scrapy_0">爬虫scrapy管道的使用
学习目标:
- 掌握 scrapy管道(pipelines.py)的使用
1. pipeline中常用的方法:
- process_item(self,item,spider):
- 管道类中必须有的函数
- 实现对item数据的处理
- 必须return item
- open_spider(self, spider): 在爬虫开启的时候仅执行一次
- close_spider(self, spider): 在爬虫关闭的时候仅执行一次
2. 管道文件的修改
继续完善wangyi爬虫,在pipelines.py代码中完善
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import json
from itemadapter import ItemAdapter
class MyspiderPipeline:
def __init__(self):
self.file = open('lianjia.json','w')
# 爬虫文件中提取数据的方法每yield一次item,就会运行一次
# 该方法为固定名称函数
def process_item(self, item, spider):
# 参数item默认是一个 <class 'mySpider.items.MyspiderItem'>类信息,需要处理成字典
dict_data = dict(item)
print(type(item), type(dict_data))
# 将返回的字典数据转为JSON数据
json_data = json.dumps(dict_data,ensure_ascii=False)+',\n'
# 写入JSON数据
self.file.write(json_data)
# 参数item:是爬虫文件中yield的返回的数据对象(引擎会把这个交给管道中的这个item参数)
print("建模之后的返回值:",item,)
# 默认使用完管道之后将数据又返回给引擎
return item
def __del__(self):
self.file.close()
3. 开启管道
在settings.py设置开启pipeline
......
ITEM_PIPELINES = {
'myspider.pipelines.lianjiaPipeline': 400, # 400表示权重
'myspider.pipelines.lianjiaPipeline': 500, # 权重值越小,越优先执行!
}
......
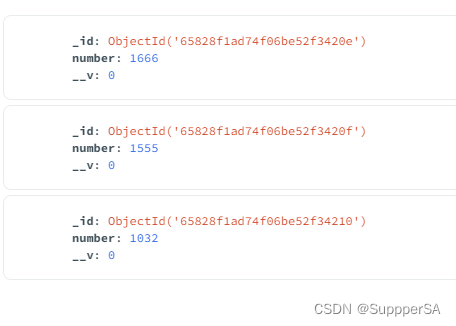
别忘了开启mongodb数据库 sudo service mongodb start
并在mongodb数据库中查看 mongo
思考:在settings中能够开启多个管道,为什么需要开启多个?
- 不同的pipeline可以处理不同爬虫的数据,通过spider.name属性来区分
- 不同的pipeline能够对一个或多个爬虫进行不同的数据处理的操作,比如一个进行数据清洗,一个进行数据的保存
- 同一个管道类也可以处理不同爬虫的数据,通过spider.name属性来区分
4. pipeline使用注意点
- 使用之前需要在settings中开启
- pipeline在setting中键表示位置(即pipeline在项目中的位置可以自定义),值表示距离引擎的远近,越近数据会越先经过:权重值小的优先执行
- 有多个pipeline的时候,process_item的方法必须return item,否则后一个pipeline取到的数据为None值
- pipeline中process_item的方法必须有,否则item没有办法接受和处理
- process_item方法接受item和spider,其中spider表示当前传递item过来的spider
- open_spider(spider) :能够在爬虫开启的时候执行一次
- close_spider(spider) :能够在爬虫关闭的时候执行一次
- 上述俩个方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立和数据库的连接,在爬虫关闭的时候断开和数据库的连接