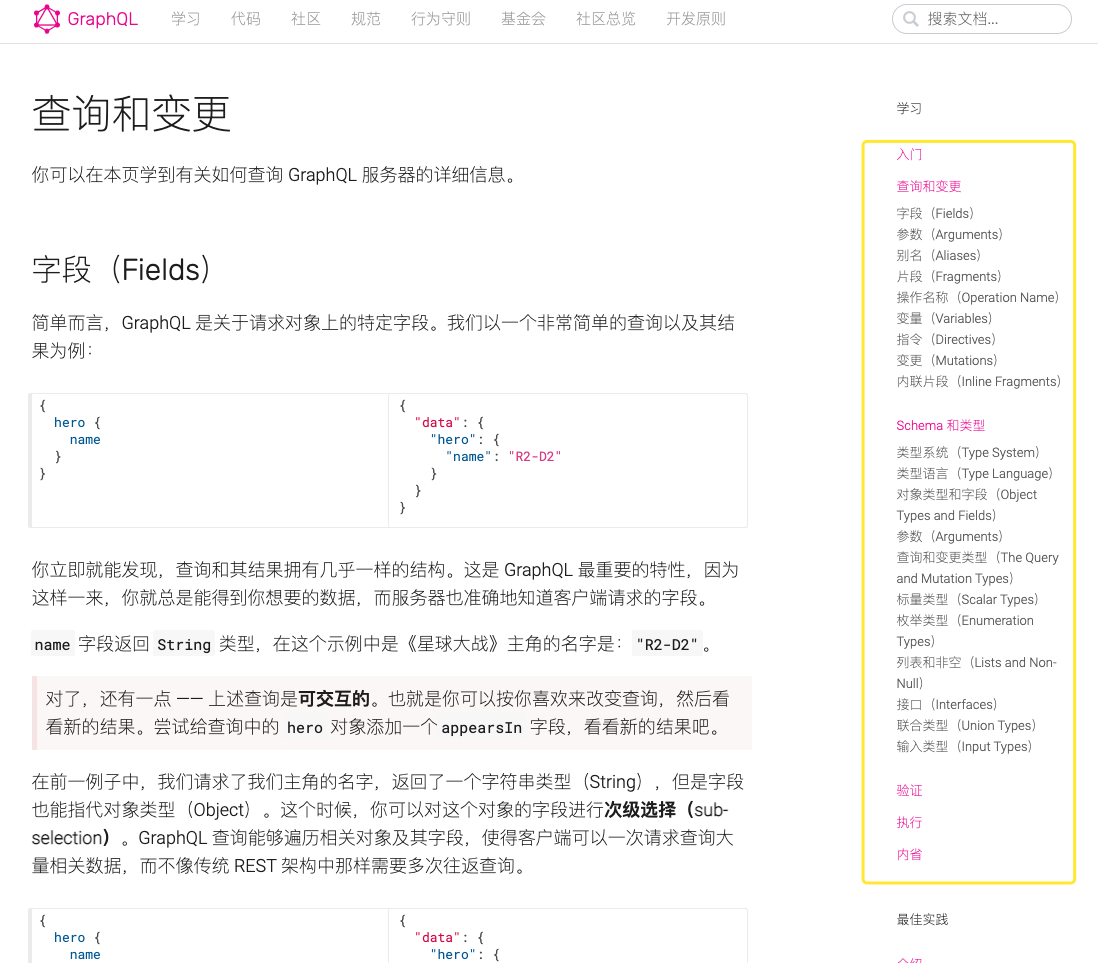
目录
前言
一、什么是爬虫代理 IP
二、代理 IP 的分类
1.透明代理
2.匿名代理
3.高匿代理
三、如何获取代理 IP
1.免费代理网站
2.付费代理服务
四、如何使用代理 IP
1.使用 requests 库
2.使用 scrapy 库
五、代理 IP 的注意事项
1.代理 IP 可能存在不稳定性
2.代理 IP 可能存在安全问题
3.代理 IP 可能存在限制
六、代理 IP 的实例应用
总结
前言
在进行爬虫程序开发时,经常会遇到访问被限制的网站,这时就需要使用代理 IP 来进行访问。本文将介绍代理 IP 的概念及使用方法,帮助读者更好地应对爬虫程序中的访问限制问题。同时,本文还将提供一些代理 IP 提供商,并通过一个实例演示如何使用代理 IP 来访问被限制的网站。

一、什么是爬虫代理 IP
在爬取数据的过程中,我们会遇到一些网站对爬虫有限制,比如 IP 封杀、请求频率限制等等。这些限制会导致我们无法顺利地爬取数据,从而影响我们的工作。
为了解决这些限制,我们可以使用爬虫代理 IP。所谓爬虫代理 IP,就是代理服务器上的 IP 地址,我们可以通过代理服务器来访问目标网站,从而达到隐藏真实 IP 地址、增加请求频率等作用。
二、代理 IP 的分类
在使用代理 IP 之前,我们需要了解一些代理 IP 的基础知识。代理 IP 可以分为以下三种:
1.透明代理
透明代理是一种最基础的代理方式,它对于我们的真实 IP 地址没有任何保护作用,也不会影响我们的请求频率。请求通过透明代理服务器后,目标网站可以直接获取到我们的真实 IP 地址。
2.匿名代理
匿名代理会隐藏我们的真实 IP 地址,但是请求频率仍然受到目标网站的限制。请求通过匿名代理服务器后,目标网站只能获取到代理服务器的 IP 地址,无法获取到我们的真实 IP 地址。
3.高匿代理
高匿代理是一种最安全的代理方式,它不仅会隐藏我们的真实 IP 地址,还可以伪装请求头,使得目标网站无法判断我们的请求是否为代理请求。请求通过高匿代理服务器后,目标网站只能获取到代理服务器的 IP 地址,并且无法判断请求是否为代理请求。
三、如何获取代理 IP
1.免费代理网站
我们可以通过一些免费的代理网站来获取代理 IP。这些代理网站通常会提供一份代理 IP 列表,我们只需要从列表中选择一个可用的代理 IP,然后将其作为参数传递给我们的爬虫程序即可。
例如,我们可以使用以下代码从代理网站 https://www.zdaye.com/nn/ 中获取免费的代理 IP 列表:
python">import requests
from lxml import etree
url = 'https://www.zdaye.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
ips = html.xpath('//table[@id="ip_list"]/tr[position()>1]')
for ip in ips:
ip_address = ip.xpath('./td[2]/text()')[0]
ip_port = ip.xpath('./td[3]/text()')[0]
print(ip_address + ':' + ip_port)2.付费代理服务
除了免费代理网站外,我们还可以通过一些付费代理服务来获取高质量的代理 IP。这些付费代理服务通常会提供一些 API 接口,我们只需要调用接口即可获取代理 IP。
例如,我们可以使用以下代码从付费代理服务 https://www.zdaye.com/ 中获取代理 IP:
python">import requests
url = 'https://www.zdaye.com/'
response = requests.get(url)
ip_address = response.json()[0]['ip']
ip_port = response.json()[0]['port']
print(ip_address + ':' + ip_port)四、如何使用代理 IP
在获取到代理 IP 后,我们需要将其应用到我们的爬虫程序中。下面,我们来介绍两种常见的代理 IP 使用方式。
1.使用 requests 库
我们可以使用 requests 库的 proxies 参数来设置代理 IP,并将其传递给 requests.get 函数。例如,我们可以使用以下代码来设置代理 IP:
python">import requests
url = 'https://www.baidu.com'
proxies = {'http': 'http://10.10.1.10:3128', 'https': 'http://10.10.1.10:1080'}
response = requests.get(url, proxies=proxies)
print(response.text)2.使用 scrapy 库
我们可以使用 scrapy 库的 Request.meta 参数来设置代理 IP,并将其传递给 scrapy.Request 函数。例如,我们可以使用以下代码来设置代理 IP:
python">import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['https://www.baidu.com']
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url, meta={'proxy': 'http://10.10.1.10:3128'})
def parse(self, response):
print(response.text)五、代理 IP 的注意事项
1.代理 IP 可能存在不稳定性
由于代理 IP 是通过网络连接到远程服务器的,因此可能会存在网络不稳定的情况。在使用代理 IP 的过程中,我们需要注意监测代理 IP 是否正常工作,如果出现问题需要及时更换代理 IP。
2.代理 IP 可能存在安全问题
由于代理服务器上可能存在恶意程序,因此使用代理 IP 的过程中可能会存在一定的安全风险。在使用代理 IP 的过程中,我们需要注意保护自己的计算机安全。
3.代理 IP 可能存在限制
有些代理 IP 可能会对请求频率、请求内容等进行限制,我们需要在使用代理 IP 的过程中遵守代理 IP 的使用规则,不要进行过度请求或者非法操作。
六、代理 IP 的实例应用
下面,我们以使用代理 IP 访问百度搜索结果为例,来演示代理 IP 的实际应用。我们首先需要获取一个可用的代理 IP,然后使用代理 IP 来访问百度搜索结果,最后将搜索结果保存到本地文件中。
python">import requests
from lxml import etree
# 获取代理 IP
url = 'https: 'https://www.zdaye.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
ips = html.xpath('//table[@id="ip_list"]/tr[position()>1]')
ip_address = ips[0].xpath('./td[2]/text()')[0]
ip_port = ips[0].xpath('./td[3]/text()')[0]
proxies = {'http': 'http://' + ip_address + ':' + ip_port, 'https': 'http://' + ip_address + ':' + ip_port}
# 使用代理 IP 访问百度搜索结果
keyword = 'Python 爬虫'
url = 'https://www.baidu.com/s?wd=' + keyword
response = requests.get(url, proxies=proxies)
html = etree.HTML(response.text)
search_results = html.xpath('//div[@id="content_left"]/div[@class="result"]')
for result in search_results:
title = result.xpath('.//h3/a/text()')[0]
link = result.xpath('.//h3/a/@href')[0]
abstract = result.xpath('.//div[@class="c-abstract"]/text()')[0]
print(title)
print(link)
print(abstract)
# 将搜索结果保存到本地文件中
filename = 'search_results.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(response.text)通过以上代码的演示,我们可以看到代理 IP 在实际应用中的重要性,以及如何使用代理 IP 来访问被限制的网站。
总结
本文介绍了什么是爬虫代理 IP,以及代理 IP 的分类和获取方法。同时,本文还介绍了代理 IP 在爬虫应用中的使用方式,并提醒了使用代理 IP 需要注意的注意事项。最后,本文通过一个实例演示了如何使用代理 IP 来访问被限制的网站。通过本文的介绍,相信读者可以更好地理解代理 IP 的概念,并掌握代理 IP 的应用技巧。
总体而言,代理 IP 的应用范围非常广泛,尤其在爬虫领域中,代理 IP 的使用更是不可或缺。在实际使用过程中,我们需要选择可靠的代理 IP ,并合理使用代理 IP,以确保我们的爬虫程序能够正常运行。