python网路爬虫 --------- 使用百度输入的关键字搜索内容然后爬取搜索内容的url
开发环境:windows7+python3.6.3
开发语言:Python
开发工具:pycharm
第三方软件包:需安装lxml4.0,如果只安装lxml会出错,要需要lxml中的etree
废话不多说,贴上代码:
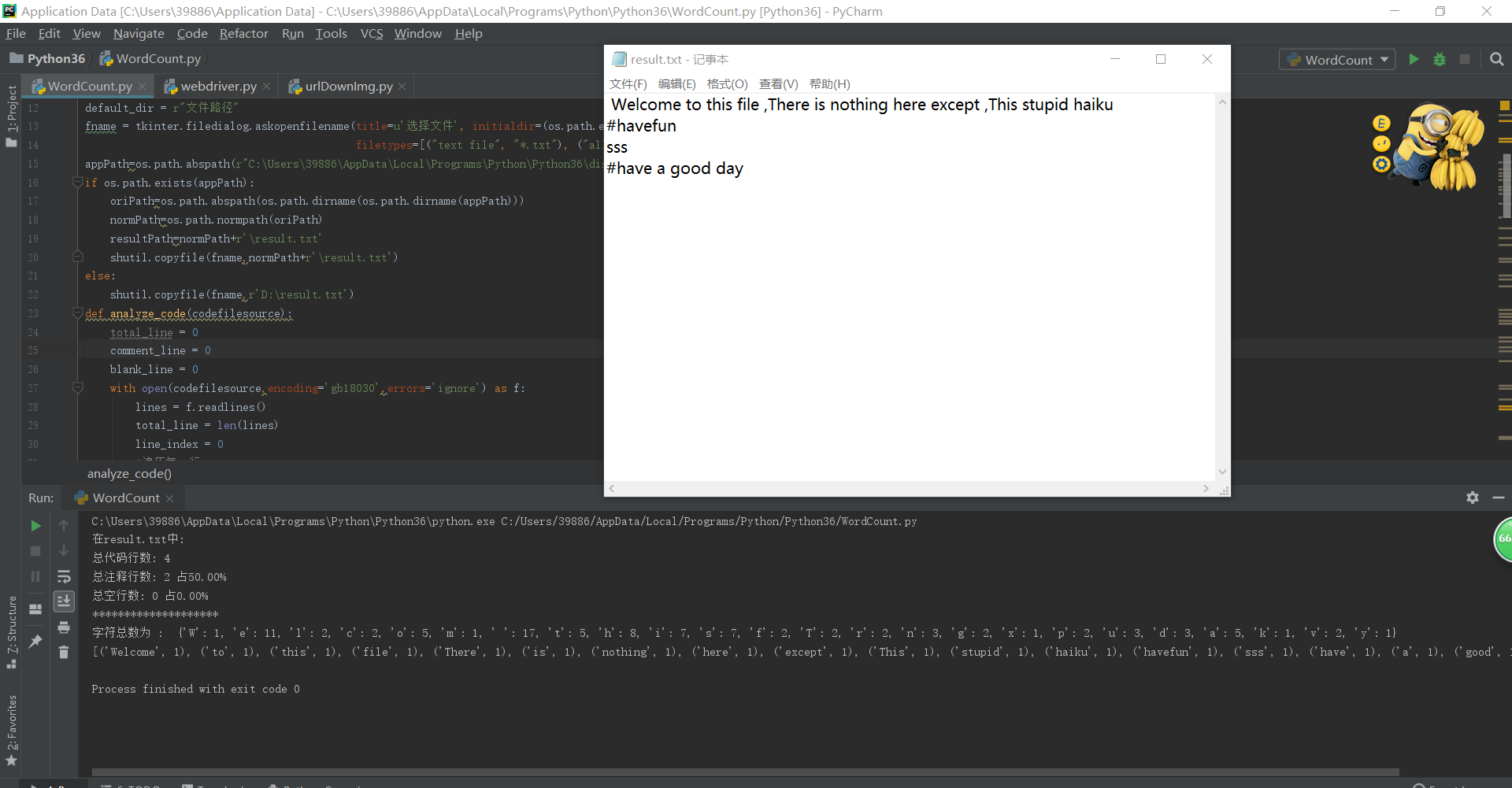
爬取数据保存以TXT格式保存,等会尝试使用Excel表格跟数据库保存。


1 import requests,time 2 from lxml import etree 3 4 5 def Redirect(url): 6 try : 7 res = requests.get(url,timeout=10) 8 url = res.url 9 except Exception as e: 10 print('4',e) 11 time.sleep(1) 12 return url 13 14 def baidu_search(wd,pn_max,sav_file_name): 15 url = 'http://www.baidu.com/s' 16 return_set = set() 17 18 for page in range(pn_max): 19 pn = page*10 20 querystring = {'wd':wd,'pn':pn} 21 headers = { 22 'pragma':'no-cache', 23 'accept-encoding': 'gzip,deflate,br', 24 'accept-language' : 'zh-CN,zh;q=0.8', 25 'upgrade-insecure-requests' : '1', 26 'user-agent': "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0", 27 'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", 28 'cache-control': "no-cache", 29 'connection': "keep-alive", 30 } 31 32 try : 33 response = requests.request('GET',url,headers=headers,params=querystring) 34 print('!!!!!!!!!!!!!!',response.url) 35 selector = etree.HTML(response.text,parser = etree.HTMLParser(encoding='utf-8')) 36 except Exception as e: 37 print('页面加载失败',e) 38 continue 39 with open(sav_file_name,'a+') as f: 40 for i in range(1,10): 41 try : 42 context = selector.xpath('//*[@id="'+str(pn+i)+'"]/h3/a[1]/@href') 43 print(len(context),context[0]) 44 i = Redirect(context[0]) 45 print('context='+context[0]) 46 print ('i='+i) 47 f.write(i) 48 f.write('\n') 49 break 50 return_set.add(i) 51 f.write('\n') 52 except Exception as e: 53 print(i,return_set) 54 print('3',e) 55 56 return return_set 57 58 if __name__ == '__main__': 59 wd = '网络贷款' 60 pn = 100 61 save_file_name = 'save_url_soup.txt' 62 return_set = baidu_search(wd,pn,save_file_name)
![[OS-Linux]详解Linux的进程2(进程的优先级,环境变量,程序地址空间,进程地址空间,进程调度队列)](https://img-blog.csdnimg.cn/20211002150317942.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAVFTlnKjplb_lpKc=,size_20,color_FFFFFF,t_70,g_se,x_16)
![[OS-Linux]详解Linux进程控制](https://img-blog.csdnimg.cn/2021100315165446.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAVFTlnKjplb_lpKc=,size_20,color_FFFFFF,t_70,g_se,x_16)
![[OS-Linux]详解Linux基础开发工具](/images/no-images.jpg)
![[OS-Linux]详解Linux的基础IO (1) ------- 文件描述符fd](https://img-blog.csdnimg.cn/280bbec74afe4384953396a5fbdac34f.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAVFTlnKjplb_lpKc=,size_20,color_FFFFFF,t_70,g_se,x_16)
![[C/C++]详解C++的多态](https://img-blog.csdnimg.cn/1a44bd4eaa1e44638dfa9b30d2603c7c.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAVFTlnKjplb_lpKc=,size_20,color_FFFFFF,t_70,g_se,x_16)