目录
1. 获取访问接口
2. 链接网址
3. 链接名单
免责声明:本文由作者参考相关资料,并结合自身实践和思考独立完成,对全文内容的准确性、完整性或可靠性不作任何保证。同时,文中提及的数据仅作为举例使用,不构成推荐;文中所有观点均不构成任何投资建议。请读者仔细阅读本声明,若读者阅读此文章,默认知晓此声明。本文使用爬虫获取相关网站公开数据,仅作为技术分享使用,数据不涉及商用和盈利。
申万一级行业数据,对于行业的统计分析非常重要,本文主要是分享,如何通过爬虫获取其历史收盘价数值。
1. 获取访问接口
此方法由一位昵称为‘富贵’的大佬分享,在此对其表示感谢。
许多数据源使用的是json传输到网页,使用xpath或者bs4均无法提取数据,因此需要使用直接访问传输文件对应的接口。
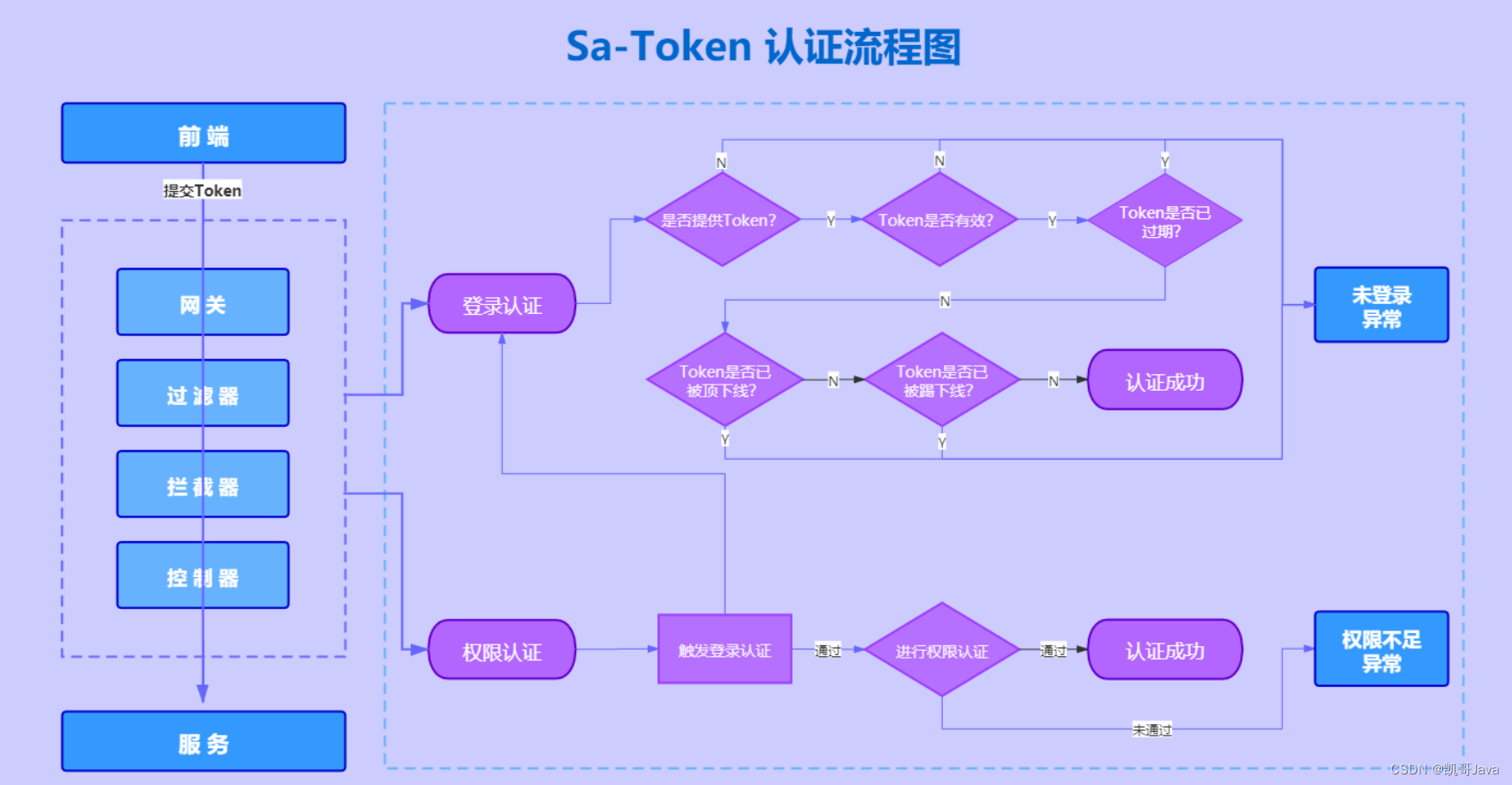
首先根据网址名称申万宏源证券咨询网 (swhyresearch.com),F12获取相应的网页信息。
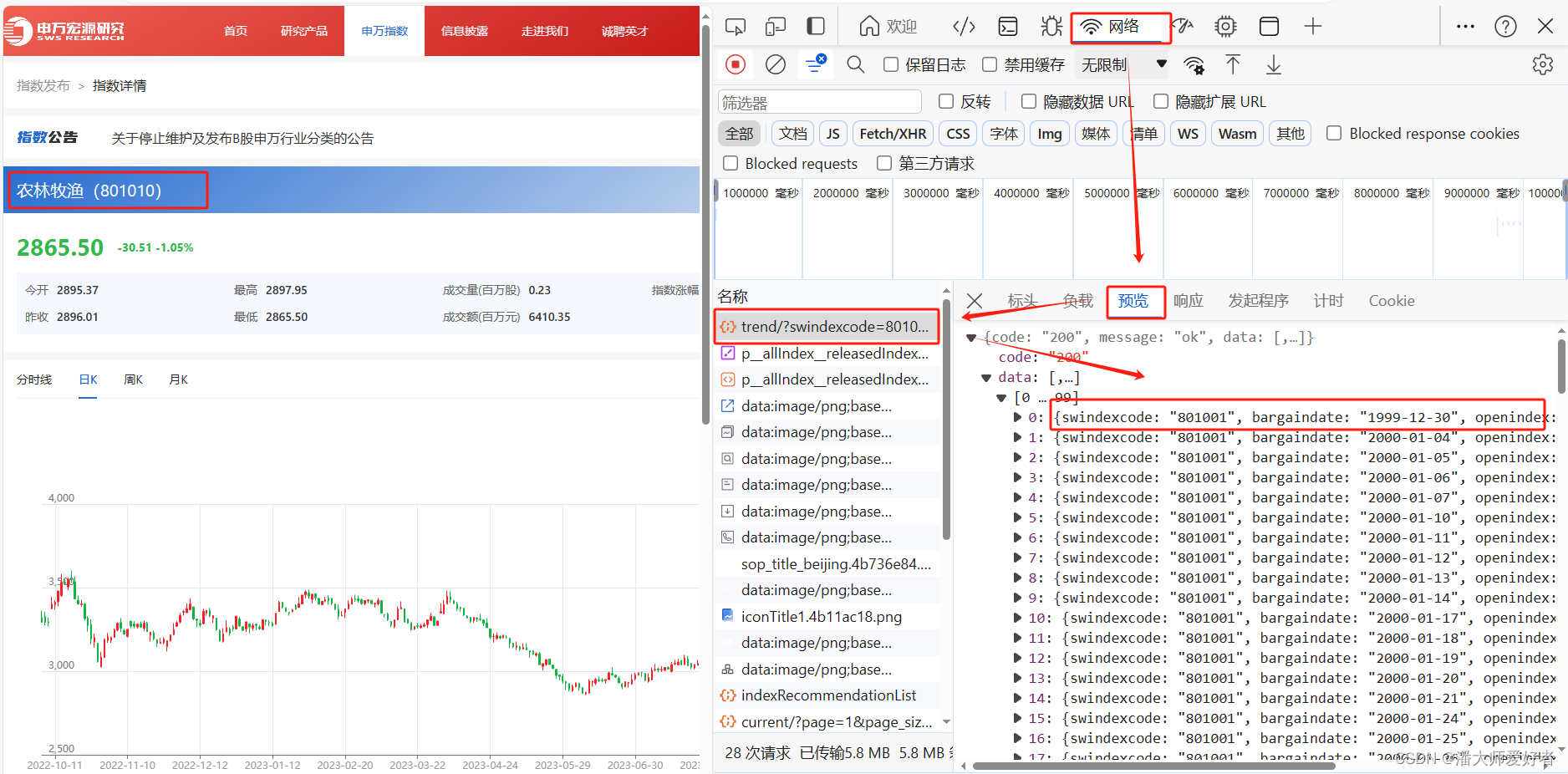
根据网页信息,可以发现trend文件中包含所需数据 ,接下来复制该文本为URL(bash)。

将获取的数据粘贴到 https://curlconverter.com/中,并切换语言为python。
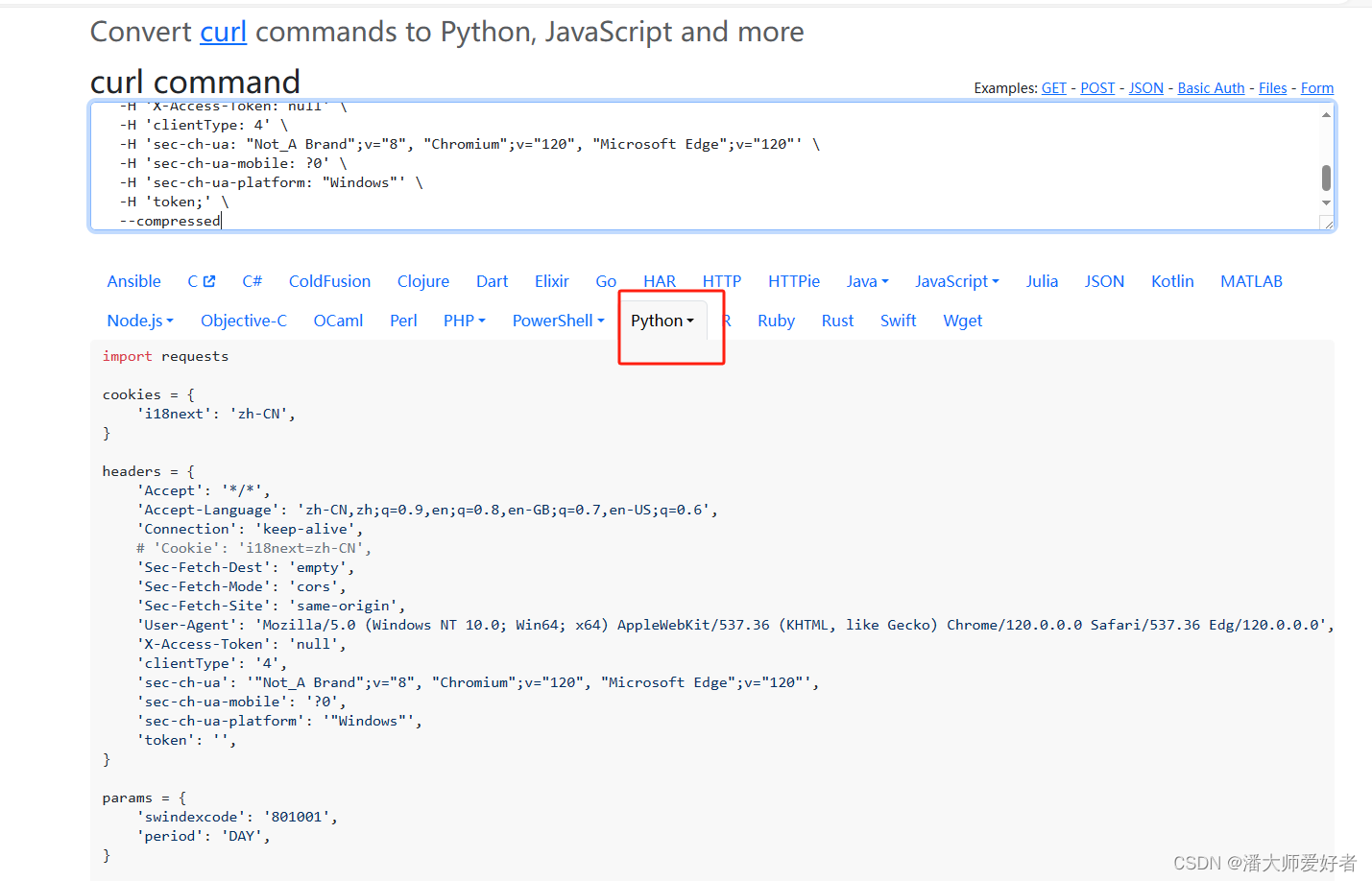
这样一来,就可以获取类似于接口的代码:
import requests
cookies = {
'i18next': 'zh-CN',
}
headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
# 'Cookie': 'i18next=zh-CN',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0',
'X-Access-Token': 'null',
'clientType': '4',
'sec-ch-ua': '"Not_A Brand";v="8", "Chromium";v="120", "Microsoft Edge";v="120"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'token': '',
}
params = {
'swindexcode': '801001',
'period': 'DAY',
}
response = requests.get(
'https://www.swhyresearch.com/institute-sw/api/index_publish/trend/',
params=params,
cookies=cookies,
headers=headers,
)2. 链接网址
根据上述的代码,调整所需参数(参数位于params中,即申万一级行业对应的编码和数据频率),然后解析,即可获得数据(本文仅获取日期和收盘价)。
import requests
import pandas as pd
import sys
def get_sw_data(code, period=None):
'''
获取单个申万一级行业指数的收盘价
code:str,指数编码,例如'801001'
period:str,数据频率,例如'DAY',默认为日度;DAY-日度,WEEK-周度,MONTH-月度
-------
返回DataFrame,列名为日期和收盘价
'''
cookies = {'i18next': 'zh-CN', }
headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
# 'Cookie': 'i18next=zh-CN',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0',
'X-Access-Token': 'null',
'clientType': '4',
'sec-ch-ua': '"Not_A Brand";v="8", "Chromium";v="120", "Microsoft Edge";v="120"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'token': '',
}
params = {'swindexcode': code, 'period': period or 'DAY'}
response = requests.get('https://www.swhyresearch.com/institute-sw/api/index_publish/trend/',
params=params, cookies=cookies, headers=headers)
# 判断是否提取到数据,若未拿到数据,自动退出
if response.status_code == 200:
print('链接成功!开始获取数据')
else:
print('链接失败!自动退出', response.status_code)
sys.exit()
# 解码并将数据转换为DataFrame,然后对所需字段进行转换
text_json = response.json()
data = pd.DataFrame(text_json["data"])
# 日期转化为str,格式如'20200101'
data['date'] = data['bargaindate'].apply(lambda x: pd.to_datetime(str(x)).strftime("%Y%m%d"))
out_df = pd.DataFrame({'日期': data['date'], '收盘价': data['closeindex']})
return out_df
if __name__ == '__main__':
code = '801001'
data = get_sw_data(code, 'MONTH')运行后,得到的结果为:
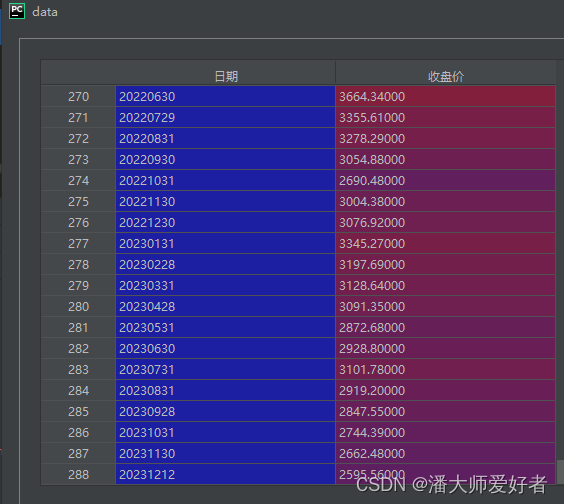
3. 链接名单
第二节分享了如何获取单个申万行业指数的数据,本节主要分享如何获取申万行业的名单和编码,方法和之前一样。网址为申万宏源证券咨询网 (swhyresearch.com)
对应的代码为:
import requests
import pandas as pd
cookies = {'i18next': 'zh-CN', }
headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
# 'Cookie': 'i18next=zh-CN',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0',
'X-Access-Token': 'null',
'clientType': '4',
'sec-ch-ua': '"Not_A Brand";v="8", "Chromium";v="120", "Microsoft Edge";v="120"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'token': '', }
# page--页数;page_size--单页展示多少条数据,最大50条
# 由于申万行业当前共有30多个,因此此处直接设置为50,不进行循环page的操作
params = {'page': '1', 'page_size': '50', 'indextype': '一级行业', 'sortField': '', 'rule': '', }
response = requests.get('https://www.swhyresearch.com/institute-sw/api/index_publish/current/',
params=params, cookies=cookies, headers=headers)
text_json = response.json()
data = pd.DataFrame(text_json["data"]['results'])
out_df = pd.DataFrame({'申万代码': data['swindexcode'],
'指数名称': data['swindexname']})对应的结果为:
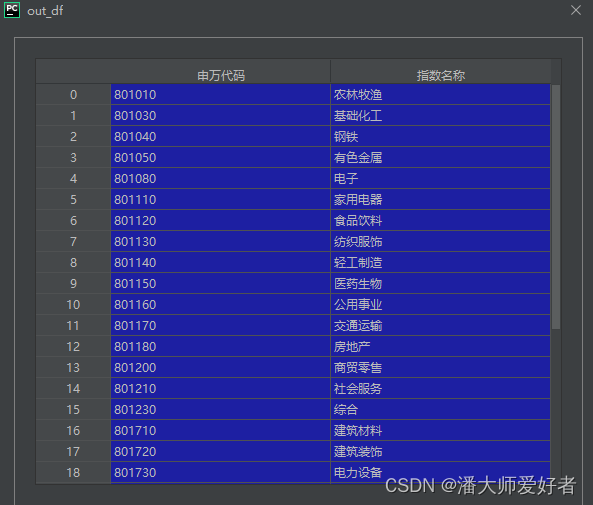
结合第二节,是用循环,就可以获取所有申万一级行业的指数 数据,需要注意的是,循环时尽可能设置一下访问的时间间隔,不要过度和过快的去访问。许多可优化的点,本文就不再深究。
本期分享结束,有何问题欢迎交流。
免责声明:本文由作者参考相关资料,并结合自身实践和思考独立完成,对全文内容的准确性、完整性或可靠性不作任何保证。同时,文中提及的数据仅作为举例使用,不构成推荐;文中所有观点均不构成任何投资建议。请读者仔细阅读本声明,若读者阅读此文章,默认知晓此声明。本文使用爬虫获取相关网站公开数据,仅作为技术分享使用,数据不涉及商用和盈利。