前言
闲来无事浏览GitHub的时候,看到一个仓库,里边列举了Java的优秀开源项目列表,包括说明、仓库地址等,还是很具有学习意义的。但是大家也知道,国内访问GitHub的时候,经常存在访问超时的问题,于是就有了这篇文章,每日自动把这些数据爬取下来,随时看到热点排行。
仓库地址:https://github.com/akullpp/awesome-java
仓库页面截图:
分析
根据以往爬虫经验,先确定好思路,再开始开发代码效率会更高。那么,第一步,找一下我们的数据来源。
具体步骤:先开启F12,刷新网页,根据关键词搜索,看数据来源是哪个接口(此处以列表里的Maven为例,其他也可以)
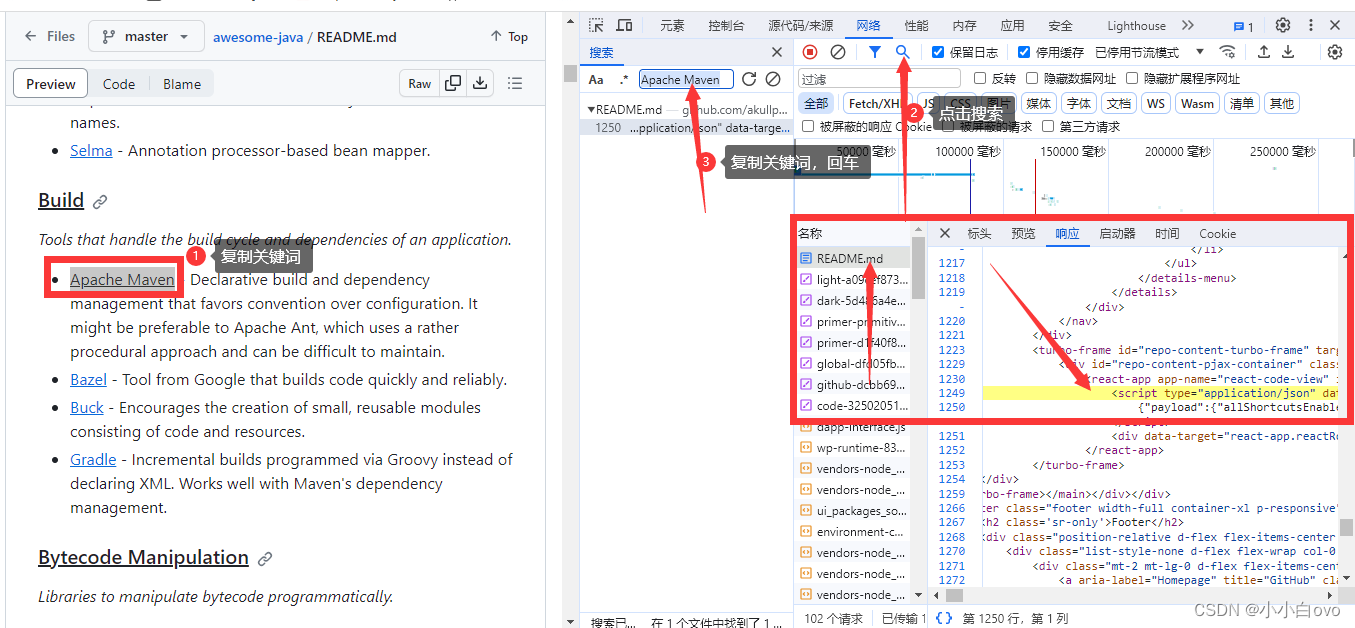
可以看到,项目列表都是来源于这个.md文档的1250行,可以看到,这是一个标准的JSON数据,我们把这行数据复制出来进行分析(由于数据太长,不做展示),继续搜索后发现,我们需要的项目列表和说明,都在其中richText字段里,如下:
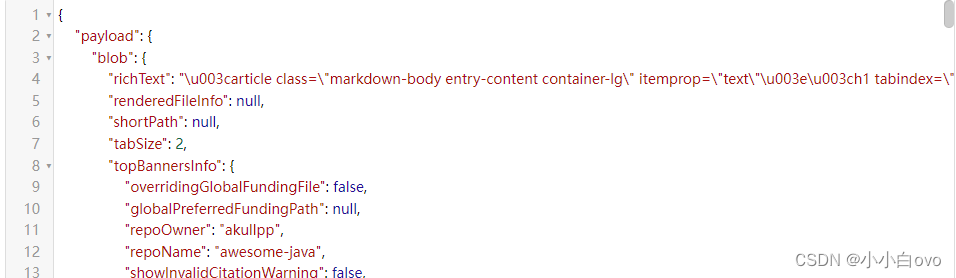
而这个富文本数据都是Unicode编码,为了方便查看结构,我们将其转为中文,可以用如下的正则匹配,批量转换
java"> richData = richData.replaceAll("/\\\\u([0-9a-f]{3,4})/i", "&#x\\1;");
转换完之后继续看这个富文本数据
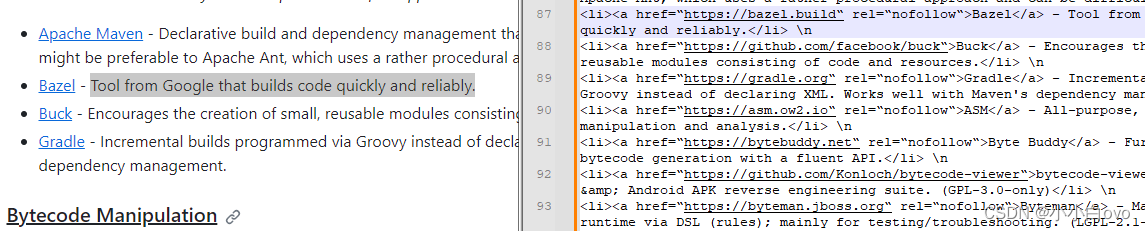
我们需要的东西对应的是一个一个的<li>标签和<a>标签,找到数据源之后就可以正式开始开发了。
项目开发
1、准备工作
- 开发框架选择SpringBoot,持久层框架使用MyBatis。除必要的基础依赖以外,还需要引入以下依赖:
jsoup:对网页结构分析,解析数据
okhttp:HTTP客户端,访问页面使用。
fastjson:解析JSON数据 - 关系型数据库选择Mysql,非关系型数据库选择Redis
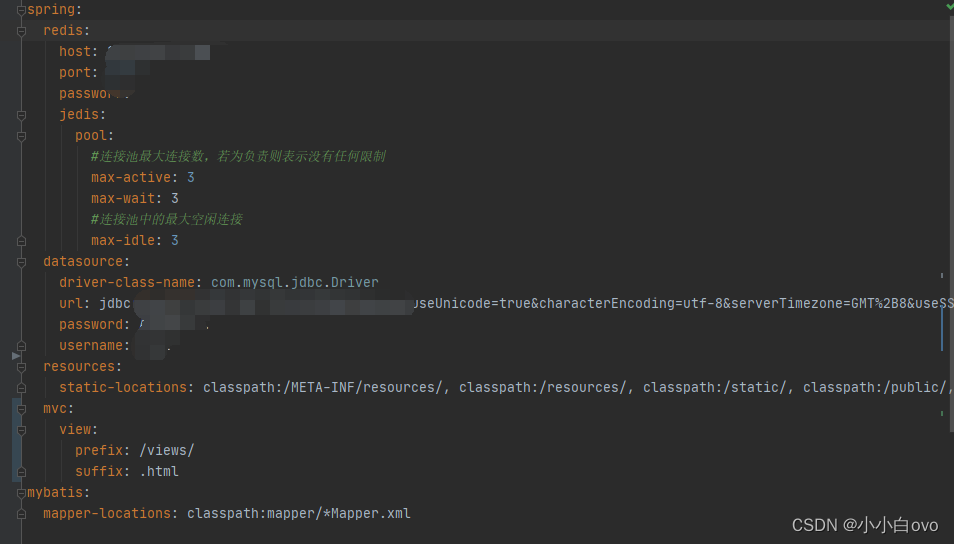
- 编辑配置文件
2、项目列表解析代码开发
根据前期分析的思路,首先使用okhttp客户端,访问https://github.com/akullpp/awesome-java/blob/master/README.md页面,获取到响应正文。
java"> public String getPage(String url) {
try {
// 1.创建okhttp客户端对象
OkHttpClient okHttpClient = new OkHttpClient();
// 2.创建request对象 (用Request的静态类创建)
Request request = new Request.Builder().url(url).build();
// 3.创建一个Call对象,负责进行一次网络访问操作
Call call = okHttpClient.newCall(request);
// 4.发送请求到服务器,获取到response对象
Response response = call.execute();
// 5.判断响应是否成功
if (!response.isSuccessful()) {
System.out.println("请求失败!");
return null;
}
return response.body().string();
}catch (Exception e){
log.error("请求页面出错:{}",e.getMessage());
return null;
}
}
获取到正文后如图所示:
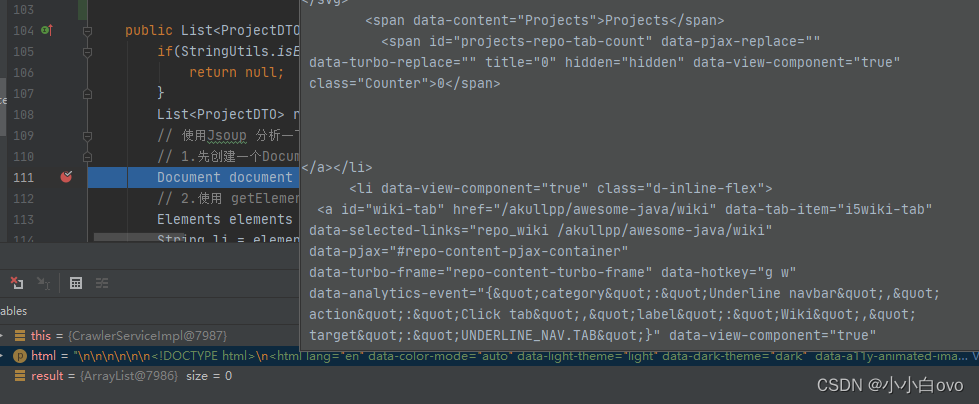
接着我们使用Jsoup对网页结构进行解析,因为需要的数据处于<Script>标签,因此我们只提取这个标签数据即可,代码为:
java">Document document = Jsoup.parse(html);
// 2.使用 getElementsByTag,拿到所有的标签 elements相当于集合类。每个element对应一个标签
Elements elements = document.getElementsByTag("script");
提取之后效果如图:
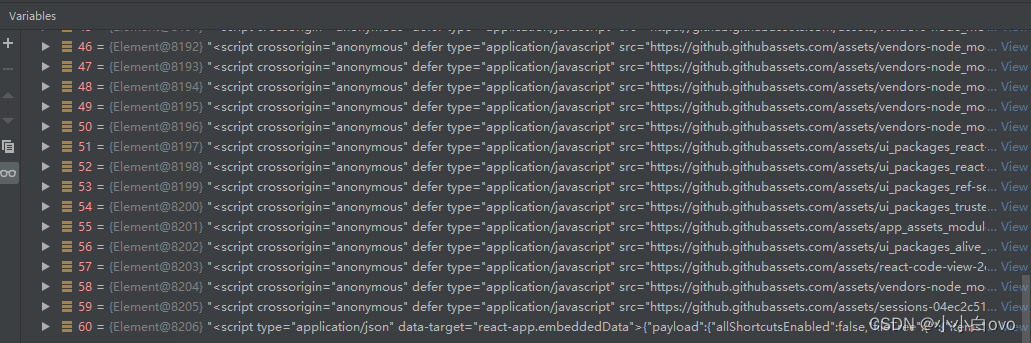
需要的数据在列表最后一位,取到之后因其是HTML语法,我们需要将其处理转为标准JSON,然后根据第一步分析的结果,根据key提取richText所在的值,并将Unicode转为中文。
java">String li = elements.get(elements.size()-1).toString()
.replace("<script type=\"application/json\" data-target=\"react-app.embeddedData\">","")
.replace("</script>","");
JSONObject pageRes = JSONObject.parseObject(li);
String richData = pageRes.getJSONObject("payload").getJSONObject("blob").getString("richText");
richData = richData.replaceAll("/\\\\u([0-9a-f]{3,4})/i", "&#x\\1;");
处理结果为:
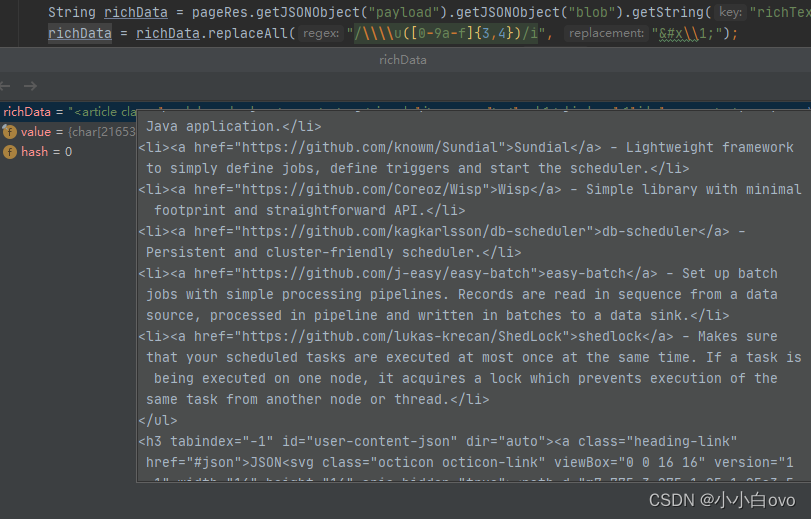
转换完的字符串还是标准的HTML语法,继续用Jsoup解析结构,获取到所有的<li>标签和<a>标签
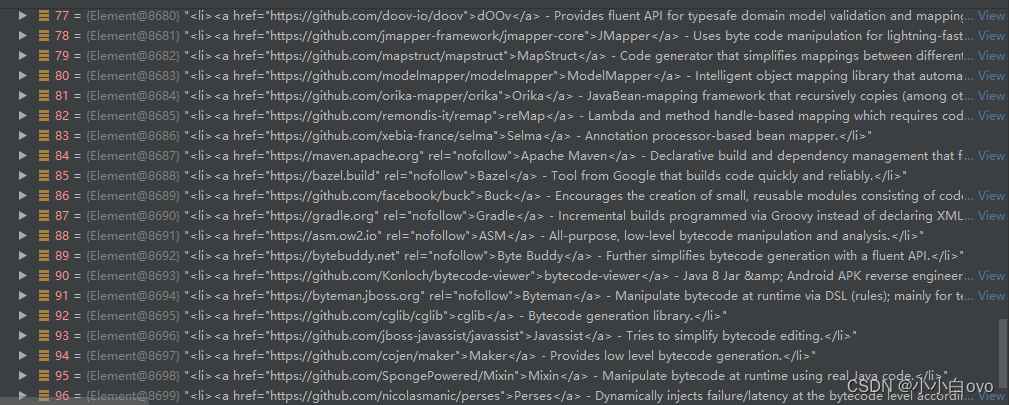
将需要的数据提取出来,再根据提取出来的数据继续爬取项目详情页,格式为:https://github.com/作者名/仓库名(因代码基本一致,此处不再赘述),获取项目对应的StartCount、forkCount、IssuesCount,转换为数据库实体对象并存储即可。
3、定时任务
编写定时任务代码,每天三点执行爬取任务,因为可能存在连接超时,因此增加五十次失败重试。执行结束后不管成功失败,微信推送执行结果
java"> private static String PageUrl = "https://github.com/akullpp/awesome-java/blob/master/README.md";
//[秒] [分] [小时] [日] [月] [周]
@Scheduled(cron = "0 0 3 * * ?")
public void crawlerTaskFunction() throws InterruptedException {
// 1.获取入口页面
int count = 1;
String html = crawlerService.getPage(PageUrl);
if(html == null){
//如果失败,重试五十次,间隔五秒
for (int i = 0; i < 50; i++) {
Thread.sleep(5000L);
count++;
log.error("抓取页面失败,正在第 {} 次重新尝试",i+1);
html = crawlerService.getPage(PageUrl);
if(html != null){
break;
}
}
if(html == null){
log.error("抓取页面失败,正在发送失败消息!");
JSONObject re = new JSONObject();
re.put("本次重试次数:", 50);
re.put("时间:", MyUtils.nowTime());
//微信推送执行结果消息
System.out.println(MyUtils.sendMsgNoUrl(re,MsgToken,"今日任务执行失败,请手动调用接口重新爬取!"));
return;
}
}
// 2.解析入口页面,获取项目列表
List<ProjectDTO> projects = crawlerService.parseProjectList(html);
//发送成功消息
log.info("抓取页面完成,开始解析!");
JSONObject re = new JSONObject();
re.put("时间:", MyUtils.nowTime());
re.put("本次重试次数:", count);
re.put("本次项目总数:", projects.size());
//微信推送执行结果消息
System.out.println(MyUtils.sendMsgNoUrl(re,MsgToken,"任务执行成功,请去查看效果!"));
if (CollectionUtils.isEmpty(projects)) {
return;
}
// 3.遍历项目列表,利用线程池实现多线程
// executorService提交任务:1)submit 有返回结果 2)execute 无返回结果
// 此处使用submit是为了得知是否全部遍历结束,方便进行存到数据库操作
ExecutorService executorService = Executors.newFixedThreadPool(10); //固定大小10的线程池
List<Future<?>> taskResults = new ArrayList<>();
// for (int i = 0; i < 10; i++) {
for (int i = 0; i < projects.size(); i++) {
ProjectDTO project = projects.get(i);
Future<?> taskResult = executorService.submit(new Runnable() {
@Override
public void run() {
try {
System.out.println("crawling " + project.getName() + ".....");
String repoName = getRepoName(project.getUrl());
String jsonString = crawlerService.getRepo(repoName);
// 解析项目数据
parseRepoInfo(jsonString, project);
System.out.println("crawling " + project.getName() + "done !");
} catch (Exception e) {
e.printStackTrace();
}
}
});
taskResults.add(taskResult);
}
// 等待所有任务执行结束,再进行下一步
for (Future<?> taskResult : taskResults) {
try {
// 调用get会阻塞,直到该任务执行完毕,才会返回
if (taskResult != null) taskResult.get();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
//代码到这里,说明所有任务都执行结束,结束线程池
executorService.shutdown();
// 4.保存到数据库
crawlerService.batchSave(projects);
}
4、前端调用接口开发
对前端开放两个接口,一个为数据库数据的日期列表接口,一个根据日期查询当日数据接口,同时对参数进行非空验证
java"> @GetMapping("/list")
public JSONObject verifySign(@RequestParam("time") String time) {
JSONObject resp = new JSONObject();
if(StringUtils.isEmpty(time) || time.equals("null")){
resp.put("code",400);
resp.put("data",null);
resp.put("msg","time 参数错误!");
return resp;
}
resp.put("code",200);
resp.put("msg","请求成功");
resp.put("data",crawlerService.getListByTime(time));
return resp;
}
@GetMapping("/timeList")
public JSONObject timeList() {
JSONObject resp = new JSONObject();
resp.put("code",200);
resp.put("msg","请求成功");
resp.put("data",crawlerService.timeList());
return resp;
}
在根据日期查询当日数据的接口中,因其每日的数据都是固定的,因此添加redis缓存,提高性能
java"> String redisKey = "crawler_"+time;
boolean containsKey = redisUtils.containThisKey(redisKey);
if(containsKey){
String value = redisUtils.get(redisKey);
return JSONObject.parseArray(value,ProjectDTO.class);
}
List<ProjectDTO> list = crawlerMapper.getListByTime(time);
redisUtils.set(redisKey,JSONObject.toJSONString(list));
return list;
其中redisUtils为自己写的Redis工具类,具体代码如下:
java">package com.simon.utils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
import java.util.concurrent.TimeUnit;
@Component
public class RedisUtils {
@Autowired
public StringRedisTemplate redisTemplate;
public String get(String key){
if(StringUtils.isEmpty(key)){
return null;
}
return redisTemplate.opsForValue().get(key);
}
public boolean set(String key,String value){
if(StringUtils.isEmpty(key) || StringUtils.isEmpty(value)){
return false;
}
redisTemplate.opsForValue().set(key,value);
return true;
}
public boolean setTimeOut(String key,String value,Long timeOut){
if(StringUtils.isEmpty(key) || StringUtils.isEmpty(value)){
return false;
}
redisTemplate.opsForValue().set(key,value,timeOut, TimeUnit.SECONDS);
return true;
}
public boolean delete(String key){
if(StringUtils.isEmpty(key) ){
return false;
}
Boolean isDelete = redisTemplate.delete(key);
return isDelete != null ? isDelete : false;
}
public boolean containThisKey(String key){
if(StringUtils.isEmpty(key) ){
return false;
}
Boolean hasKey = redisTemplate.hasKey(key);
return hasKey != null && hasKey;
}
}
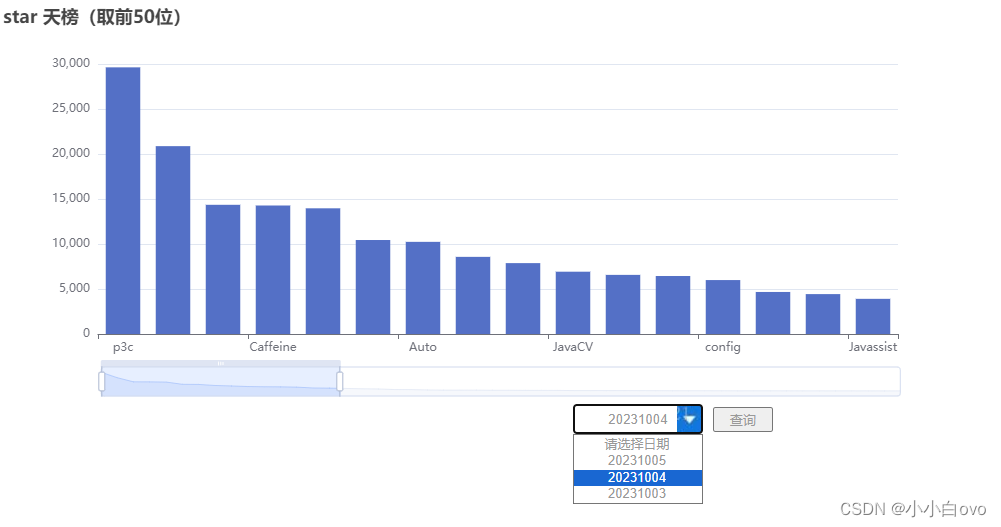
因作者对前端不太熟练,只是实现了一些简单的数据处理逻辑,前端效果展示: