1.前言
之前在异步加载(AJAX)网页爬虫的时候提到过,爬取这种ajax技术的网页有两种办法:一种就是通过浏览器审查元素找到包含所需信息网页的真实地址,另一种就是通过selenium模拟浏览器的方法[1]。当时爬的是豆瓣,比较容易分析出所需信息的真实地址,不过一般大点的网站像淘宝这种是不好分析的,所以利用selenium模拟浏览器的行为来爬取数据是一个比较可行的办法。
2.selenium基础
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11), Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。 ——百度百科对selenium的定义
可以看到selenium最开始不是用于爬虫的而是一款web开发的测试工具,简单点解释:可以操控浏览器做人类浏览网页的动作,比如:鼠标点击、拖拽;用户输入,表单填充;Cookie;等等,当然通过它得到ajax网页的真实数据也不在话下。
selenium教程:https://www.yiibai.com/selenium
3.安装selenium+Chromedriver
3.1 安装selenium
pip install selenium3.2 安装ChromeDriver
不要使用PhantomJS,已经停止维护。最新版的selenium也不再支持了,继续使用会报这个:Warning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead
谷粉当然选择Chrome了,Selenium可以操作浏览器,但是需要借助ChromeDriver驱动来实现。ChromeDriver通过chrome的自动代理框架控制浏览器。
①查看Chrome浏览器版本信息,点右上角三个白点,选择帮助,再选择关于Chrome就可以看到当前的Chrome版本信息。

77.0.3865.120就是当前的版本信息。
②再打开http://npm.taobao.org/mirrors/chromedriver/选择对应版本的Chromedriver。
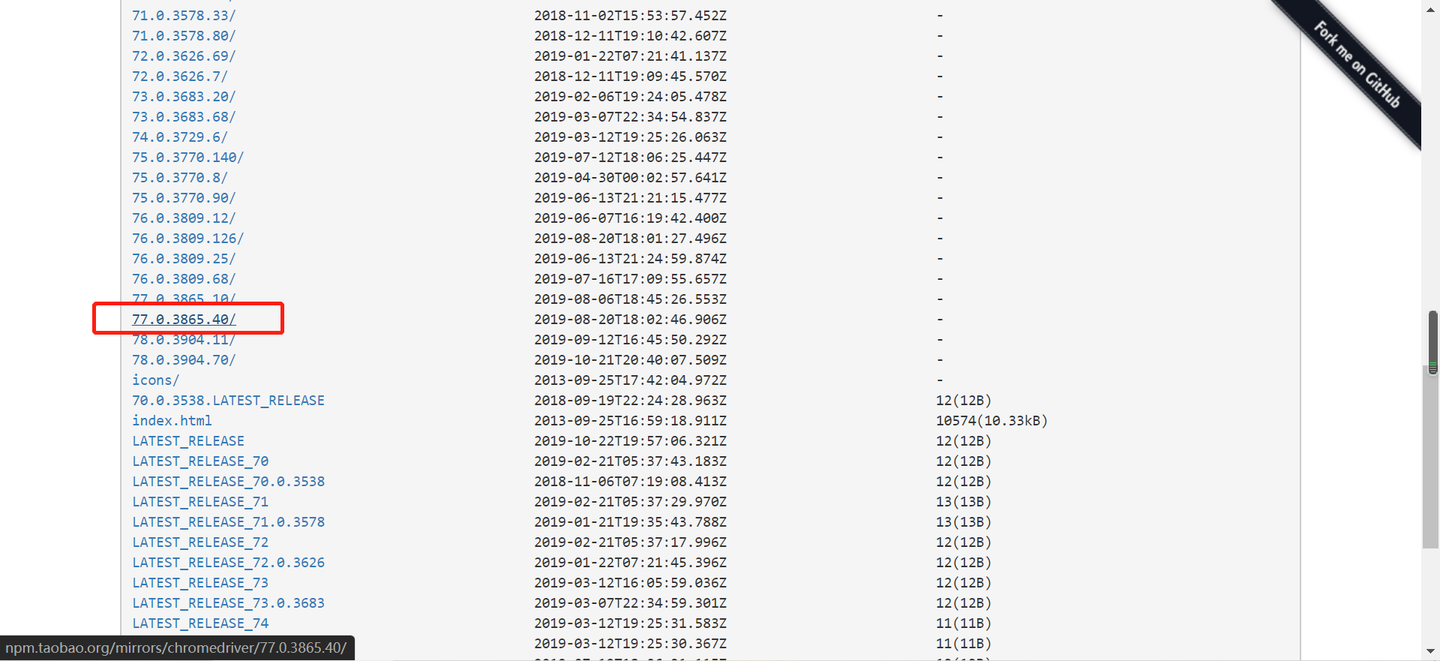
选择查看notes.txt,可以看到是支持77的,找到浏览器对应版本的Chromedriver了。


下载32位的就可以了,占资源更少,64位也可以用。下载好后解压文件看到:

别双击运行,推荐放到python安装路径下,比如我的python在D盘。(不和python放一起也行就是以后使用不方便。)

完成后在cmd下输入Chromedriver验证是否安装成功:

到这里所有工具配置完毕。
4.利用selenium+Chromedriver模拟操作
4.1 使用selenium打开百度,并搜索关键字“python”
selenium支持很多的浏览器,但是如果想要声明并调用浏览器则需要:
# 从selenium导入webdriver
from selenium import webdriver
# 声明调用哪个浏览器,本文使用的是Chrome,其他浏览器同理。有如下两种方法及适用情况
driver = webdriver.Chrome()#把Chromedriver放到python安装路径里
driver = webdriver.Chrome( executable_path="#放入Chromedriver的路径")#没有把Chromedriver放到python安装路径运行下面代码,会自动打开浏览器,然后访问百度:
注:driver.get()类似于requests.get(),不过区别就是driver.get()请求的源代码中还包含异步加载的数据,即“所见即所得”,这也是selenium模拟浏览器在爬虫中存在的意义。
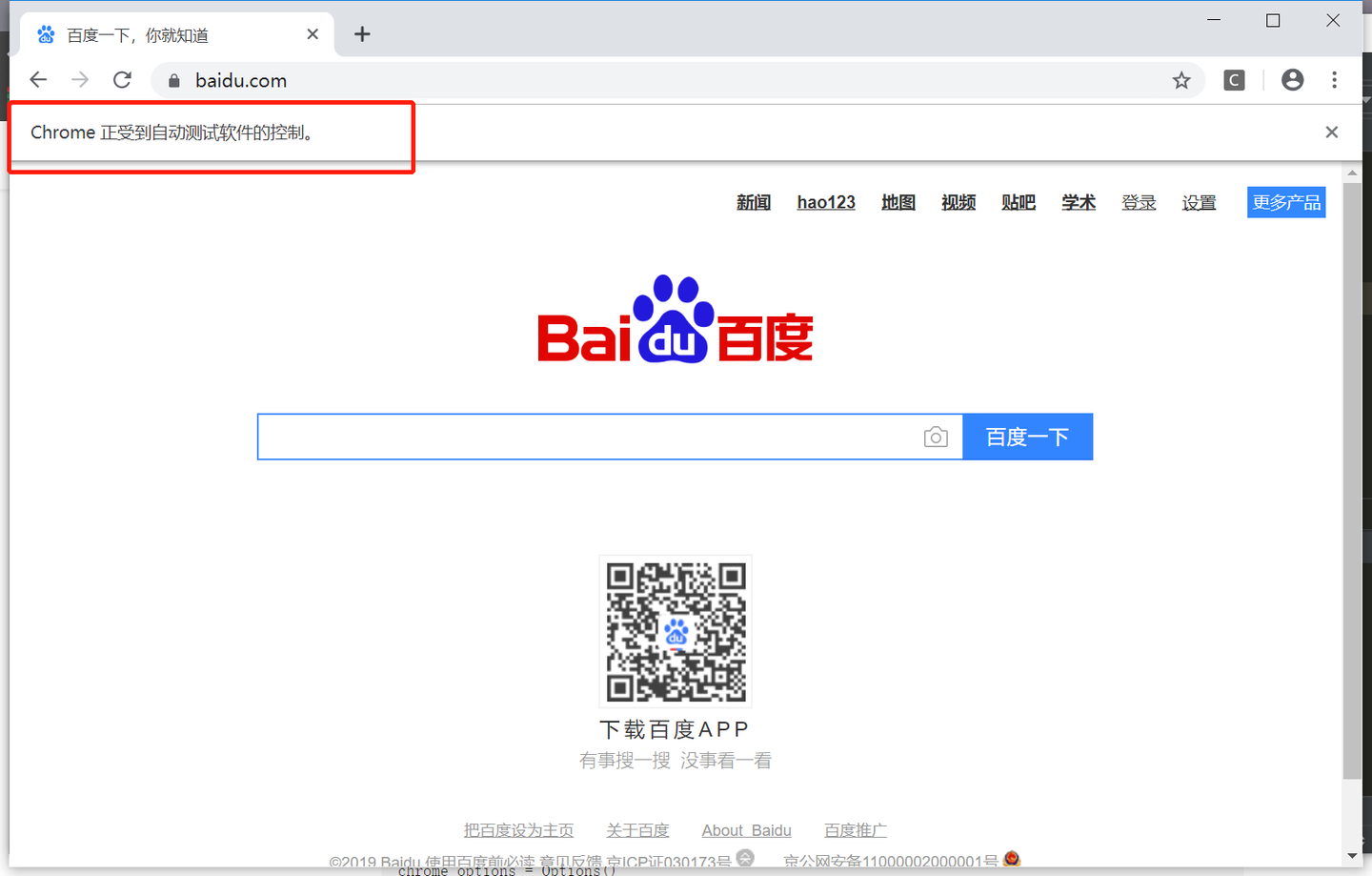
上图的百度界面就是通过selenium+Chromedriver打开的,显示Chrome正在受到自动测试软件的控制。抓取完数据,记得要关掉driver,不然会占内存:
driver.close()#浏览器可以同时打开多个界面,close只关闭当前界面,不退出浏览器
driver.quit()#退出整个浏览器下面代码实现打开百度界面等待三秒后退出:
基本的打开退出学会了,再来看看人工搜索关键词的流程:打开浏览器>>>打开百度>>>找到搜索输入框>>>输入要搜索的关键词>>>点击搜索按钮
前两个步骤上面代码已经实现了,再来看看找到输入框,和之前爬虫时寻找所需元素信息的套路一样,把鼠标放到输入框上,右击选择检查,很容易就找到了输入框的标签信息,如下图:
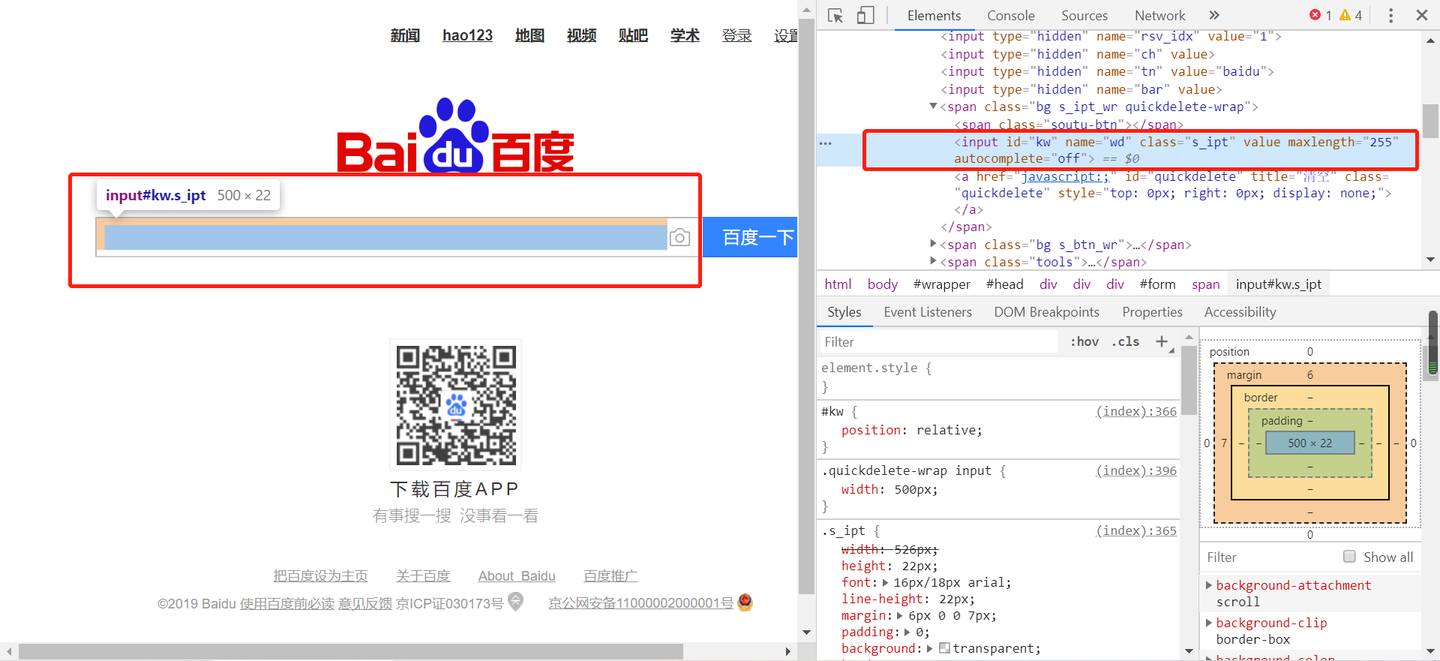
可以看到输入框的标签信息:
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">之前文章中定位元素信息用的最多的就是beautifulsoup的find和find_all,现在是通过Chromedriver打开浏览器的,人家也就自己的定位元素的一套办法:

红色框里就是selenium+webdriver定位元素的办法,常用办法如下:
- find_elements_by_id # ID
- find_elements_by_class_name # class
- find_elements_by_tag_name # 标签名
- find_elements_by_name # name
- find_elements_by_link_text # a标签中的text查找(精确匹配)
- find_elements_by_partial_link_text #a标签中的text查找(部分匹配即可)
- find_elements_by_css_selector # css选择器查找
- find_elements_by_xpath # find_elements_by_xpath("//input")
注:find_element_by_将获取find_elements_by_的第一个元素,记住element是获取单个元素,elements是获取符合条件的多个元素信息。
上面的办法通过标签名称还有标签属性定位元素应该已经很熟悉了,遇到复杂网页xpath的定位功能也是很强大,这两个办法应对绝大多数网页已经足够,第7种方法:通过CSS选择器获取信息,学习一下。
有了这些方法,获取输入框信息应该已经很简单了,如下代码:
#通过id信息来获取
input = driver.find_element_by_id('kw')
#还可以通过xpath来获取
input = =driver.find_element_by_xpath(//*[@id="kw"])
最后两个步骤,代码实现如下:
input.send_keys('python')#在输入框里输入搜索关键词“python”
searchButton = driver.find_element_by_id('su') #获取搜索按钮
searchButton.click()#点击搜索按钮到这里,selenium打开百度,并搜索关键字“python”就已经实现了,完整代码如下:

4.2 使用selenium爬取京东商品信息

京东是一个异步加载的网页,移动滚动条会一直加载数据,和之前说的豆瓣电影排行榜的网页是类似的[2]。继续重复上面在百度输入关键词搜索的步骤,获取京东页面>>>获取搜索输入框>>>输入搜索关键词>>>点击搜索按钮>>>移动滚动条到网页底部>>>获取整页商品的名称和价格信息。移动滚动条到网页底部,是采用js脚本直接操作[3],完整代码详细及注释:
from selenium import webdriver # 从selenium导入webdriver
import time
url = 'https://www.jd.com/'
driver = webdriver.Chrome() # 声明调用Chrome
driver.get(url) # 获取京东页面
input = driver.find_element_by_xpath('//*[@id="key"]')#获取输入框
input.send_keys('iphone')#输入搜索关键词
driver.find_element_by_xpath('//*[@id="search"]/div/div[2]/button').click()#点击搜索按钮
js="var q=document.documentElement.scrollTop=100000"#将滚动条移动到页面底部的js语句
driver.execute_script(js)#执行上面移动滚动条的js语句
time.sleep(5)#睡眠,等待异步加载的数据加载完成
#获取文本信息时selenium中的xpath语法与之前区别:前面是在xpath路径后加/text(),而selenium是整个语句后面加.text
prices = driver.find_elements_by_xpath('//*[@id="J_goodsList"]/ul/li/div/div[3]/strong/i')
names = driver.find_elements_by_xpath('//*[@id="J_goodsList"]/ul/li/div/div[4]/a/em')
print(len(names))#京东每页有60个商品信息,检查爬取数据是否完整
for name,price in zip(names,prices):
print(name.text.replace('\n',''),price.text)
driver.quit()#退出运行结果:
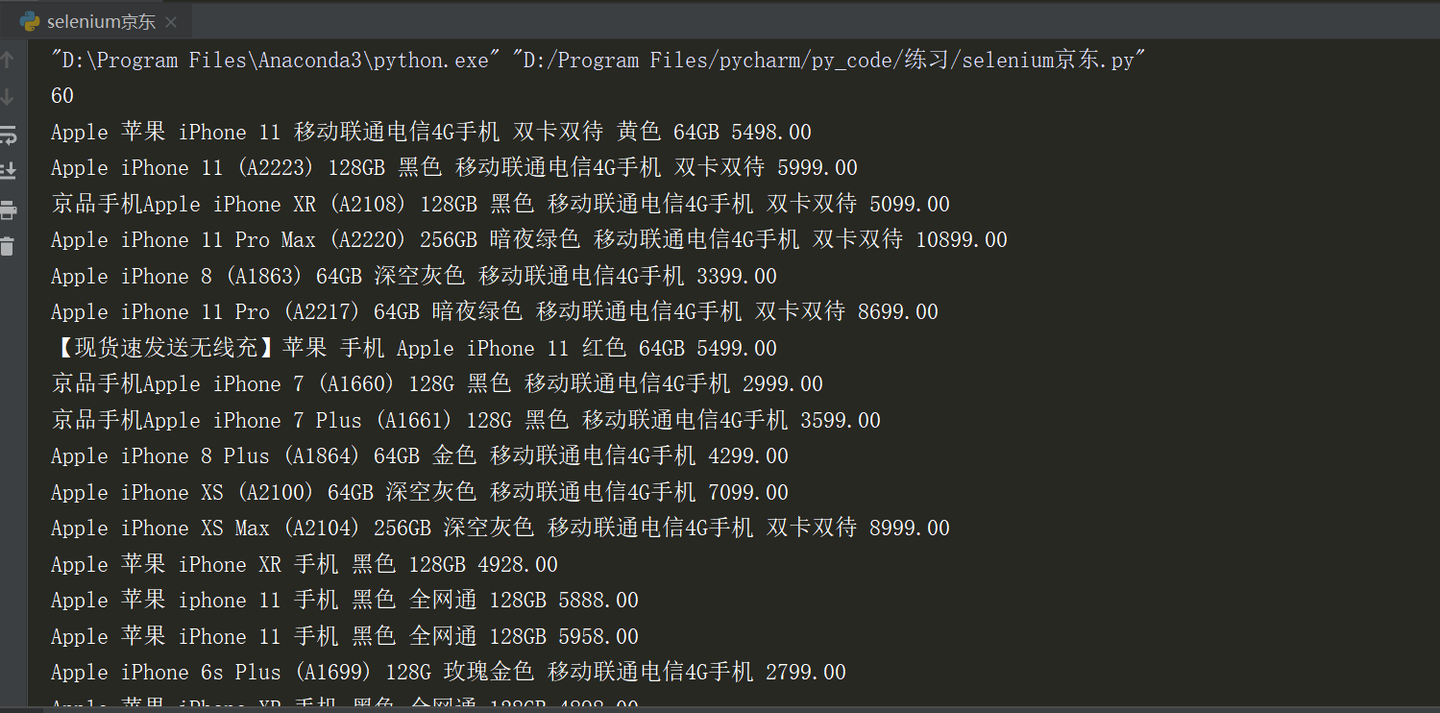
显示60条商品信息全部爬取成功。
5.小结
本文只是对selenium+webdriver爬虫做了一个简单的介绍及应用,起到一个抛砖引玉的作用,要想利用好这个工具还需要后期查看更多的资料进行补充学习,上面介绍的Chromedriver爬虫效率还很低,后期可以使用Chrome的无头浏览器模式即headless模式,设置无图属性不用加载图片等方法,提升selenium模拟浏览器爬虫效率。