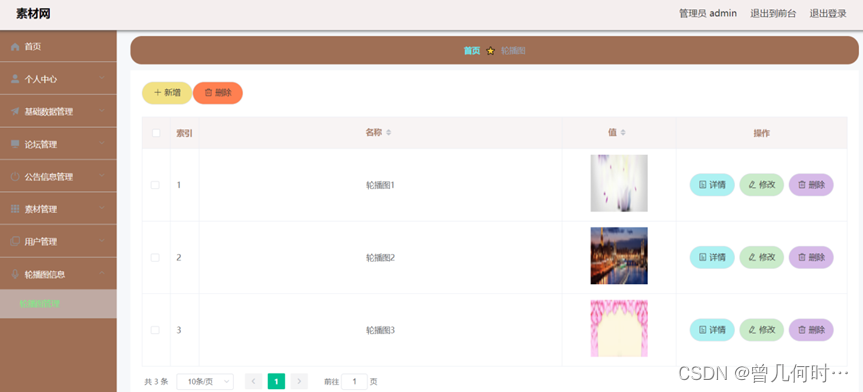
有些自动化工具可以获取浏览器当前呈现的页面的源代码,可以通过这种方式来进行爬取
一般常用的的有Selenium, playwright, pyppeteer,考虑到他们的使用有许多相同之处,因此考虑把他们封装到一套api中
先看基类
class BrowserSimulateBase:
def __init__(self):
pass
def start_browser(self, is_headless=False, is_cdp=False, is_dev=False, proxy=None, is_socks5=False, *args, **kwargs):
"""
启动浏览器。
Args:
is_headless (bool, optional): 是否开启无头模式。默认为 False。
is_cdp (bool, optional): 是否使用 Chrome Devtools Protocol。默认为 False。
is_dev (bool, optional): 是否启用调试模式。默认为 False。
proxy (str, optional): 代理设置。默认为 None。
is_socks5 (bool, optional): 是否使用 SOCKS5 代理。默认为 False。
*args, **kwargs: 其他参数。
Raises:
NotImplementedError: 派生类需要实现该方法。
"""
raise NotImplementedError
# 启动页面
def start_page(self, url):
raise NotImplementedError
# 显式等待
def wait_until_element(self, selector_location, timeout=None, selector_type=None):
raise NotImplementedError
# 等待时间
def wait_time(self, timeout):
raise NotImplementedError
# 等待时间
def wait_for_time(self, timeout):
raise NotImplementedError
# 查找多个元素
def find_elements(self, selector_location, selector_type=None):
raise NotImplementedError
# 查找元素
def find_element(self, selector_location, selector_type=None):
raise NotImplementedError
# 输入框 输入内容并提交
def send_keys(self, selector_location, input_content, selector_type=None):
raise NotImplementedError
# 执行js命令
def execute_script(self, script_command):
raise NotImplementedError
# 浏览器回退
def go_back(self):
raise NotImplementedError
# 浏览器前进
def go_forward(self):
raise NotImplementedError
# 获取cookies
def get_cookies(self):
raise NotImplementedError
# 添加cookies
def add_cookie(self, cookie):
raise NotImplementedError
# 删除cookies
def del_cookies(self):
raise NotImplementedError
# 切换选项卡
def switch_tab(self, tab_index):
raise NotImplementedError
# 刷新页面
def reload_page(self):
raise NotImplementedError
# 截图
def screen_page(self, file_name=None):
raise NotImplementedError
# 关闭浏览器
def close_browser(self):
raise NotImplementedError
# 获取页面内容
def get_content(self):
raise NotImplementedError
# 点击
def click(self, selector_location, selector_type=None):
raise NotImplementedError
# 拉拽动作
def drag_and_drop(self, source_element, target_element):
raise NotImplementedError
# 拉拽动作
def to_iframe(self, frame):
raise NotImplementedError
Selenium是一个自动化测试工具,利用它可以驱动浏览器完成特定操作,还可以获取浏览器当前呈现的页面的源代码,做到所见即所爬 对一些JavaScript动态渲染的页面来说,这种爬取方式非常有效使用Selenium驱动浏览器加载网页,可以直接拿到JavaScript渲染的结果
下面是封装的类
class SeleniumSimulate(BrowserSimulateBase):
def __init__(self):
self.browser = None
# 启动浏览器
# is_headless 是否开启无头模式
# is_cdp 是否使用cdp (Chrome Devtools Protocol)
def start_browser(self, is_headless=False, is_cdp=False, is_dev=False, proxy=None, is_socks5=False, *args,
**kwargs) -> webdriver.Chrome:
"""
启动 Chrome 浏览器。
Args:
is_headless (bool, optional): 是否开启无头模式。默认为 False。
is_cdp (bool, optional): 是否使用 Chrome Devtools Protocol。默认为 False。
is_dev (bool, optional): 是否启用调试模式。默认为 False。
proxy (str, optional): 代理设置。默认为 None。
is_socks5 (bool, optional): 是否使用 SOCKS5 代理。默认为 False。
*args, **kwargs: 其他参数。
Returns:
webdriver.Chrome: 已启动的 Chrome 浏览器对象。
"""
option = ChromeOptions()
if is_headless:
option.add_argument('--headless')
elif is_cdp:
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
elif proxy:
if is_socks5:
option.add_argument('--proxy-server=socks5://' + proxy)
else:
option.add_argument('--proxy-server=http://' + proxy)
self.browser = webdriver.Chrome(ChromeDriverManager().install(), options=option)
if is_cdp:
self.browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get:()=>undefined})'
})
self.browser.set_window_size(WINDOW_WIDTH, WINDOW_HEIGHT)
return self.browser
# 启动页面
def start_page(self, url):
"""
在浏览器中打开指定的 URL。
参数:
url (str): 要打开的网址。
无返回值。
"""
self.browser.get(url)
# 显式等待
# timeout等待的最长时间
def wait_until_element(self, selector_location, timeout=None, selector_type=None):
"""
等待指定的元素出现在页面中。
参数:
selector_location (str): 要等待的元素选择器。
timeout (int, optional): 等待的最大时间(秒)。如果未提供,将使用默认超时时间。
selector_type (str, optional): 选择器类型(例如 'css', 'xpath' 等)。
无返回值。
"""
wait = WebDriverWait(self.browser, timeout)
if selector_type:
selector_type = self.get_selector_type(selector_type)
else:
selector_type = self.get_selector_type(identify_selector_type(selector_location))
selector_location = extract_value_from_selector(selector_location)
wait.until(EC.presence_of_element_located((selector_type, selector_location)))
# 获取定位类型
def get_selector_type(self, selector_type):
"""
将自定义的选择器类型映射为Selenium的选择器类型。
参数:
selector_type (str): 自定义的选择器类型(例如 'css', 'xpath' 等)。
返回:
by_type (selenium.webdriver.common.by.By): Selenium的选择器类型。
"""
selector_type = selector_type.lower()
if selector_type == ID:
by_type = By.ID
elif selector_type == XPATH:
by_type = By.XPATH
elif selector_type == LINK_TEXT:
by_type = By.LINK_TEXT
elif selector_type == PARTIAL_LINK_TEXT:
by_type = By.PARTIAL_LINK_TEXT
elif selector_type == NAME:
by_type = By.NAME
elif selector_type == TAG_NAME:
by_type = By.TAG_NAME
elif selector_type == CLASS_NAME:
by_type = By.CLASS_NAME
elif selector_type == CSS_SELECTOR:
by_type = By.CSS_SELECTOR
return by_type
# 等待时间
def wait_for_time(self, timeout):
"""
异步等待指定的时间(秒)。
参数:
timeout (int): 等待的时间(秒)。
无返回值。
"""
time.sleep(timeout)
# 查找多个元素
def find_elements(self, selector_location, selector_type=None):
# 传了selector_type就获取 没传就通过selector_location进行解析
"""
查找多个元素。
参数:
selector_location (str): 要查找的元素选择器。
selector_type (str, optional): 选择器类型(例如 'css', 'xpath' 等)。
返回:
elements (list): 包含匹配元素的列表。
"""
if selector_type:
selector_type = self.get_selector_type(selector_type)
else:
selector_type = self.get_selector_type(identify_selector_type(selector_location))
selector_location = extract_value_from_selector(selector_location)
return self.browser.find_elements(selector_type, selector_location)
# 查找元素
def find_element(self, selector_location, selector_type=None):
"""
查找单个元素。
参数:
selector_location (str): 要查找的元素选择器。
selector_type (str, optional): 选择器类型(例如 'css', 'xpath' 等)。
返回:
element (WebElement): 匹配的元素。
"""
try:
if selector_type:
by_type = self.get_selector_type(selector_type)
else:
by_type = self.get_selector_type(identify_selector_type(selector_location))
selector_location = extract_value_from_selector(selector_location)
element = self.browser.find_element(by_type, selector_location)
return element
except NoSuchElementException:
# 处理元素未找到的情况
print(f"未找到匹配的元素: {selector_location}")
return None # 或者你可以选择抛出自定义的异常,或者返回其他默认值
# 输入框 输入内容并提交
def send_keys(self, selector_location, input_content, selector_type=None):
"""
在指定的选择器位置输入文本内容。
参数:
selector_location (str): 要输入文本的元素选择器。
input_content (str): 要输入的文本内容。
selector_type (str, optional): 选择器类型(例如 'css', 'xpath' 等)。
无返回值。
"""
input_element = self.find_element(selector_location, selector_type) # 查找输入框元素
if input_element:
input_element.send_keys(input_content) # 输入文本内容
else:
print(f"未找到元素: {selector_location}")
# 执行js命令
def execute_script(self, script_command):
"""
在当前页面上执行 JavaScript 脚本。
参数:
script_command (str): 要执行的 JavaScript 脚本命令。
无返回值。
"""
self.browser.execute_script(script_command)
# 浏览器回退
def go_back(self):
"""
在浏览器中回退到上一个页面。
无返回值。
"""
self.browser.back()
# 浏览器前进
def go_forward(self):
"""
在浏览器中执行前进操作,前往下一页。
无返回值。
"""
self.browser.forward()
# 获取cookies
def get_cookies(self):
"""
获取当前页面的所有 Cookies。
返回:
cookies (List): 包含所有 Cookies 的列表。
"""
return self.browser.get_cookies()
# 添加cookies
def add_cookie(self, cookie):
"""
向当前页面添加一个 Cookie。
参数:
cookie (dict): 要添加的 Cookie 对象,应包含 'name' 和 'value' 属性。
无返回值。
"""
self.browser.add_cookie(cookie)
# 删除cookies
def del_cookies(self):
"""
删除当前页面的所有 Cookies。
无返回值。
"""
self.browser.delete_all_cookies()
# 切换选项卡
def switch_tab(self, tab_index):
"""
在浏览器窗口中切换到指定的标签页。
参数:
tab (int): 要切换到的标签页的索引号。
无返回值。
"""
self.browser.switch_to.window(self.browser.window_handles[tab_index])
# 刷新页面
def reload_page(self):
"""
重新加载当前页面。
无返回值。
"""
self.browser.reload()
# 截图
def screen_page(self, file_path=None):
"""
截取当前页面的屏幕截图并保存到指定路径。
参数:
file_path (str, optional): 保存截图的文件路径。如果未提供,将保存为默认文件名(当前目录下的'screenshot.png')。
无返回值。
"""
# 如果未提供文件路径,默认保存为'screenshot.png'在当前目录下
if not file_path:
file_path = 'screenshot.png'
# 获取文件扩展名
file_extension = os.path.splitext(file_path)[1][1:]
# 如果不是png格式,转换成png
if file_extension != 'png':
file_path = os.path.splitext(file_path)[0] + '.png'
# 截取屏幕截图并保存
self.browser.save_screenshot(file_path)
# 关闭浏览器
def close_browser(self):
"""
关闭浏览器。
无返回值。
"""
self.browser.close()
def click(self, selector_location, selector_type=None):
"""
在页面上点击指定的元素。
参数:
selector_location (str): 要点击的元素选择器。
selector_type (str, optional): 选择器类型(例如 'css', 'xpath' 等)。
无返回值。
"""
element = self.find_element(selector_location, selector_type) # 查找要点击的元素
if element:
element.click() # 点击元素
else:
print(f"未找到元素: {selector_location}")
# 拉拽动作
def drag_and_drop(self, source_element, target_element):
"""
在页面上执行拖拽动作。
参数:
source_element (WebElement): 要拖拽的源元素。
target_element (WebElement): 拖拽的目标元素。
无返回值。
"""
actions = ActionChains(self.browser) # 创建动作链对象
actions.drag_and_drop(source_element, target_element) # 执行拖拽操作
actions.perform() # 执行动作链中的所有动作
self.browser.switch_to.alert.accept() # 处理可能出现的弹窗(假设拖拽操作可能触发了弹窗)
# iframe
def to_iframe(self, frame):
"""
切换到指定的 iframe。
参数:
frame (str or WebElement): 要切换的 iframe 元素或者 iframe 的名称或 ID。
无返回值。
"""
self.browser.switch_to.frame(frame)
# 获取页面内容
def get_content(self):
"""
获取当前页面的内容。
返回:
content (str): 当前页面的 HTML 内容。
"""
return self.browser.page_source
selenium_simulate = SeleniumSimulate()
其中用到的工具类如下
# 获取选择器属性
def identify_selector_type(selector):
if re.match(r'^#[\w-]+$', selector):
return 'id'
elif re.match(r'^[.\w-]+[\w-]*$', selector):
return 'css'
elif re.match(r'^(//.*|\(//.*|\*\[contains\(.*\)\]|\*\[@id=\'.*\'\])', selector):
return 'xpath'
elif re.match(r'^<[\w-]+>$', selector):
return 'tag'
elif re.match(r'^<a.*>.*</a>$', selector):
return 'link'
elif re.match(r'.*<a.*>.*</a>.*', selector):
return 'partial link'
elif re.match(r'^\[name=[\'\"].*[\'\"]\]$', selector):
return 'name'
elif re.match(r'^\[class=[\'\"].*[\'\"]\]$', selector):
return 'class'
else:
return 'unknown'
# 获取选择器内容
def extract_value_from_selector(selector):
match = re.match(r'^#([\w-]+)$', selector)
if match:
return match.group(1)
match = re.match(r'^\.([\w-]+[\w-]*)$', selector)
if match:
return match.group(1)
match = re.match(r'^(//.*|\(//.*|\*\[contains\((.*)\)\]|\*\[@id=\'(.*)\'\])', selector)
if match:
return match.group(1)
match = re.match(r'^<([\w-]+)>$', selector)
if match:
return match.group(1)
match = re.match(r'^<a.*>(.*)</a>$', selector)
if match:
return match.group(1)
match = re.match(r'.*<a.*>(.*)</a>.*', selector)
if match:
return match.group(1)
match = re.match(r'^\[name=[\'\"](.*)[\'\"]\]$', selector)
if match:
return match.group(1)
match = re.match(r'^\[class=[\'\"](.*)[\'\"]\]$', selector)
if match:
return match.group(1)
return None