在学习爬虫时,遇到了一个有意思的网站,这个网站设置了几个关卡,需要经过爬虫进行闯关,随着关卡的网后,难度不断增加,在闯关的过程中需要学习不同的知识,你的爬虫水平也自然随之提高。
今天我们先来第一关,访问http://www.heibanke.com/lesson/crawler_ex00/:

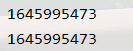
按照提示,我们把数字放到地址栏的后面,再次进行访问:

发现,还要再用新的数字放在地址栏进行访问,我们可以猜测了,第一关是将页面出现的数字填写到当前 url 的尾部进行访问,然后会得到一个新的数字,再用它替换 url 中的尾部数字,这样不断循环往复,直到页面出现成功标识:

那么思路也有了:
- 解析页面中的数字;
- 将数字拼接成新的 URL;
- 访问新的 URL,重复第 1 步;
- 直至页面没有数字可以解析到!
逻辑比较简单,这里我们直接上代码了:
BeautifulSoup 实现
python"># coding=utf-8
import requests, bs4, re
url = 'http://www.heibanke.com/lesson/crawler_ex00/'
while True:
# download the page
print("forward to page %s ..." % url)
response = requests.get(url)
print("the return code : " + str(response.status_code))
soup = bs4.BeautifulSoup(response.text, "html.parser")
# 获取页面数字
comic = soup.select('h3')
print(comic[0].getText())
number = re.findall("\d+", comic[0].getText())
if number == []:
print('The end.')
break;
else:
url = 'http://www.heibanke.com/lesson/crawler_ex00/' + number[0] # 拼接新地址
selenium 实现
python"># coding=utf-8
import requests, re
from selenium import webdriver
url = 'http://www.heibanke.com/lesson/crawler_ex00/'
browser = webdriver.Firefox()
while True:
# download the page
print("Forward to page %s ..." % url)
browser.get(url)
elem = browser.find_element_by_tag_name('h3')
# get the url of the for the next page
print(elem.text)
number = re.findall("\d+", elem.text)
if number == []:
print('The end.')
browser.quit()
break;
else:
url = 'http://www.heibanke.com/lesson/crawler_ex00/' + number[0] # 拼接新地址到这里我们才能看到最终成功的页面长这样:

好了,第一关相对来说比较容易,下次我们来搞一下第二关,又兴趣的可以自己先上手攻取下了~
如果觉得有用,欢迎关注我的微信,一起学习,共同进步,不定期推出赠书活动~

最近搜集到慕课网视频,视频内容涵盖 Python、Java、PHP、前端、小程序、算法、架构、数据库等等!关注本公众号,后台回复「慕课网」即可获取下载地址。