 版本缺少 chromedriver, 可以按如下方式操作:
- 重新按照刚才的方法打开 Anaconda Prompt,输入 pip install --upgrade --force-reinstall chromedriver-binary-auto 回车执行安装。
- 在上面的代码增加一行 import chromedriver_binary 添加完毕后如下所示。
# 从 selenium 库中导入 webdriver 类
from selenium import webdriver
# 导入 chromedriver
import chromedriver_binary
# 创建一个 Chrome 浏览器的对象
brow = webdriver.Chrome()
# 使用 Chrome 对象打开 url(就是刚才豆瓣电视剧的 url)
brow.get(url)
(2)使用selenium下载动态网页
如果刚才的代码已经运行成功并打开了 Chrome 的界面的话,那我们离最后的下载动态网页已经不远了。在我们通过 Chrome 对象打开了一个网页之后,只需要访问 Chrome 对象的 page_source 属性即可拿到网页的内容。
代码如下:
# 从 selenium 库中导入 webdriver 类
from selenium import webdriver
# 创建一个 Chrome 浏览器的对象
brow = webdriver.Chrome()
# 使用 Chrome 对象打开 url(就是刚才豆瓣电视剧的 url)
brow.get(url)
# 访问 Chrome 对象的 page_source 属性,并存储在 html_content 变量中
html_content = brow.page_source
# 调用我们之前定义的 save_to_file 函数,这次我们保存为 double_tv1.html
# 要保存的内容就是 html_content
save_to_file("douban_tv1.html", html_content)
运行代码,可以看到 Chrome 被打开并加载网页,等电视剧列表都加载完之后,在 VS Code 中可以看到 double_tv1.html 也被成功创建。
这个时候我们去这个文件搜索山河令,发现已经有结果了,在这个 html 文件中已经有了所有电视剧的信息。
至此,我们也实现了对于动态内容网页的下载功能。



