Python网络爬虫
- 一、Scrapy 深入
- 案例 - qd_09_diaoyu
- items.py
- middlewares.py
- piplines.py
- settings.py
- spiders
- diaoyu.py
- diaoyu_manyitem.py
- 案例 - qd_10_liangli
- items.py
- middlewares.py
- pipelines.py
- settings.py
- spiders
- liangli.py
- liangli_extend.py
- 案例 - qd_11_duitang
- items.py
- middlewares.py
- pipelines.py
- settings.py
- spiders
- duitang.py
- 二、摘要数据
- 案例 - qd_12_douyu
- items.py
- middlewares.py
- pipelines.py
- settings.py
- spiders
- douyu.py
- 三、 CrawlSpider全栈爬取
- 1. 创建 CrawlSpider
- 2. LinkExtractors
- 3. Rule
- 4. settings.py
- 5. items.py
- 6. spider
- 7. pipelines.py
- 案例 - 快代理
- setting.py
- spiders
- kuai.py
- 案例 - 阳光热线问政平台
- settings.py
- items.py
- spiders
- sun.py
- 案例 - qd_13_zzzj
- items.py
- middlewares.py
- pipelines.py
- spiders
- zzzj.py
- 案例 - qd_14_jianfei
- items.py
- middlewares.py
- pipelines.py
- settings.py
- spiders
- jianfei.py
一、Scrapy 深入
案例 - qd_09_diaoyu
items.py
python">import scrapy
class Qd08DiaoyuItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
info = scrapy.Field()
class Qd08DiaoyuItem_2(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
info = scrapy.Field()
stars = scrapy.Field() # 新增字段
middlewares.py
python">from scrapy import signals
from itemadapter import is_item, ItemAdapter
class Qd08DiaoyuSpiderMiddleware:
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
return None
def process_spider_output(self, response, result, spider):
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
pass
def process_start_requests(self, start_requests, spider):
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
class Qd08DiaoyuDownloaderMiddleware:
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
piplines.py
python">import csv
import json
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from .items import Qd08DiaoyuItem, Qd08DiaoyuItem_2
# class Qd08DiaoyuPipeline:
# def process_item(self, item, spider):
# return item
''' 保存csv数据 '''
class CsvPipeline:
# 初始化函数可以用, 但是不建议
# def __init__(self):
# pass
"""
以下函数中 spider 参数是爬虫对象
可以区分爬虫文件执行代码
"""
def open_spider(self, spider):
"""在项目启动的时候会自动调用此函数, 只调用一次, 用此函数打开文件, 或者连接数据库"""
if spider.name == 'diaoyu1':
self.f = open('钓鱼.csv', mode='a', encoding='utf-8', newline='')
self.csv_write = csv.DictWriter(self.f, fieldnames=['title', 'author', 'info'])
self.csv_write.writeheader() # 写入表头, 只要写一次
def process_item(self, item, spider):
"""
process_item 主要处理返回过来的item, 返回多少item数据, 此函数就会被执行多少次
:param item: 返回的一条一条数据
:param spider: 爬虫对象
:return: 数据传过来是什么样子, 咱们就原路返回, 便于给其他管道类使用
"""
if spider.name == 'diaoyu1':
self.csv_write.writerow(item) # 将item数据一条一条保存
# 使用过后的item需要return原路返回, 便于给其他管道类使用
return item
def close_spider(self, spider):
"""在scrapy项目停止前会调用的函数, 一般用于文件关闭, 或者断开数据库连接"""
if spider.name == 'diaoyu1':
self.f.close() # 关闭文件
''' 保存json数据 '''
class JsonPipeline:
def open_spider(self, spider):
self.f = open('钓鱼.json', mode='w', encoding='utf-8')
self.data_list = [] # 定义一个空列表, 收集所有item数据到列表
def process_item(self, item, spider): # [{}, {}, {}]
d = dict(item)
self.data_list.append(d)
return item
def close_spider(self, spider):
# json序列化
json_str = json.dumps(self.data_list, ensure_ascii=False)
self.f.write(json_str)
self.f.close()
"""
注意点:
在当前类中的函数名都不能改, 不能错, 参数都不能少
所有的数据保存逻辑都是在 pipelines.py
"""
class ManyItemPipeline:
def open_spider(self, spider):
self.f = open('钓鱼1.csv', mode='a', encoding='utf-8', newline='')
self.csv_write = csv.DictWriter(self.f, fieldnames=['title', 'author', 'info'])
self.csv_write.writeheader()
self.f_2 = open('钓鱼2.csv', mode='a', encoding='utf-8', newline='')
self.csv_write_2 = csv.DictWriter(self.f_2, fieldnames=['title', 'author', 'info', 'stars'])
self.csv_write_2.writeheader()
def process_item(self, item, spider):
# isinstance 判断量个对象是不是同一对象
if isinstance(item, Qd08DiaoyuItem):
self.csv_write.writerow(item)
elif isinstance(item, Qd08DiaoyuItem_2):
self.csv_write_2.writerow(item)
return item
def close_spider(self, spider):
self.f.close()
self.f_2.close()
settings.py
python">BOT_NAME = "qd_08_diaoyu"
SPIDER_MODULES = ["qd_08_diaoyu.spiders"]
NEWSPIDER_MODULE = "qd_08_diaoyu.spiders"
ROBOTSTXT_OBEY = False
# 核心代码
ITEM_PIPELINES = {
"qd_08_diaoyu.pipelines.CsvPipeline": 300,
"qd_08_diaoyu.pipelines.JsonPipeline": 299,
"qd_08_diaoyu.pipelines.ManyItemPipeline": 298,
}
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
spiders
diaoyu.py
python">import scrapy
from ..items import Qd08DiaoyuItem
class DiaoyuSpider(scrapy.Spider):
name = "diaoyu"
allowed_domains = ["diaoyu.com"]
start_urls = ["https://www.diaoyu.com/jiqiao/"]
def parse(self, response):
# print(response.text)
lis = response.css('.article-list>li')
for li in lis:
title = li.css('dt>a::text').get()
author = li.css('.username::text').get()
info = li.css('.article-intro::text').get().replace('\n', '')
yield Qd08DiaoyuItem(title=title, author=author, info=info)
diaoyu_manyitem.py
python">import scrapy
from ..items import Qd08DiaoyuItem, Qd08DiaoyuItem_2
class DiaoyuManyitemSpider(scrapy.Spider):
name = "diaoyu_manyitem"
allowed_domains = ["diaoyu.com"]
start_urls = ["https://www.diaoyu.com/jiqiao/"]
def parse(self, response):
# print(response.text)
lis = response.css('.article-list>li')
for li in lis:
title = li.css('dt>a::text').get() # 标题
author = li.css('.username::text').get() # 作者
info = li.css('.article-intro::text').get().replace('\n', '') # 简介
yield Qd08DiaoyuItem(title=title, author=author, info=info)
# 新增一个字段
stars = li.css('.praise-number::text').get() # 点赞数
yield Qd08DiaoyuItem_2(title=title, author=author, info=info, stars=stars)
案例 - qd_10_liangli
items.py
python">import scrapy
class Qd09LiangliItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
urls = scrapy.Field()
middlewares.py
python">from scrapy import signals
from itemadapter import is_item, ItemAdapter
class Qd09LiangliSpiderMiddleware:
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
return None
def process_spider_output(self, response, result, spider):
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
pass
def process_start_requests(self, start_requests, spider):
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
class Qd09LiangliDownloaderMiddleware:
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
pipelines.py
python">import os.path
import scrapy
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from scrapy.pipelines.images import ImagesPipeline
# class Qd09LiangliPipeline:
# def process_item(self, item, spider):
# return item
# class DownLoadPicture(ImagesPipeline):
# # 在此函数中构建的请求体对象会默认的根据地址下载数据
# def get_media_requests(self, item, info):
# img_url = item['urls'] # 取出地址
# yield scrapy.Request(url=img_url)
class DownLoadPicture(ImagesPipeline):
def get_media_requests(self, item, info):
for img_url in item['urls']:
yield scrapy.Request(url=img_url, meta={'title': item['title']})
def file_path(self, request, response=None, info=None, *, item=None):
# 获取上个函数中传下来的标题
dir_name = request.meta.get('title')
# 根据请求体对象中的地址, 自定义图片名字
file_name = request.url.split('/')[-1]
# 返回文件路径
# return dir_name + '/' + file_name
return os.path.join(dir_name, file_name) # 构造路径
settings.py
python">BOT_NAME = "qd_09_liangli"
SPIDER_MODULES = ["qd_09_liangli.spiders"]
NEWSPIDER_MODULE = "qd_09_liangli.spiders"
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
"qd_09_liangli.pipelines.DownLoadPicture": 300,
}
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
# 定义保存图片的路径
IMAGES_STORE = './img' # 会自动创建文件夹
spiders
liangli.py
python">import scrapy
from ..items import Qd09LiangliItem
class LiangliSpider(scrapy.Spider):
name = "liangli"
allowed_domains = ["hexuexiao.cn"]
start_urls = ["https://www.hexuexiao.cn/a/124672.html"]
def parse(self, response):
# print(response.text)
title = response.css('h1::text').re('[\u4e00-\u9fa5]+')[0]
urls = response.css('a.btn::attr(href)').get()
# print(title)
# print(urls)
item = Qd09LiangliItem(title=title, urls=urls)
yield item
# 如果获取下一页是是当前图集, 那么得到的是部分地址
# 如果获取下一页是是新的图集, 那么得到的是完整地址
next = response.css('.next_main_img::attr(href)').get()
if not 'https' in next: # 满足此条件代表获取的是部分链接地址
all_url = 'https://www.hexuexiao.cn' + next # 拼接完整地址
yield scrapy.Request(url=all_url, callback=self.parse)
else: # 是一个新的图集
yield scrapy.Request(url=next, callback=self.parse)
liangli_extend.py
python">import scrapy
from ..items import Qd09LiangliItem
class LiangliExtendSpider(scrapy.Spider):
name = "liangli_extend"
allowed_domains = ["hexuexiao.cn"]
start_urls = ["https://www.hexuexiao.cn/a/124672.html"]
def parse(self, response):
title = response.css('h1::text').re('[\u4e00-\u9fa5]+')[0]
# 同一个图集中的地址放到列表中
urls = response.css('a.btn::attr(href)').getall()
item = Qd09LiangliItem(title=title, urls=urls)
# yield item # 先不返回item, 因为要收集所有图集的图片地址
next = response.css('.next_main_img::attr(href)').get()
if not 'https' in next:
all_url = 'https://www.hexuexiao.cn' + next # 拼接完整地址
yield scrapy.Request(url=all_url, callback=self.parse_1, meta={'item': item})
else:
yield scrapy.Request(url=next, callback=self.parse_1, meta={'item': item})
def parse_1(self, response): # 有多个解析函数, 一定要加response参数
item = response.meta.get('item') # 获取上一个函数的item
# 解析下一次请求的数据
title = response.css('h1::text').re('[\u4e00-\u9fa5]+')[0]
if title != item['title']: # 满足此条件代表获取的是一个新的图集数据
# 当你提取到的这一页 title, 不等于上一页的title
# 意味着title发生了改变, 一个新的系列的图片就产生了
yield item # 返回数据的唯一出口
urls = response.css('a.btn::attr(href)').getall() # 下一个系列的图片地址
item = Qd09LiangliItem(title=title, urls=urls)
next = response.css('.next_main_img::attr(href)').get()
if not 'https' in next:
all_url = 'https://www.hexuexiao.cn' + next # 拼接完整地址
yield scrapy.Request(url=all_url, callback=self.parse_1, meta={'item': item})
else:
yield scrapy.Request(url=next, callback=self.parse_1, meta={'item': item})
else:
# 不满足if条件, 代表这个图集的图片地址还没有收集完
urls = response.css('a.btn::attr(href)').getall()
item['urls'].extend(urls) # 合并列表, 将一个系列的图片地址收集起来
next = response.css('.next_main_img::attr(href)').get()
if not 'https' in next:
all_url = 'https://www.hexuexiao.cn' + next # 拼接完整地址
yield scrapy.Request(url=all_url, callback=self.parse_1, meta={'item': item})
else:
yield scrapy.Request(url=next, callback=self.parse_1, meta={'item': item})
案例 - qd_11_duitang
items.py
python">import scrapy
class Qd10DuitangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
path = scrapy.Field()
username = scrapy.Field()
like_count = scrapy.Field()
favorite_count = scrapy.Field()
middlewares.py
python">from scrapy import signals
from itemadapter import is_item, ItemAdapter
class Qd10DuitangSpiderMiddleware:
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
return None
def process_spider_output(self, response, result, spider):
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
pass
def process_start_requests(self, start_requests, spider):
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
class Qd10DuitangDownloaderMiddleware:
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
pipelines.py
python">import csv
import scrapy
from itemadapter import ItemAdapter
from scrapy.pipelines.images import ImagesPipeline
# class Qd10DuitangPipeline:
# def process_item(self, item, spider):
# return item
class CsvPipeline:
def open_spider(self, spider):
self.f = open('蜡笔小星.csv', mode='a', encoding='utf-8', newline='')
self.write = csv.DictWriter(self.f, fieldnames=['username', 'favorite_count', 'like_count', 'path'])
self.write.writeheader()
def process_item(self, item, spider):
self.write.writerow(item)
return item
def close_spider(self, spider):
self.f.close()
class DownLoadPicture(ImagesPipeline):
def get_media_requests(self, item, info):
img_url = item['path'] # [地址1, 地址2,.....]
yield scrapy.Request(url=img_url)
def file_path(self, request, response=None, info=None, *, item=None):
fimename = request.url.split('/')[-1]
return fimename
settings.py
python">BOT_NAME = "qd_10_duitang"
SPIDER_MODULES = ["qd_10_duitang.spiders"]
NEWSPIDER_MODULE = "qd_10_duitang.spiders"
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
"qd_10_duitang.pipelines.CsvPipeline": 300,
"qd_10_duitang.pipelines.DownLoadPicture": 301,
}
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
IMAGES_STORE = './IMG' # 设置图片保存路径
spiders
duitang.py
python">import scrapy
from ..items import Qd10DuitangItem
class DuitangSpider(scrapy.Spider):
name = "duitang"
allowed_domains = ["duitang.com"]
start_urls = [
f"https://www.duitang.com/napi/blogv2/list/by_search/?kw=%E8%9C%A1%E7%AC%94%E5%B0%8F%E6%98%9F&after_id={page * 24}&type=feed&include_fields=top_comments%2Cis_root%2Csource_link%2Citem%2Cbuyable%2Croot_id%2Cstatus%2Clike_count%2Clike_id%2Csender%2Calbum%2Creply_count%2Cfavorite_blog_id&_type=&_=1690544125042"
for page in range(10)]
def parse(self, response):
# print(response.json())
json_data = response.json()
data_list = json_data['data']['object_list']
for data in data_list:
path = data['photo']['path']
username = data['sender']['username']
like_count = data['like_count']
favorite_count = data['favorite_count']
yield Qd10DuitangItem(path=path, username=username, like_count=like_count, favorite_count=favorite_count)
# path(图片地址)
# username(上传作者)
# like_count(点赞数)
# favorite_count(收藏数)
二、摘要数据
python"># item --> 字典对象, 相对字符串占用空间要多
none_list = []
d1 = {'name': '张三', 'age': 17, 'hobby': '吃'}
none_list.append(d1)
print(none_list)
import hashlib # 内置模块
import json
# 涉及到数据加密, 都是将二进制数据加密
none_list = []
d1 = {'name': '张三', 'age': 17, 'hobby': '吃'}
d3 = {'name': '张三', 'age': 17, 'hobby': '吃'}
d2 = {'name': '李四', 'age': 17, 'hobby': '喝'}
# 字符串转二进制
str1 = json.dumps(d1).encode()
print(str1)
obj = hashlib.md5() # 实例对象
obj.update(str1) # 将二进制数据存储进去
print(obj.hexdigest()) # 摘要后的数据 32 位的长度
none_list.append(obj.hexdigest()) # 添加到空列表里面去
print(none_list)
str2 = json.dumps(d3).encode()
print(str2)
obj = hashlib.md5() # 实例对象
obj.update(str2) #
print(obj.hexdigest())
if obj.hexdigest() not in none_list:
none_list.append(obj.hexdigest())
print(none_list)
d2 = {'name': '李四', 'age': 17, 'hobby': '喝'}
print(hashlib.md5(json.dumps(d2).encode()).hexdigest()) # 链式方式
案例 - qd_12_douyu
items.py
python">import scrapy
class Qd11DouyuItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
anchor_name = scrapy.Field() # 主播名字
room_name = scrapy.Field() # 直播间名字
anchor_kind = scrapy.Field() # 分类
anchor_hot = scrapy.Field() # 热度
middlewares.py
python">from scrapy import signals
from itemadapter import is_item, ItemAdapter
class Qd11DouyuSpiderMiddleware:
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
return None
def process_spider_output(self, response, result, spider):
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
pass
def process_start_requests(self, start_requests, spider):
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
class Qd11DouyuDownloaderMiddleware:
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
pipelines.py
python">import csv
import hashlib
import json
from itemadapter import ItemAdapter
class CsvPipeline:
def open_spider(self, spider):
self.f = open('斗鱼.csv', mode='a', encoding='utf-8', newline='')
self.write = csv.DictWriter(self.f, fieldnames=['anchor_name', 'room_name', 'anchor_kind', 'anchor_hot'])
self.write.writeheader()
self.filter_list = [] # 用于去重数据的空列表
def process_item(self, item, spider):
"""
数据去重
"""
# 方法1: 筛选结果 - 有缺陷
# 会随着数据越多, 导致列表存储的空间就越大, 判断的效率就越低
if item not in self.filter_list: # 如果数据没有在空列表,是第一次出现
self.write.writerow(item)
self.filter_list.append(item) # 保存完数据后将第一次出现的数据加入空列表
return item
# 方法2: 数据摘要 - 摘要算法
# 占用的存储空间更小, 在数据量多的情况下, 效率更高
d = dict(item)
result = hashlib.md5(json.dumps(d).encode()).hexdigest()
if result not in self.filter_list:
self.write.writerow(item)
self.filter_list.append(result) # 添加摘要的结果到空列表
return item
self.write.writerow(item)
return item
def close_spider(self, spider):
print('摘要结果的列表:', self.filter_list)
self.f.close()
settings.py
python">BOT_NAME = "qd_11_douyu"
SPIDER_MODULES = ["qd_11_douyu.spiders"]
NEWSPIDER_MODULE = "qd_11_douyu.spiders"
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
"qd_11_douyu.pipelines.CsvPipeline": 300,
}
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
spiders
douyu.py
python">import scrapy
from ..items import Qd11DouyuItem
class DouyuSpider(scrapy.Spider):
name = "douyu"
allowed_domains = ["douyu.com"]
start_urls = ["https://www.douyu.com/gapi/rkc/directory/mixList/2_181/2"]
def start_requests(self):
# 构建两次相同的请求体
# 在scrapy框架中相同的请求会被自动过滤
# dont_filter=True 不过滤请求
yield scrapy.Request(url="https://www.douyu.com/gapi/rkc/directory/mixList/2_181/2",
callback=self.parse,
dont_filter=True)
yield scrapy.Request(url="https://www.douyu.com/gapi/rkc/directory/mixList/2_181/2",
callback=self.parse,
dont_filter=True)
def parse(self, response):
# print(response.json())
json_data = response.json()
data_list = json_data['data']['rl']
for data in data_list:
anchor_name = data['nn'] # 主播名字
room_name = data['rn'] # 直播间名字
anchor_kind = data['c2name'] # 分类
anchor_hot = data['ol'] # 热度
item = Qd11DouyuItem(anchor_name=anchor_name, room_name=room_name,
anchor_kind=anchor_kind, anchor_hot=anchor_hot)
print(item)
# 多次yield,那么管道也会处理多次, 模拟重复数据
yield item
yield item
"""
指纹过滤器缺点:
每一次请求都会记录指纹, 数据在200M以内, 用底层过滤对效率没什么影响
无法断点续爬: 从上次没有采集的地址, 采集后续地址
"""
三、 CrawlSpider全栈爬取
在 Scrapy 的基本使用当中,spider 如果要重新发送请求的话,就需要自己解析页面,然后发送请求。而 CrawlSpider 则可以通过设置 url 条件自动发送请求。
CrawlSpider 是 Spider 的一个派生类,相对于 Spider 来说,功能进行了更新,使用也更加方便。
实现网站的全站数据爬取
- 就是将网站中所有页码对应的页面数据进行爬取。
crawlspider 其实就是 scrapy 封装好的一个爬虫类,通过该类提供的相关的方法和属性就可以实现全新高效形式的全站数据爬取。
1. 创建 CrawlSpider
和之前创建 spider 一样,虽然可以在创建 Scrapy 项目之后手动构造 spider,但是 Scrapy 也给出了在终端下创建 CrawlSpider 的指令:
python">scrapy genspider 爬虫名字 域名限制 -t crawl
在终端中使用上边的指令就能够使用 Scrapy 中的模板创建 CrawlSpider。
2. LinkExtractors
CrawlSpider 与 spider 不同的是就在于下一次请求的 url 不需要自己手动解析,而这一点则是通过 LinkExtractors 实现的。LinkExtractors 原型为:
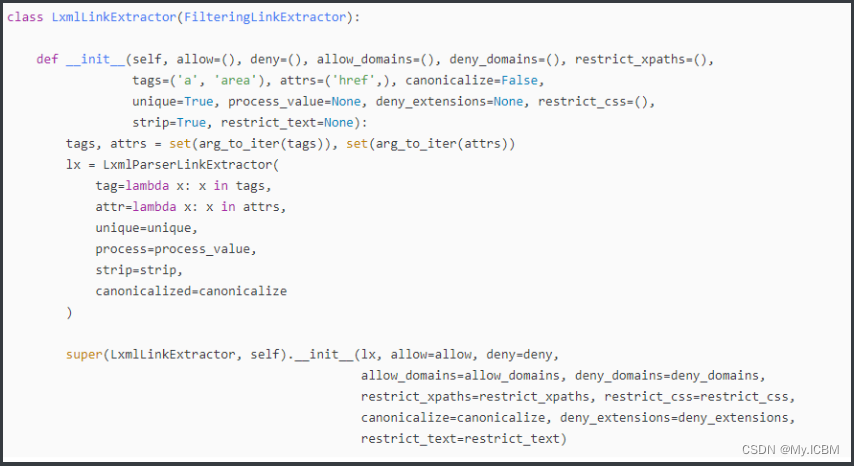
其中的参数为:
- allow:允许的 url。所有满足这个正则表达式的 url 都会被提取
- deny:禁止的 url。所有满足这个正则表达式的 url 都不会被提取
- allow_domains:允许的域名。只有在这个里面指定的域名的 url 才会被提取
- deny_domains:禁止的域名。所有在这个里面指定的域名的 url 都不会被提取
- restrict_xpaths:严格的 xpath 过滤规则。和 allow 共同过滤链接,优先级高
- restrict_css:严格的 css过滤规则。和 allow 共同过滤链接,优先级高
3. Rule
LinkExtractors 需要传递到 Rule 类对象中才能发挥作用。Rule 类为:
python">class Rule:
def __init__(self, link_extractor=None, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=None, errback=None):
self.link_extractor = link_extractor or _default_link_extractor
self.callback = callback
self.errback = errback
self.cb_kwargs = cb_kwargs or {}
self.process_links = process_links or _identity
self.process_request = process_request or _identity_process_request
self.process_request_argcount = None
self.follow = follow if follow is not None else not callback
常见的参数为:
- link_extractor:LinkExtractor 对象,用于定义爬取规则
- callback:对于满足该规则的 url 所要执行的回掉函数,类似于之前提到的 scrapy.Request() 中的callback。而 CrawlSpider 使用了 parse 作为回调函数,因此不要覆盖 parse 作为回调函数自己的回调函数
- follow:从 response 中提取的链接是否需要跟进
- process_links:从 link_extractor 中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接
除了上述的这些差别,Crawlspider 和 spider 基本没有什么差别了。
4. settings.py
仍旧需要设置:
- ROBOTSTXT_OBEY:设置为 False,否则为 True。True 表示遵守机器协议,此时爬虫会首先找 robots.txt 文件,如果找不到则会停止
- DEFAULT_REQUEST_HEADERS:默认请求头,可以在其中添加 User-Agent,表示该请求是从浏览器发出的,而不是爬虫
- DOWNLOAD_DELAY:表示下载的延迟,防止过快
- ITEM_PIPELINES:启用 pipelines.py
5. items.py
python">class Qd12ZzzjItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
url = scrapy.Field()
info = scrapy.Field()
img_url = scrapy.Field()
6. spider
python">class ZzzjSpider(CrawlSpider):
name = "zzzj"
allowed_domains = ["chinaz.com"]
start_urls = ['https://top.chinaz.com/hangyemap.html']
rules = (
Rule(LinkExtractor(allow=r'/hangye/index_.*?.html',
restrict_css=('.Taleft', '.Taright')
),
callback='parse_item', # callback回调, 传递回调函数名字的字符串形式
follow=True # 是否继续从响应内容里提取url链接, 是否需要跟进, 默认是跟进的
)
)
def parse_item(self, response):
print('response.url::', response.url)
# print(response.text)
lis = response.css('.listCentent li')
for li in lis:
title = li.css('.rightTxtHead a::text').get() # 网站名
url = li.css('.col-gray::text').get() # 网站url
info = li.css('.RtCInfo::text').get().strip() # 网站简介
img_url = li.css('.leftImg a img::attr(src)').get() # 网站图片地址
item = Qd12ZzzjItem(title=title, url=url, info=info, img_url=img_url)
yield item
# 提取下一页部分连接
next_page = response.css('.ListPageWrap a:last-of-type::attr(href)').get()
print('next_page:::', next_page)
if next_page:
# 注意拼接规则, 这里有狗
all_url = 'https://top.chinaz.com' + next_page
print('all_url: ', all_url)
yield scrapy.Request(all_url, callback=self.parse_item)
7. pipelines.py
python">class Qd12ZzzjPipeline:
def open_spider(self, spider):
self.f = open('站长之家.csv', mode='a', encoding='utf-8', newline='')
self.csv_write = csv.DictWriter(self.f, fieldnames=['title', 'url', 'info', 'img_url'])
self.csv_write.writeheader()
def process_item(self, item, spider):
d = dict(item)
self.csv_write.writerow(d)
return item
def close_spider(self, spider):
self.f.close()
在 CrawlSpider 中需要注意的就是 spider 的写法,别的和之前差不多。
案例 - 快代理
setting.py
python">BOT_NAME = "crawlPro"
SPIDER_MODULES = ["crawlPro.spiders"]
NEWSPIDER_MODULE = "crawlPro.spiders"
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
DOWNLOAD_DELAY = 1
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
spiders
kuai.py
python">import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class SunSpider(CrawlSpider):
name = "kuai"
# allowed_domains = ["www.xxx.com"]
start_urls = ["https://www.kuaidaili.com/free/inha/1/"]
# 链接提取器:可以根据指定规则(allow='正则表达式')进行链接url的提取
link = LinkExtractor(allow=r"free/inha/\d+/") # 在正则中遇到/ 需要在前面使用\进行转义
# 一个链接提取器一定对应一个规则解析器
# link = LinkExtractor(restrict_xpaths='//*[@id="list"]/div[4]/ul/li/a/@href')
rules = (
# 规则解析器:可以接收链接并且对其进行请求发送,然后给根据指定规则对请求到的数据进行数据解析
Rule(link, callback="parse_item", follow=True),
)
# 如何将一个网站中所有的深度链接都提取
def parse_item(self, response):
print(response)
tr_list = response.xpath('//*[@id="list"]/div[1]/table/tbody/tr')
for tr in tr_list:
ip = tr.xpath('./td[1]/text()').extract_first()
# detail_url = xxx
print(ip)
# yield scrapy.Request(detail_url, callback=self.parse)
#
# def parse(self, response):
# # 对详情页进行数据解析
# pass
案例 - 阳光热线问政平台
settings.py
python">BOT_NAME = "sunPro"
SPIDER_MODULES = ["sunPro.spiders"]
NEWSPIDER_MODULE = "sunPro.spiders"
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
DOWNLOAD_DELAY = 1
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
items.py
python">class SunproItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
content = scrapy.Field()
pass
spiders
sun.py
python">import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import SunproItem
class SunSpider(CrawlSpider):
name = 'sun'
# allowed_domains = ['https://wz.sun0769.com']
start_urls = ['https://wz.sun0769.com/political/index/politicsNewest?id=1&page=1']
# 链接提取器和规则解析器一定是一对一关系
# 提取页码链接
link = LinkExtractor(allow=r'id=1&page=\d+')
rules = (
# 解析页面对应页面中的标题数据
Rule(link, callback='parse_item', follow=False),
)
# 解析方法的调用次数取决于link提取到的链接的个数
def parse_item(self, response):
li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')
for li in li_list:
title = li.xpath('./span[3]/a/text()').extract_first()
detail_url = 'https://wz.sun0769.com' + li.xpath('./span[3]/a/@href').extract_first()
item = SunproItem(title=title)
yield scrapy.Request(url=detail_url, callback=self.parse_detail, meta={'item': item})
def parse_detail(self, response):
item = response.meta['item']
detail_content = response.xpath('/html/body/div[3]/div[2]/div[2]/div[2]//text()').extract()
print(type(detail_content))
item['content'] = detail_content
# 报错信息 KeyError: 'SunproItem does not support field: content'
print(item, detail_content)
yield item
案例 - qd_13_zzzj
items.py
python">import scrapy
class Qd12ZzzjItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() # 网站名字
url = scrapy.Field() # 网站地址
rank = scrapy.Field() # 周排名
info = scrapy.Field() # 简介
img_url = scrapy.Field() # 图片地址
middlewares.py
python">from scrapy import signals
from itemadapter import is_item, ItemAdapter
class Qd12ZzzjSpiderMiddleware:
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
return None
def process_spider_output(self, response, result, spider):
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
pass
def process_start_requests(self, start_requests, spider):
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
class Qd12ZzzjDownloaderMiddleware:
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
pipelines.py
python">import csv
from itemadapter import ItemAdapter
''' 保存 csv 数据 '''
class CsvPipeline:
def open_spider(self, spider):
self.f = open('斗鱼.csv', mode='a', encoding='utf-8', newline='')
self.write = csv.DictWriter(self.f, fieldnames=['title', 'url', 'rank', 'info', 'img_url'])
self.write.writeheader()
def process_item(self, item, spider):
self.write.writerow(item)
return item
def close_spider(self, spider):
self.f.close()
spiders
zzzj.py
python">import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import Qd12ZzzjItem
# 使用CrawlSpider爬虫类
class ZzzjSpider(CrawlSpider):
page = 1 # 设置一个类属性, 限制抓取的链接数量
name = "zzzj"
allowed_domains = ["chinaz.com"]
# 根据一个网址, 爬取站点内所有数据
start_urls = ["https://top.chinaz.com/hangyemap.html"]
# rules 所有规则
rules = (
# """规则1"""
Rule(
# 限制器
# allow 根据正则表达式提取数据
LinkExtractor(
# allow 根据正则匹配片接
# 当解析的url地址是部分地址的时候, CrawlSpider 会自动拼接地址
allow=r"/hangye/index_.*?.html",
# 限制只在符合以下css规则的标签中提取链接, 优先级比 allow 高
restrict_css=('.Taleft', '.Taright')
),
callback="parse_item", # 提取的链接交给哪个函数处理? 指定函数名字的字符串
follow=True # 是否从响应内容中跟进继续提取符合要求的链接, 默认是跟进的
),
# """规则2"""
# Rule(
# # 限制器
# # allow根据正则表达式提取数据
# LinkExtractor(
# # allow 根据正则匹配片接
# # 当解析的url地址是部分地址的时候, CrawlSpider 会自动拼接地址
# allow=r"/hangye/index_.*?.html",
# # 限制只在符合以下css规则的标签中提取链接, 优先级比 allow 高
# restrict_css=('.Taleft', '.Taright')
# ),
#
# callback="parse_item", # 提取的链接交给哪个函数处理? 指定函数名字的字符串
# follow=True # 是否从响应内容中跟进继续提取符合要求的链接, 默认是跟进的
# )
)
def parse_item(self, response):
# item = {}
# #item["domain_id"] = response.xpath('//input[@id="sid"]/@value').get()
# #item["name"] = response.xpath('//div[@id="name"]').get()
# #item["description"] = response.xpath('//div[@id="description"]').get()
# return item
# print('提取的链接:', response.url)
lis = response.css('.listCentent>li')
for li in lis:
title = li.css('h3>a::text').get() # 网站名字
url = li.css('.col-gray::text').get() # 网站地址
rank = li.css('.RtCPart.clearfix>p:nth-child(1)>a::text').get() # 周排名
info = li.css('.RtCInfo::text').get() # 简介
img_url = li.css('.leftImg>a>img::attr(src)').get() # 图片地址
item = Qd12ZzzjItem(title=title, url=url, rank=rank,
info=info, img_url=img_url)
print(item)
yield item
"""翻页"""
# self.page
next = response.css('.ListPageWrap>a:last-of-type::attr(href)')
page = int(next.re('\d+')[0])
# print(next)
if page <= 2: # 抓取两页数据
all_url = 'https://top.chinaz.com' + next.get()
yield scrapy.Request(url=all_url, callback=self.parse_item)
案例 - qd_14_jianfei
items.py
python">import scrapy
class Qd13JianfeiItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() # 文章标题
put_time = scrapy.Field() # 发布时间
source = scrapy.Field() # 文章来源
lead = scrapy.Field() # 文章导语
middlewares.py
python">from scrapy import signals
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
class Qd13JianfeiSpiderMiddleware:
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
return None
def process_spider_output(self, response, result, spider):
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
pass
def process_start_requests(self, start_requests, spider):
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
class Qd13JianfeiDownloaderMiddleware:
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
pipelines.py
python">from itemadapter import ItemAdapter
class Qd13JianfeiPipeline:
def process_item(self, item, spider):
return item
settings.py
python">BOT_NAME = "qd_13_jianfei"
SPIDER_MODULES = ["qd_13_jianfei.spiders"]
NEWSPIDER_MODULE = "qd_13_jianfei.spiders"
ROBOTSTXT_OBEY = False
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
spiders
jianfei.py
python">import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule, Spider
from ..items import Qd13JianfeiItem
class JianfeiSpider(CrawlSpider):
name = "jianfei"
allowed_domains = ["99.com.cn"]
# 在start_urls中构建翻页规律
start_urls = ["https://jf.99.com.cn/jfqm/"]
# def start_requests(self):
# def parse(self, response):
# with open('a.html', mode='w', encoding='utf-8') as f:
# f.write(response.text)
rules = (
Rule(
LinkExtractor(allow=r"//jf.99.com.cn/jfqm/.*?.htm",
restrict_css=('.DlistWfc',),
# tags=('a',),
attrs=('href',)
), # 用Rule提取的链接会自动被请求
callback="parse_item", # 给字符串
follow=True
),
)
def parse_item(self, response):
# item = {}
# #item["domain_id"] = response.xpath('//input[@id="sid"]/@value').get()
# #item["name"] = response.xpath('//div[@id="name"]').get()
# #item["description"] = response.xpath('//div[@id="description"]').get()
# return item
# print(response.url)
"""提取数据"""
title = response.css('.title_box>h1::text').get() # 文章标题
put_time = response.css('.title_txt span::text').get() # 发布时间
source = response.css('.title_txt span:last-of-type::text').get() # 文章来源
lead = response.css('.profile_box>p::text').get() # 文章导语
print(Qd13JianfeiItem(title=title, put_time=put_time, source=source, lead=lead))
yield Qd13JianfeiItem(title=title, put_time=put_time, source=source, lead=lead)