爬虫详细教程第一天
1.爬虫概述
1.1什么是爬虫?
爬虫就是通过编写程序来爬取互联网上的优秀资源(图片、音频、视频、数据)
1.2爬虫工具——Python
Python上手速度最快,语法最简单。更重要的是,有非常多的关于爬虫功能的第三方支持库。
1.3爬虫合法吗?
但是爬虫不能影响网站的正常运营(抢票, 秒杀, 疯狂solo网站资源
造成网站宕机)。我们还是要安分守己。时常优化自己的爬虫程序
避免干扰网站的正常运行。并且在使用爬取到的数据时,发现涉及
对用户隐私和商业机密等敏感内容时,一定要及时终止爬取和传播
1.4爬虫的矛与盾
1.4.1反爬机制
网站可以通过制定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取。
1.4.2反爬策略
爬虫程序可以通过制定相关的策略或者技术手段,破解网站中配备的反爬机制,从而可以获取⻔户网站中相关的数据据。
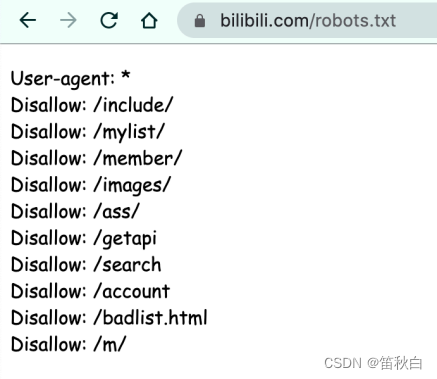
1.4.3robots.txt协议
robots.txt协议:规定了网站中哪些数据可以被爬虫爬取哪些数据不可以被爬取。
2.爬虫使用的软件
2.1使用的开发工具:
3.第一个爬虫
首先,回顾一下爬虫的概念. 爬虫就是我们通过我们写的程序去抓取互联网上的数据资源. 比如, 需要百度的资源.我们打开浏览器, 然后输入百度的网址,紧接着, 我们就能在浏览器上看到百度的内容了. 那换成爬虫呢? 其实道理是一样的. 只不过, 我们需要用代码来模拟一个浏览器, 然后同样的输入百度的网址. 那么我们的程序应该也能拿到百度的内容.
python">#在python中, 我们可以直接用urllib模块来完成对浏览器的模拟工作~,
from urllib.request import urlopen
resp = urlopen("http://www.baidu.com") # 打开百度
print(resp.read().decode("utf-8")) # 打印抓取到的内容
resp.close#关闭文档
我们可以把抓取到的html内容全部写入到文件中, 然后和原版的百度
进行对比, 看看是否一致
python">from urllib.request import urlopen
resp = urlopen("http://www.baidu.com") # 打开百度
#print(resp.read().decode("utf-8")) # 打印抓取到
的内容
with open("baidu.html",mode="w", encoding="utf-8") as f: # 创建文件
f.write(resp.read().decode("utf-8")) # 保存在文件中
resp.close#关闭文档
4.web请求
4.1讲解一下web请求的全部过程
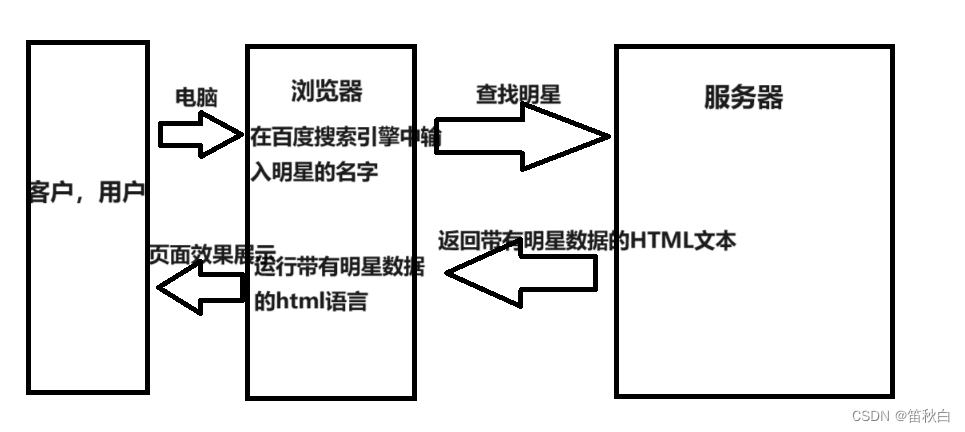
以百度为例. 在访问百度的时候, 浏览器会把这一次请求发送到百度的服务器(百度的一台电脑), 由服务器接收到这个请求, 然后加载一些数据. 返回给浏览器, 再由浏览器进行显示. 这里蕴含着一个极为重要的东⻄在里面, 注意, 百度的服务器返回给浏览器的不直接是⻚面, 而是⻚面源代码(由html, css, js组成). 由浏览器把⻚面源代码进行执行, 然后把执行之后的结果展示
给用户. 所以我们能看到页面的内容中,我们拿到的是百度的源代码具体过程如图.
4.2页面渲染数据
并非所有的数据都在⻚面源代码里,一个新的概念那就是⻚面渲染数据的过程, 我们常⻅的⻚面渲染过程有两种,
4.2.1. 服务器渲染
在请求到服务器的时候, 服务器直接把数据全部写入到html中, 我们浏览器就能直接拿到带有数据的html内容.
这种网⻚一般都相对比较容易就能抓取到⻚面内容.
4.2.2. 前端JS渲染
第一次请求服务器返回一堆HTML框架结构. 然后再次请求到真正保存数据的服务器, 由这个服务器返回数据, 最后在浏览器上对数据进行加载.
这样做的好处是服务器那边能缓解压力. 而且分工明确. 比较容
易维护.
那数据是何时加载进来的呢?
我们进行⻚面向下滚动的时候, jd就在偷偷的加载数据了, 此时想要看到这个⻚面的加载全过程, 我们就需要借助浏览器的调试工具了(F12)
5.HTTP协议
-
协议: 就是两个计算机之间为了能够流畅的进行沟通而设置的一个君子协定. 常⻅的协议有TCP/IP. SOAP协议, HTTP协议, SMTP协议等
-
HTTP协议, Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议. 就是浏览器和服务器之间的数据交互遵守的就是HTTP协议.
HTTP协议把一条消息分为三大块内容. 无论是请求还是响应都是三
块内容
5.1请求:
请求行 -> 请求方式(get/post) 请求url地址 协议
请求头 -> 放一些服务器要使用的附加信息
请求体 -> 一般放一些请求参数
5.2响应:
状态行 -> 协议 状态码
响应头 -> 放一些客户端要使用的一些附加信息
响应体 -> 服务器返回的真正客户端要用的内容(HTML,json)等
请求头中最常⻅的一些重要内容(爬虫需要):
- User-Agent : 请求载体的身份标识(用啥发送的请求)
- Referer: 防盗链(这次请求是从哪个⻚面来的? 反爬会用到)
- cookie: 本地字符串数据信息(用户登录信息, 反爬的token)
响应头中一些重要的内容:
cookie: 本地字符串数据信息(用户登录信息, 反爬的token)
5.3请求方式
- GET: 显示提交
- POST: 隐示提交
6.requests模块
常用的抓取⻚面的模块通常使用第三方模块requests.既然是第三方模块, 那就需要我们对该模块进行安装, 安装方法:
pip install requests
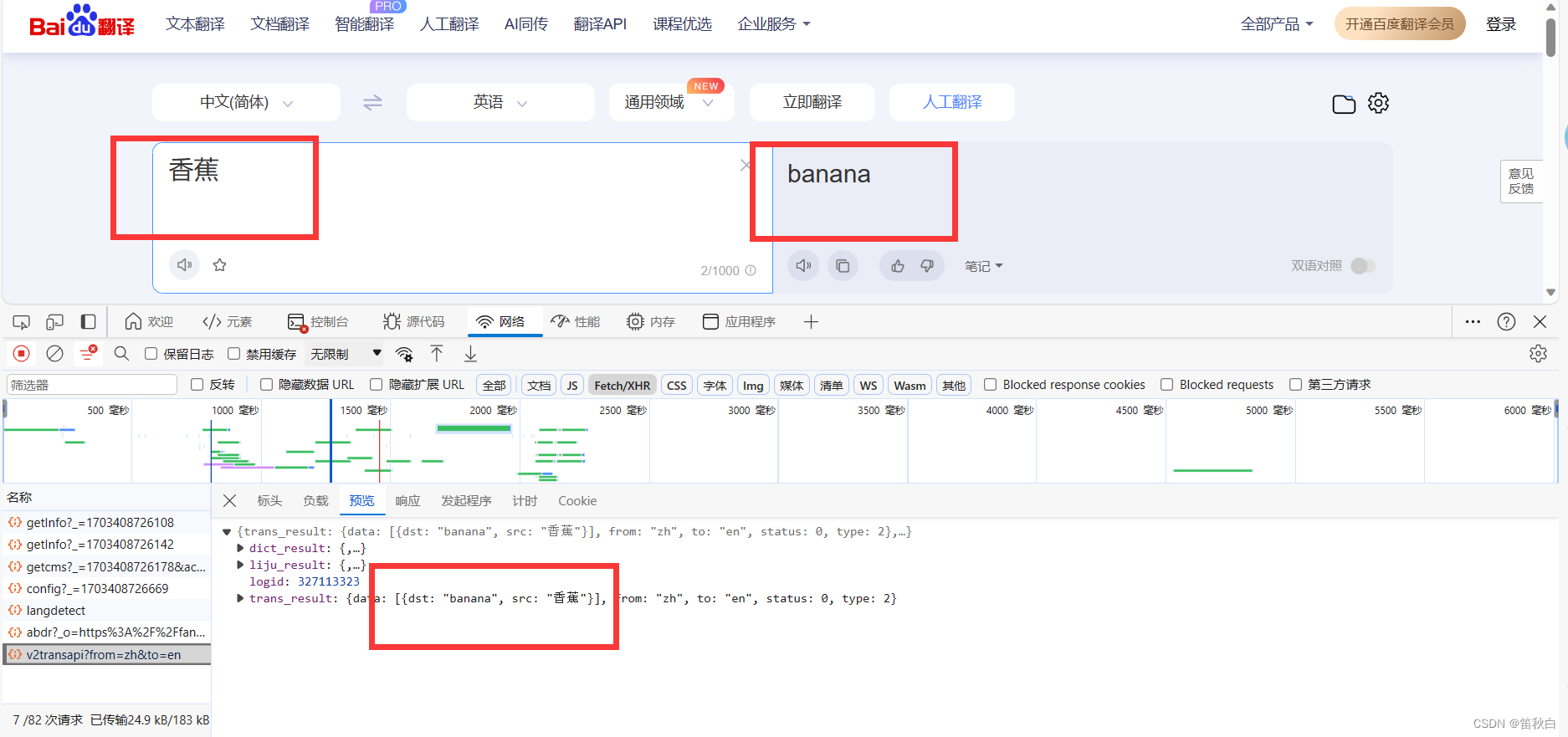
6.1. 抓取百度翻译数据
python">kw = input("请输入你要翻译的英语单词:")
dic = {
"kw": kw # 这里要和抓包工具里的参数一致.
}
resp =
requests.post("https://fanyi.baidu.com/sug",
data=dic)
#返回值是json 那就可以直接解析成json
resp_json = resp.json()
#{"errno': 0, 'data': [{'k': 'Apple', 'v': 'n.苹果公司,原称苹果电脑公司'....
print(resp_json['data'][ 0 ]['v']) # 拿到返回字典中的内容
resp.close
6.2: 抓取豆瓣电影
python">url = 'https://movie.douban.com/j/chart/top_list'
param = {
'type': '24',
'interval_id': '100:90',
'action':'',
'start': '0',#从库中的第几部电影去取
'limit': '20',#一次取出的个数
}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel
Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like
Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
response =
requests.get(url=url,params=param,headers=headers
)
list_data = response.json()
fp = open('./douban.json','w',encoding='utf-8')
json.dump(list_data,fp=fp,ensure_ascii=False)
print('over!!!')
response.close