文章目录
1、任务描述
2、获取网页源码、解析、保存数据 3、结果展示
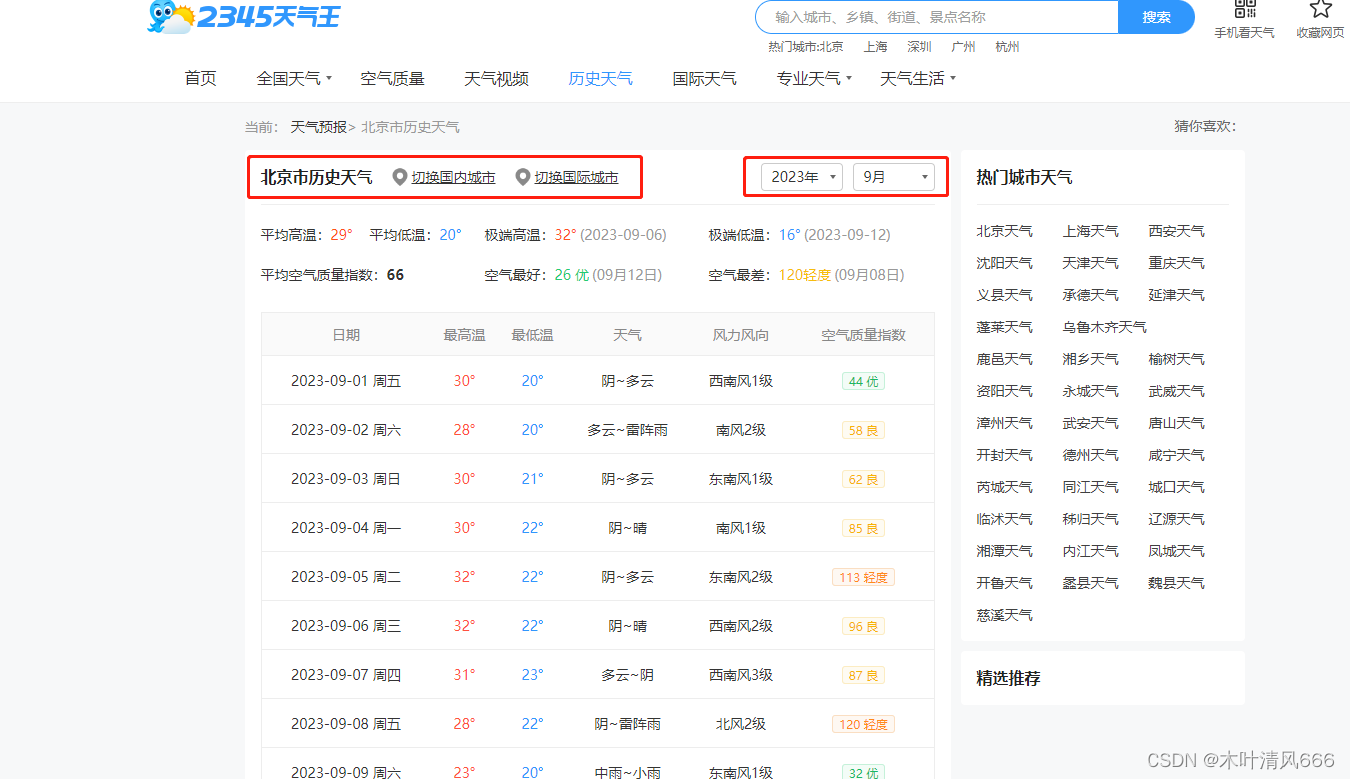
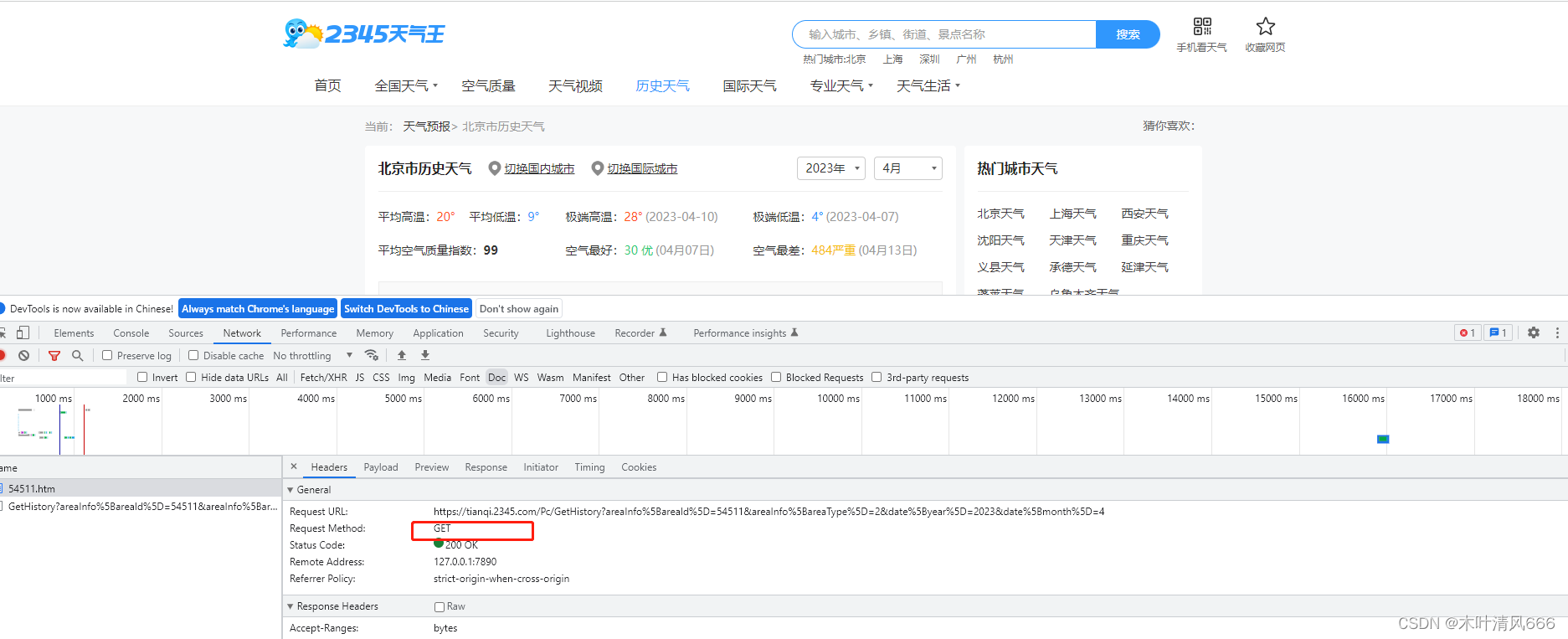
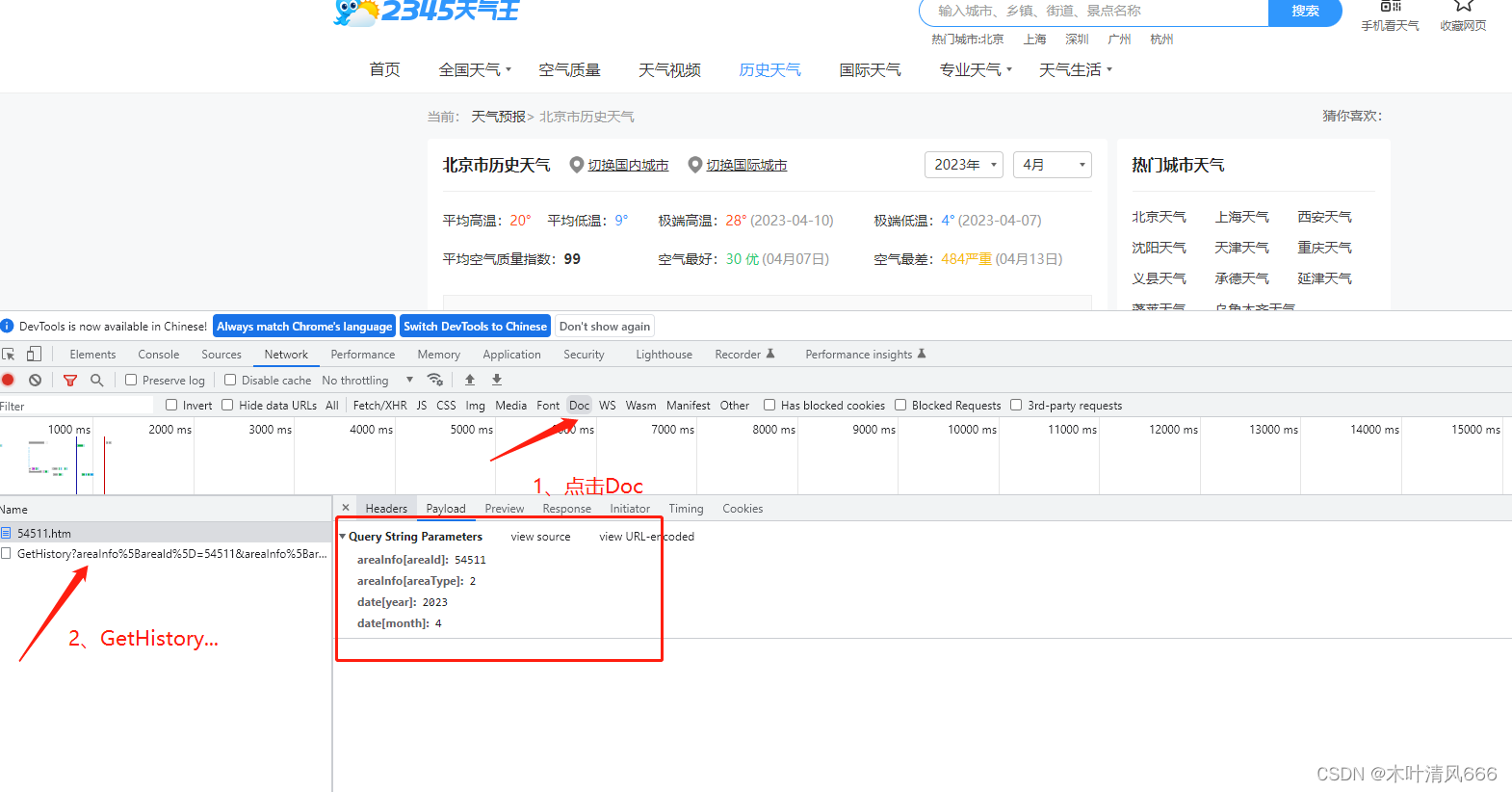
在2345天气信息网2345天气网 依据地点 和时间 对相关城市的历史天气信息进行爬取。网页使用get方式发送请求,所需参数包括areaInfo[areaId]、areaInfo[areaType]、date[year]、date[month],分别为城市id、城市类型,年、月。 python">import pandas as pd
import requests
from bs4 import BeautifulSoup
url = "https://tianqi.2345.com/Pc/GetHistory"
def crawl_html ( year, month) :
"""依据年月爬取对应的数据"""
params = { 'areaInfo[areaId]' : 54511 ,
'areaInfo[areaType]' : 2 ,
'date[year]' : year,
'date[month]' : month}
headers = { 'User-Agent' : '''Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36''' }
response = requests. get( url, headers= headers, params= params)
data = response. json( ) [ "data" ]
df = pd. read_html( data) [ 0 ]
return df
df_list = [ ]
for year in range ( 2015 , 2023 ) :
for month in range ( 1 , 13 ) :
print ( "爬取:%d年 %d月" % ( year, month) )
df = crawl_html( year, month)
df_list. append( df)
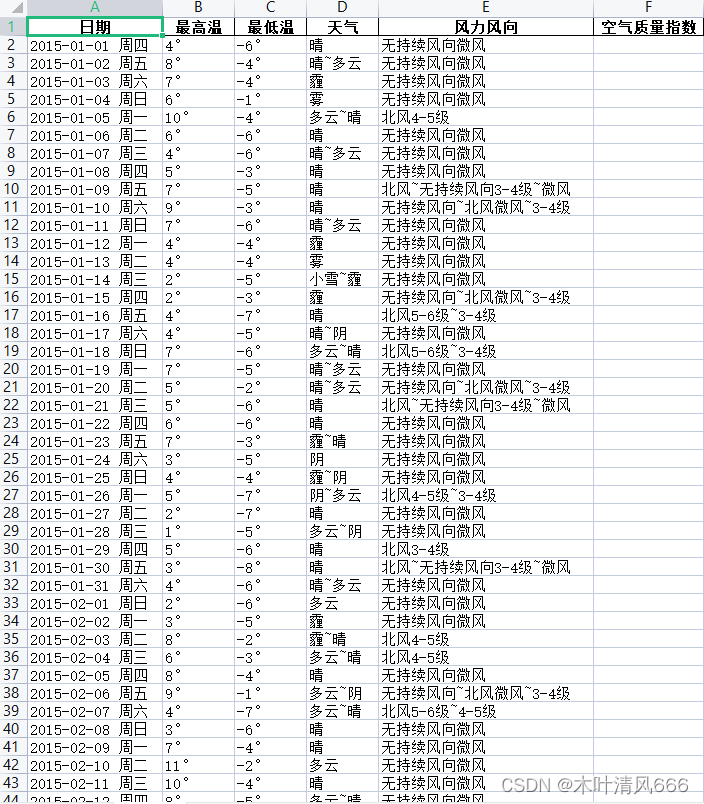
pd. concat( df_list) . to_excel( "practice04_BeijingWeather.xlsx" , index= False )