``
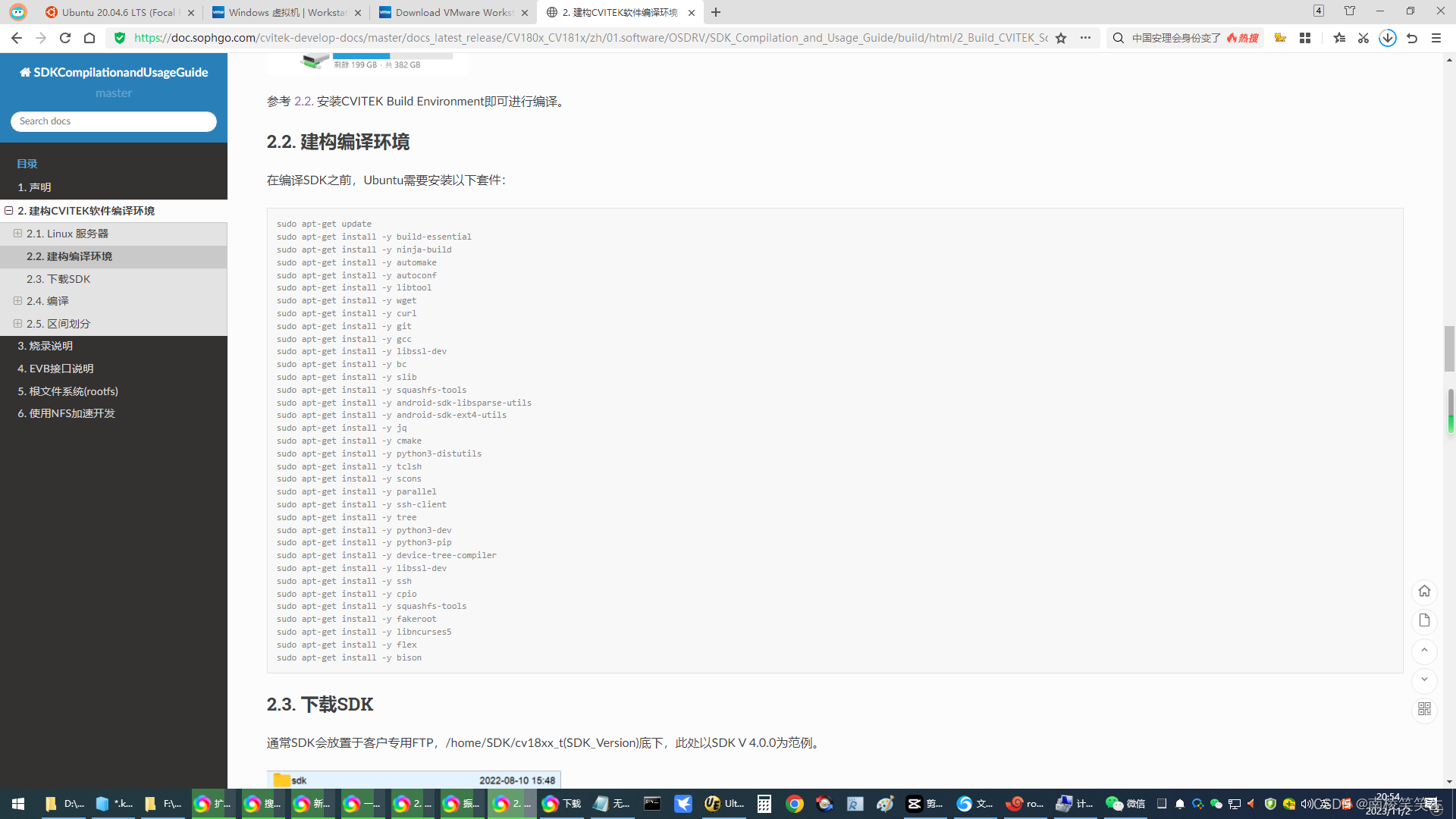
`scala
import com.github.katongli.http.crawler.Fetch
val fetch=Fetch()
fetch.setProxyHost("jshk.com.cn//aa")
fetch.setProxyPort(0126)
val response=fetch(url)
val images=response.images
//你可以使用println将获取的图片打印出来
println(images)
```
解释:
1.导入了com.github.katongli.http.crawler.Fetch库,这个库可以帮助我们进行网络爬虫。
2.创建了一个Fetch对象,用于执行网络爬虫。
3.设置了代理服务器的主机名和端口号。
4.定义了要爬取的URL。
5.使用Fetch对象执行网络爬虫,并获取到响应对象。
6.从响应对象中获取到所有的图片。
7.可以使用println将获取的图片打印出来,以便查看效果。